In past week I have updated from TrueNAS Scale 22 to 24 by reinstalling the system and reimporting pools. This is big event for me, because I’m used to these things running for years at a time without any serious maintenance required and moving from Core to Scale has been anything but smooth. V25 was ruled out immediately, since it’s basically half-baked pre-alpha. I got lost in all the weird codenames, they use them in some places and not use them in other places and change them out mid-version, so I just refer to version numbers:
- The networking setup is still hilariously broken, this has been the case for at least 4 years as far as I can remember. In order to create a bridge used by VMs so they can see the host, the bridge has to be created in console menu on the host using the tty menu, and even then it still won’t work until restart. You just have to know this, but we all do, so it’s fine.
- The use of netdata for reporting is stroke of genius, this is really done well and I started using it immediately.
- The replication job wizard is still cryptic. On first run it’s able to create snapshots, on repetitive runs it isn’t, even if no snapshot and destination dataset exists. Still no useful explanation on cryptic checkboxes like “Encryption” or rather weird implementation of several options for complete replication of a dataset. I found editing existing replication task almost never works, so instead I have adopted a procedure where I go through the wizard really slow and I triple check everything before firing it off. When it eventually does start sending data, it’s pretty neat, exactly what I came to love on TrueNAS. Really good tech in moving data around. The dialog that tells you how much it has sent and how much is remaining still shows nonsense numbers, but that has not changed from v22.
- It picked up v22 pools immediately, there was no compatibility issue.
- IPMITOOL in version baked into 24 works well with my X11 boards, so fan management script for after-start worked well without needing to do anything extra. It would’ve been nice to see some GUI innovation that would allow me to manage fans without having to resort to using terminal but not necessary.
- APC Back-UPS units still report low battery state every few minutes using the correct driver, this is solved by adding ‘ignorelb’ argument into 'Auxiliary Parameters (ups.conf)` textbox of the ups service configuration editor.
- If you disable administrative access without login on the host screen, the tty menu will not load even after you log in and you have to know to recall it by typing
/usr/bin/cli --menuso it’s good to do it during setup and then when you log in at later date you can just recall it by hitting arrow up key as one of last used commands. - As usual, if you use http to https login screen redirect, it means you won’t be able to push data to the machine, because other TrueNAS instances will flag the self-signed https certificate and refuse to connect to it. So, by design, out of box TrueNAS boxes will not support connecting to each other using https. This has been like this forever, so again, nothing new.
- Chelsio 10G cards work great with both v22 and v24 so moving data was a breeze. They work out of box, no need to set them up in any way except setting IP addresses in the broken networking UI. Again, even if you have your web UI running through different NIC, setting IP on an unused auxiliary Chelsio card will still break your access to the web UI, so I recommed doing this while you’re on-site, from host terminal, and doing a reboot after that. The settings will appear not to have taken place and web UI will stop working, until you restart. It’s the Windows way.
- Virtualization works the same on both too, I encountered no new issues there. VirtIO drivers work.
- In V24 it is still the case that if pool gets 100% full, it’s cooked and you can’t even remove data to un-cook it. The only way around it is attaching another vdev to the pool and then removing it. This is ZFS “feature,” I’m not sure if TrueNAS could get around it, but I’d still expect it to, somehow. For now, the quotas and notifications have to do.
- Snapshot jobs and snapshot overview works the same, although the screen is quite cryptic, the numbers of data referenced, space used never adds up to what is seen in datasets overview. I can have a dataset that shows 300 GiBs used space, and I will have 250 GiB of data on it, with 3 snapshots, each reporting 1.5 GiB used space and around 250 GiB of data referenced. It never made any sense, and I learned to oversize my storage requirements by quite a large margin to never ever hit any size quota or limit. I consider any numbers that TrueNAS throws at me as unreliable for this reason.
- I found ChatGPT being very helpful in explaining how different things work in TrueNAS, because it seems to be also aware of the bugs and problems in it, and seems to be able to navigate around them, or at least point in the right direction.
Overall v24 is nice, the new storage dashboard seems pretty but pointless, the new dataset overview is fine although it shows more errors now. If you move data around, create and delete datasets, eventually you’ll start getting “error retrieving user quota” and other random errors by simply clicking on a dataset without trying to do anything. It gives a stack trace and so I went to the source code, it seems to be related to permissions. If you move in datasets from other systems that have permissions/ACLs set for user that do not exist on this system, it will just start throwing these non descriptive errors. Again something that I would really expect to see wrapped in a more descriptive error message, and not as a dialog one, since it clearly comes from one of the tiles on the screen trying to populate itself with data, the tile should just say it wasn’t able to do that, why and how to rectify this, instead of disturbing me with unignorable dialog with unintuitive message.
I’ll be running with this for at least another 3 years. Some of the boxes have VMs running on raidz2 pools of bifurcated NVME host cards for SQL storage so we expect some failures to occur regularly and I’m curious if any improvement has been done on the ability to identify failed drives, which v22 notoriously didn’t have, frustrating many.
That’s all, thanks.
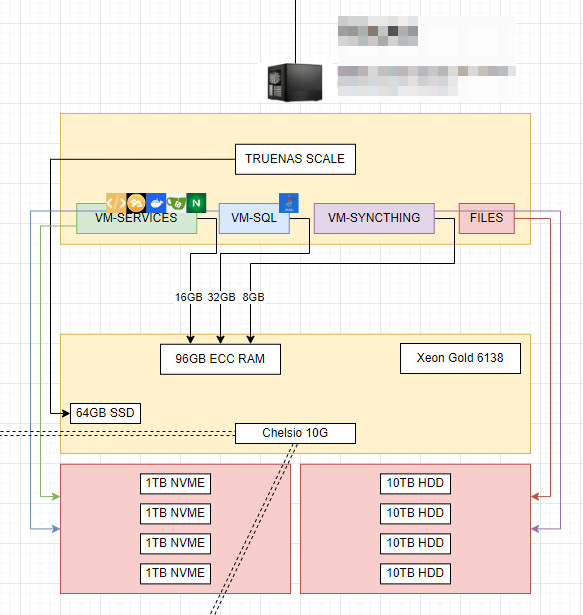
EDIT: For my future reference, this is what I use as typical build for smallish shops and my office as well, so if anyone needs to build it, here is parts list and diagram, this is like super-reliable build for me that has worked for years with dozens of people relying on it every day. The server usually sits on an IKEA cart on wheels with whole networking rack, UPS and possibly a backup nas unit sitting next to it as well, but those are not part of the documentation. Yes it’s ghetto compared to gucci server builds but it works for me.