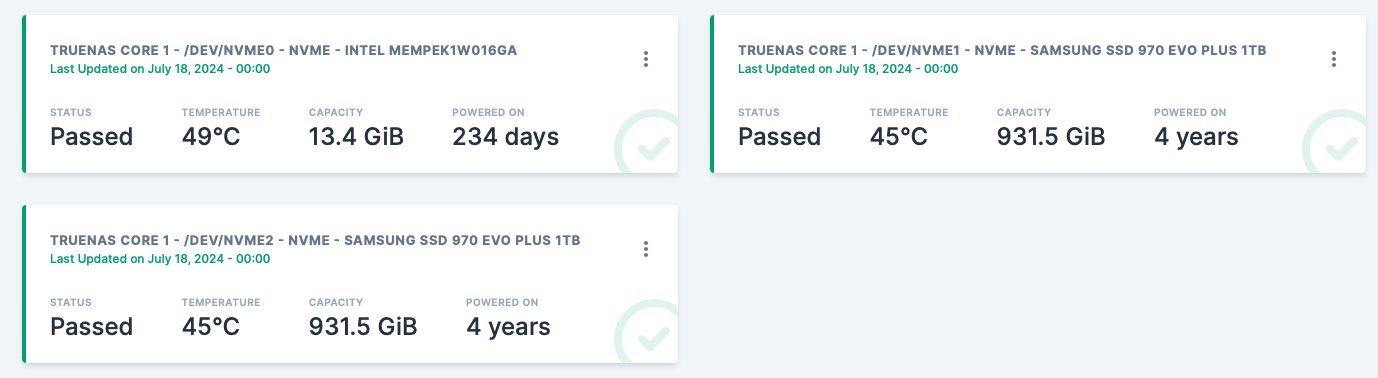
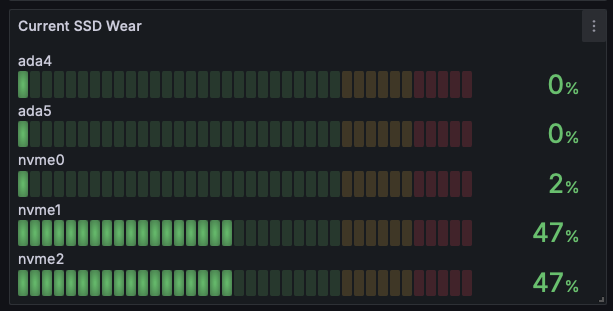
At present time neither TrueNAS SCALE nor CORE GUI’s support configuring SMART Self-test (short or long) for NVMe drives.
To be honest in my opinion this shouldn’t be a feature request, it should be a bug fix, but I don’t see this issue gaining any ground.
NVMe drives are becoming more popular and affordable and while they may not be something used in a data center due to lower capacity and higher cost, us home users do use NVMe drives.
While I’m glad that I can fill the gaps with the little script I maintain, the correct long term fix is for TrueNAS to incorporate it into the GUI. They have smartmontool 7.4 now (not that they really needed it) so I don’t understand why it hasn’t been incorporated already.
I watch all my drives with SMART and Scrutiny as well as a Grafana dashboard that shows the expected remaining life time according to vendor specs and SMART values.
I also expect TrueNAS to be able to schedule regular SMART tests for all drives in the system.
Whenever a user shows up with a “help, my pool failed” thread, the first answer is most of the time “run a long selftest on the disk drives”.
You are asking to prove a negative. That is not fair. The question should be “How many times has SMART identified problems before complete failure in an SSD.” After all, SSD=NVMe, just a slightly different interface technology.
Let me ask this question: Would iXsystems include SMART testing if they sold full NVMe solutions? What would the customer want?
To @pmh point, we do ask for SMART statistics when someone is having problems and this data can help diagnose a problem before or after a failure. We often find that a person with a serious failure had never performed routine SMART testing and when TrueNAS sends them an email, it is sometimes utter disaster, while someone that did perform routine testing would find issues before complete failure. This isn’t always the case of course however it is very common. The forums are riddled with this (the old one and current one).
SMART is an extra level of testing and notification. I would have to say that more people would want it than not, and even for NVMe (SSD) drives.
Lastly, SCALE has smartmontools v7.4 and CORE 13.3(Beta) does as well. It can’t be that much effort to add a few lines of code to also schedule SMART testing for “nvme0” (SCALE) or “nvd0” (CORE).
@pmh I will try out Scrutiny, looks interesting. That won’t get me to stop working my little script but it exposes me to other options I could recommend to people. And if iXsystems is not going to include NVMe testing, I could make a significantly smaller script to just run NVMe tests should that be what someone wants vice the whole Multi-Report script.
I’m sure I can dig up a few examples of the SMART data being a useful predictor of pending failure, but it may not be immediate failure.
I agree, Wear Level and Bad Blocks are both great pieces of data to determine the end of life, and I would expect the end user would rather find out sooner than later.
There was a reason SMART became part of the NVMe 1.4 standard. I don’t honestly know that reason and if I find out, I’ll include it here. Maybe it was to find out wear levels and temperatures (NVMe drives can get pretty hot).
Anyway, it is only a feature request. I will not lose much sleep over if it is not included in the GUI as I can and do test mine every day for peace of mind and looking for any trends.
In the past, I did not bother with SMART on my Linux desktop’s 2 NVMe. I don’t recall SMART working with NVMes. However, I did have an early failure, pretty annoying, so I made sure I bought a different brand. (They are in a ZFS Mirror… so no real problem.)
Today, checking, I can see a pre-failure indicator. (The desktop has been up 5 years…) Here is the relevant parts from the 2 drives. The first one is the original, and may be lying about it’s spares. The second is the replacement for the early failure.
root:~# smartctl -x /dev/nvme0 | egrep "Model|Spare|Percent|Power On"
Model Number: HP SSD EX950 512GB
Available Spare: 100%
Available Spare Threshold: 10%
Percentage Used: 16%
Power On Hours: 43,436
root:~# smartctl -x /dev/nvme1 | egrep "Model|Spare|Percent|Power On"
Model Number: Lexar SSD
Available Spare: 83%
Available Spare Threshold: 10%
Percentage Used: 4%
Power On Hours: 41,692
It is fair to question how useful SMART really is, for NVMe or even in general.
But on the other hand, how much ressources would it take to update SMART-related packages and allow the middleware to monitor nme/nvd devices the way it already does for ada/da/sd devices?
Lets not trivialize the process or work involved. Each feature requires:
development of additional software
Validation of that software (with appropriate range of hardware)
Integration with TrueNAS - middleware and UI
in the case of NVMe, its potentially different data to collect and display
QA of TrueNAS - across range of systems
Development of ongoing QA tests for future releases
Support and bug fixing of the new software
All of this adds up to a reasonable cost.
There are literally thousands of features we can add to TrueNAS, so we have to prioritize allocation of staff to specific projects. We base prioritization on cost-benefit. So we do ask for what the benefit is. Is it saving data, time, money and for how many systems? For our commercial users, we can assess the benefits easily. They can make it a requirement of their next purchase.
We run TrueNAS as an Open Source project. If it’s worth someone’s time to contribute the validated software, that’s a good indication of the benefit seen. If users have horror stories of time wasted or data almost lost… we’d like to hear them.
So these new “Feature Request” pages are really requests for helping prioritize. Provide code or share your stories. We can’t prioritize “advice” only “problems & solutions”
Love the contribution of Scrutiny as a temporary solution. If people see real benefits there, that’s a great sign of needing to integrate better.
Below is a good, fairly recent article from a very trusted resource that explains the current state of the art for SMART as it relates to both mechanical HDDs and solid state drives.
I am contributing by offering up the suggestion, however if I were a programmer, I would have already added those changes in my own version and I would be more than happy helping if I could.
As for difficulty adding the change, i realize we are no longer talking about “ada” or “da” or “sda” so the naming convention is different, however my little script does it and it is Bash.
TrueNAS already does monitor some data from the NVMe, it appears to only be missing the ability to schedule SMART tests. Okay, there is other stuff missing, the charts. I have no idea what is involved hete either. Maybe this is a 2 hour fix or 6 hours.
I have not compiled FreeNAS since version 9.x and back then i would contribute, however I’m fairly certain the language has changed since then, and i was winging it. I have not looked to see if where the source code is so i could grab a copy and compile it. One done, maybe i could make the needed changes.
And I also agree that a third party script should not be required for a basic test, however i will provide it as long as it is needed.
Speaking from non technical terms and simply as a Scale user who recently had an NVMe drop out with zero indicators that it may be failing, I feel that SMART (or similar if not SMART) should be added to Scale.
Drive failure indicators are hugely important, hence why we have SMART it the first place and with NVMe being a popular drive type, it should get the same love as other drive types. Granted I understand that the way the drive is monitored comes into question as to making any monitoring tool as useful as possible, but I would imagine there is a “best fit” metric that can be decided upon for monitoring an NVMe drive, or perhaps a combination of metrics used as an average, again I’m not familiar with the technical aspect.
Fortunately when my NVMe failed on me, I was using a mirror, like everyone should BUT, I should still have had some form of heads up that the drive was coming to the end of its life. Again, I know there are plenty of factors to consider where sometimes a drive will just up and die with no warning and no amount of monitoring will help, but those cases should be considered the minority.
As a user I would expect NVMe monitoring to be considered a “basic” feature of Scale, it is a mass storage system after all and NVMe adoption is only going to increase over time with cost per Gb falling.
I’m keeping my fingers crossed that this is being given serious consideration. Ultimately, Scale users should not be adopting a 3rd party solution for NVMe monitoring.
Because I’m not a programmer and all that Python stuff makes my brain numb, what does that mean? I thought the ticket was closed months ago and not to be implemented. Hopefully I’m reading this incorrectly.