I’m having a slow down when copying files. I’m moving off of XFS disks I’ve placed in the Truenas scale server and on to the local Zpool.
I see 190MB/s copies (probably max of the single disk I’m reading off of) and it’ll do that speed for about 30 seconds and then tank to 5MB/s. Then about 2-3 minutes later its back up at 190MB/s or sometimes down around 100MB/s then tanks again to 5MB/s after only 20-30 seconds or so.
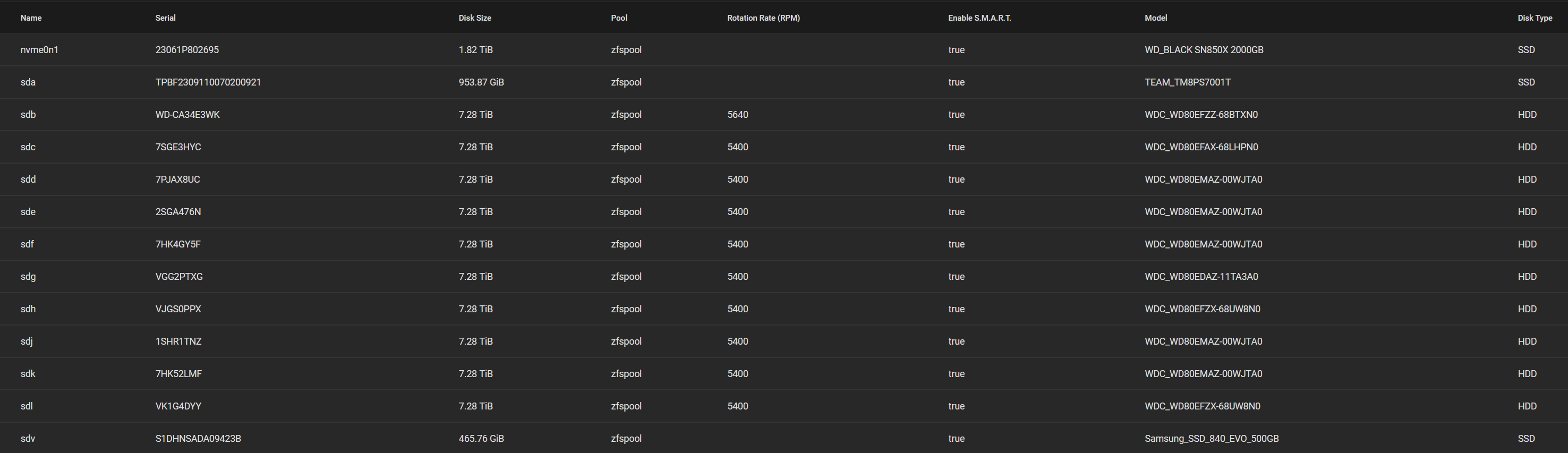
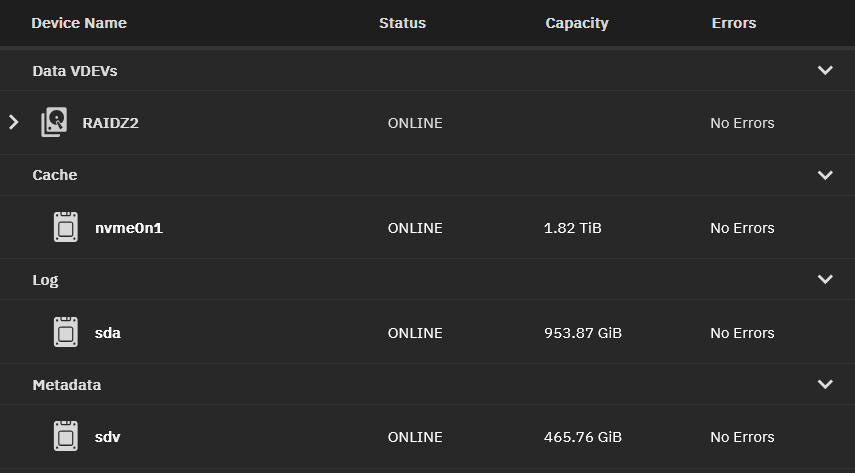
Here is my layout (yes, i did 13, bad me, next one wont go past 12):
It seems like you have a drive blocking i/o and it is getting stuck waiting. Maybe check the GUI reports on disks and see if you see anything bottlenecking
Have you checked the SMART data for the HDDs?
Also checking if your have L2ARC and/or SLOG (write cache)
If I am following the data you have posted above, you seem to have a lot of possibly mismatched devices. Boot pool is two different series of Samsung SSD? Z1 pool has HDDs with different cache internally, 128 & 258Mb models. I just checked a few
Yes I have another set ssds that will be added. I’d love a set of recommendations for cache, mostly what I’ve read is “give zfs all the ram and all the SSDs and have lots of vdev pools and mirrors, etc”. I’m doing what I can afford here, I hope it’ll be enough. I can certainly add more RAM and I have 2450 V2 xeons on their way so I can add 64GB DIMMS and the Mobo will support up to 1TB of RAM (may not go all that way, maybe 512GB).
Disk Models are:
WD80EDAZ
WD80EFAX
WD80EFZX
WD80EFZZ
WD80EMAZ
WD80EDAZ
Type: HDD (Hard Disk Drive)
Capacity: 8TB
Cache: 256MB
RPM: 5400 RPM
Spindle Count: 1
Throughput: Up to 175 MB/s
WD80EFAX
Type: HDD (Hard Disk Drive)
Capacity: 8TB
Cache: 256MB
RPM: 5400 RPM
Spindle Count: 1
Throughput: Up to 175 MB/s
WD80EFZX
Type: HDD (Hard Disk Drive)
Capacity: 8TB
Cache: 256MB
RPM: 7200 RPM
Spindle Count: 1
Throughput: Up to 200 MB/s
WD80EFZZ
Type: HDD (Hard Disk Drive)
Capacity: 8TB
Cache: 256MB
RPM: 7200 RPM
Spindle Count: 1
Throughput: Up to 205 MB/s
WD80EMAZ
Type: HDD (Hard Disk Drive)
Capacity: 8TB
Cache: 256MB
RPM: 5400 RPM
Spindle Count: 1
Throughput: Up to 175 MB/s
Summary
Capacity: All models are 8TB.
Cache: All models have 256MB.
RPM: WD80EFZX and WD80EFZZ have 7200 RPM; WD80EDAZ, WD80EFAX, and WD80EMAZ have 5400 RPM.
Throughput: Ranges from 175 MB/s to 205 MB/s depending on the model.
I tried to add a performance tag but it doesn’t appear at the top of the forum. Maybe you can add it?
I think you should be fine with just your basic Z2 pool and then researching and adding ‘special devices’ if necessary. Some will kill the entire pool upon failure, others are recommended to be mirrored. L2ARC device could die and the pool will still work. Just checking, you don’t have de duplication turned on? That’s another very special use option.
I’ll point you to the ZFS Primer.
Look at the info for SLOG. Says it uses 16GiB of space and also points to drive models with power protection.
DEDUP.
That should be the problem child. Do a search on the forums and you can see when it really should be used. I don’t know if you have to rebuild your pool from scratch when you turn it off. You will have to check the documentation and forums for advice.
Lots of good information here. A few minor points:
The recommendation to stick to 12 drives or less in a RAIDZ vDev is based only on the data drives and you have only 10.
I am unclear why some drives have a device name sd* and others have a uuid? The reason for UUIDs is that they are independent of the position of the drive in the hardware, whereas sd* can change between reboots. I have no idea whether this is a big problem or not, nor how to fix it.
IMO you should NOT have an unmirrored metadata special vDev - if you lose this you WILL lose the entire pool so it is more important than anything else to ensure that it has good redundancy. However if you configure the L2ARC correctly, it will cache all the metadata anyway, so it is probably redundant. I don’t know whether it is possible to remove the metadata vDev without rebuilding the pool but IMO you have to do something about this ASAP.
I am not sure just how useful the SLOG will be - it depends on your workload but it only helps with synchronous writes, and e.g. Windows SMB usage is always asynchronous. Asynchronous writes are generally going to appear faster from the network client because no write to either SDD or HDD is needed before the client sees it as complete, and the more memory you have the more asynchronous writes can be queued up in memory awaiting disk write capacity to be written out. Of course, any asynchronous writes still in memory will be lost on a crash or power outage, so you have to evaluate this risk. If you are using synchronous writes, you similarly need to evaluate the risks of losing what is stored on the SLOG and not yet committed to HDD in the event that the SLOG SSD dies, and decide whether it needs to be mirrored.
If you have a large L2ARC anyway, a metadata vDev probably won’t speed up your reads significantly though it might allow a slightly higher volume of writes. But if you have it then it must be mirrored - and IMO a 3x mirror because of its importance.
If write volumes are not of concern, then having a metadata vdev just adds complexity and additional points of failure for your pool. So my advice (as a non-expert) would be to remove the metadata vDev if you can and rely on L2ARC to speed up the metadata access for reads.
I’ve done a 2x mirror on the metadata now (just finished resilvering).
I can add a 4TB l2arc (QLC unfortunately) if it will matter. I just really want the disks to handle the writes. I get its a COW filesystem but I also would like to not be bottlenecked by the dirtydata_max of 4GB. That appears to be the case best I can tell. That should be how that works right? B/c dirtydata_max_max is also 4GB so you cant really change it.
Start out with a regular Z2 pool setup. Start learning the performance from that. If there are problems then come back to the forum and post a new thread with you entire setup described and what you are doing. You just seem to be trying to use all the ZFS features without understanding when and how to use them.
I haven’t seen anything but guesses on why the performance would be slow. I am not randomly trying out features, I’m trying to allow others to provide examples of their performance characteristics.
The near constant advisories to not use dedup leads me to believe it is misunderstood by the community in general. ZFS was designed with this feature and compression in mind. It is a solid feature. ZFS doesn’t belong on a small system, as noted by Oracle’s own ZFS arrays being absolute monsters (I’ve managed them myself).
I’ll figure out what the issue is and post a how to. Maybe it will benefit someone.
The advisories against dedup is from experiences on forums and iX Systems. I linked to the old forums but there may be something in the current Resources section or the guides on the old forum.
Deduplication has been identified as a likely culprit here; while you do have a special vdev, it’s only a single (which was now changed to a mirror) disk - and the 840 EVO may not be particularly suited to the task.
The raidz2 is “only” 10-wide, and that’s what we look at, so it is not TOO wide.
But it is intriguiging that three drives are shown by partition rather than GPTID, as should be the case.
And you have a binking red alert with this pool: Single drive special vdev!
Never ever do that! If this single drive dies your pool is lost. Add at least one other drive, and preferably two to extend this special vdev into a 2-way or 3-way mirror.
It is not apparent whether you actually have a use for SLOG. But you do not have enough RAM for a 2 TB L2ARC… and this could even be part of your problem.
The good point here is you can remove SLOG and/or L2ARC.
BINGO!
9% is absolutely ridiculous for this ressource hog, and it’s straining the single drive special vdev for good measure.
Unless you’re willing to backup and destroy your pool to rebuild sanely, you should:
FIRST AND FOREMOST extend this special vdev!
For each datset which has dedup enabled, create a new dataset without dedup…
… set up a one-off LOCAL replication task from the deduped dataset to the new one; uncheck “Include dataset properties” and “(Almost) Full Filesystem Replication” (set manually any other non-default property you want, you may also crank up compression if your dataset may benefit from it); and run…
…check that your data has safely moved into the new deduplicated dataset, remove the “read-only” property and make the new dataset into the new share…
… and delete the old deduped datset.
Disable dedup at pool level.
(If dedup is on the entire pool, you do not have enough RAM to handle it, far from that. The system should still cope with it thanks to EITHER a special/dedup vdev or a persistent L2ARC, not both at the same time, but your current special vdev is a major liability—and you cannot remove it. For 9%, just get rid of dedup entirely.)
Sure, we’re all morons but you’re the sole genius which will save us all from the deep darkness of Misunderstanding…
Take it from my personal experience with a little dedup’ed dataset (16 TB quota, 10 TB used): Just scrubbing, that is READ only, a mere 10 TB of deduped data would bring a system with 64 GB RAM to its knees.
Dedup is a solid feature… for enterprise systems sized with over $10k of RAM. Home-labbers are not invited.