I try to use Beelink ME mini as a NAS.
Installed Truenas Scale 25.04.2.1.
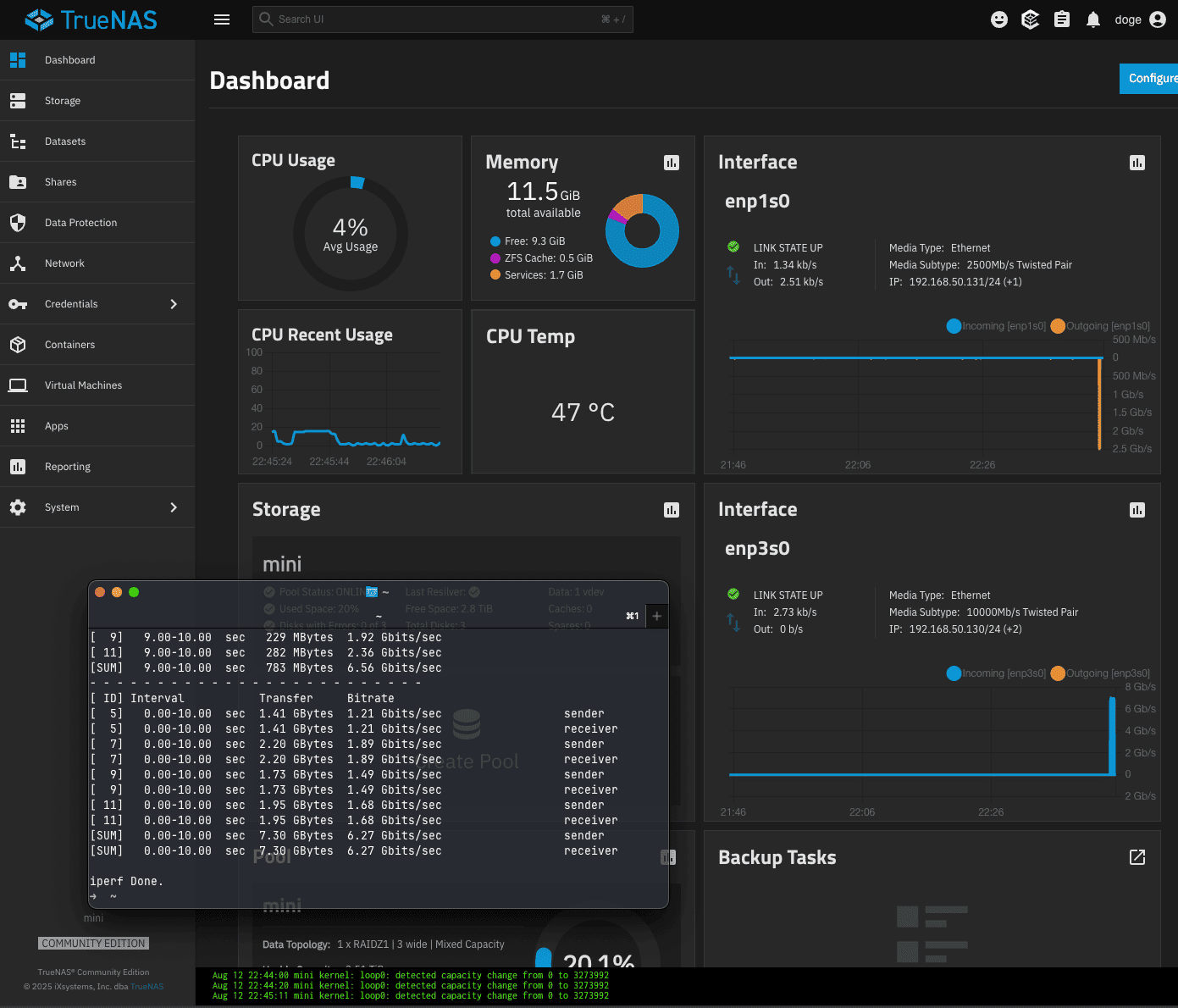
The ME mini is connected to 10gbe switch.
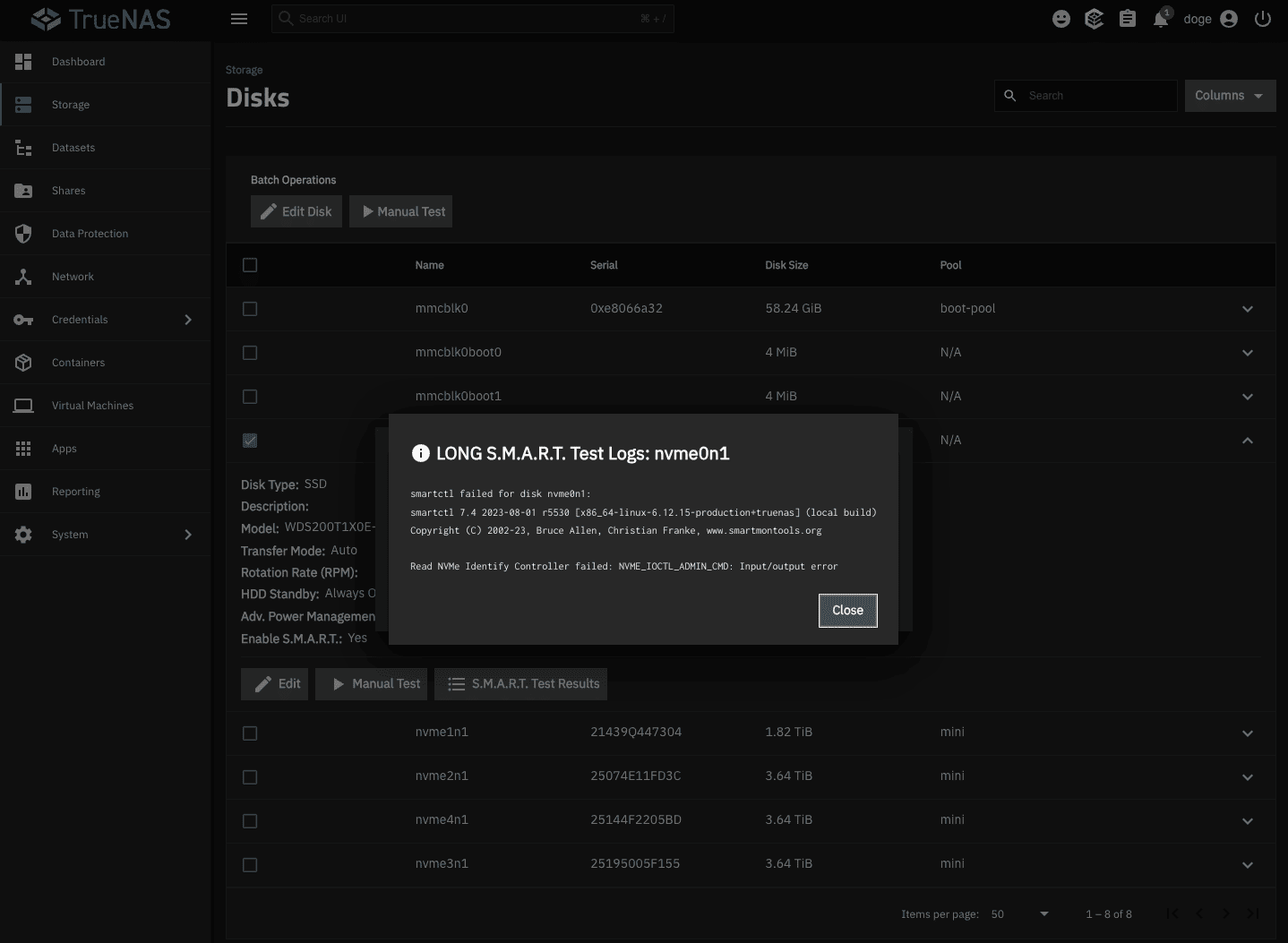
1/ NVME_IOCTL_ADMIN_CMD: Input/output error.
First i tryed to use it with 3 WD_BLACK 2TB SN850 NVMe (model : WDS200T1X0E-00AFY0).
Then i bought 3 Crucial T500 SSD (model : CT4000T500SSD3).
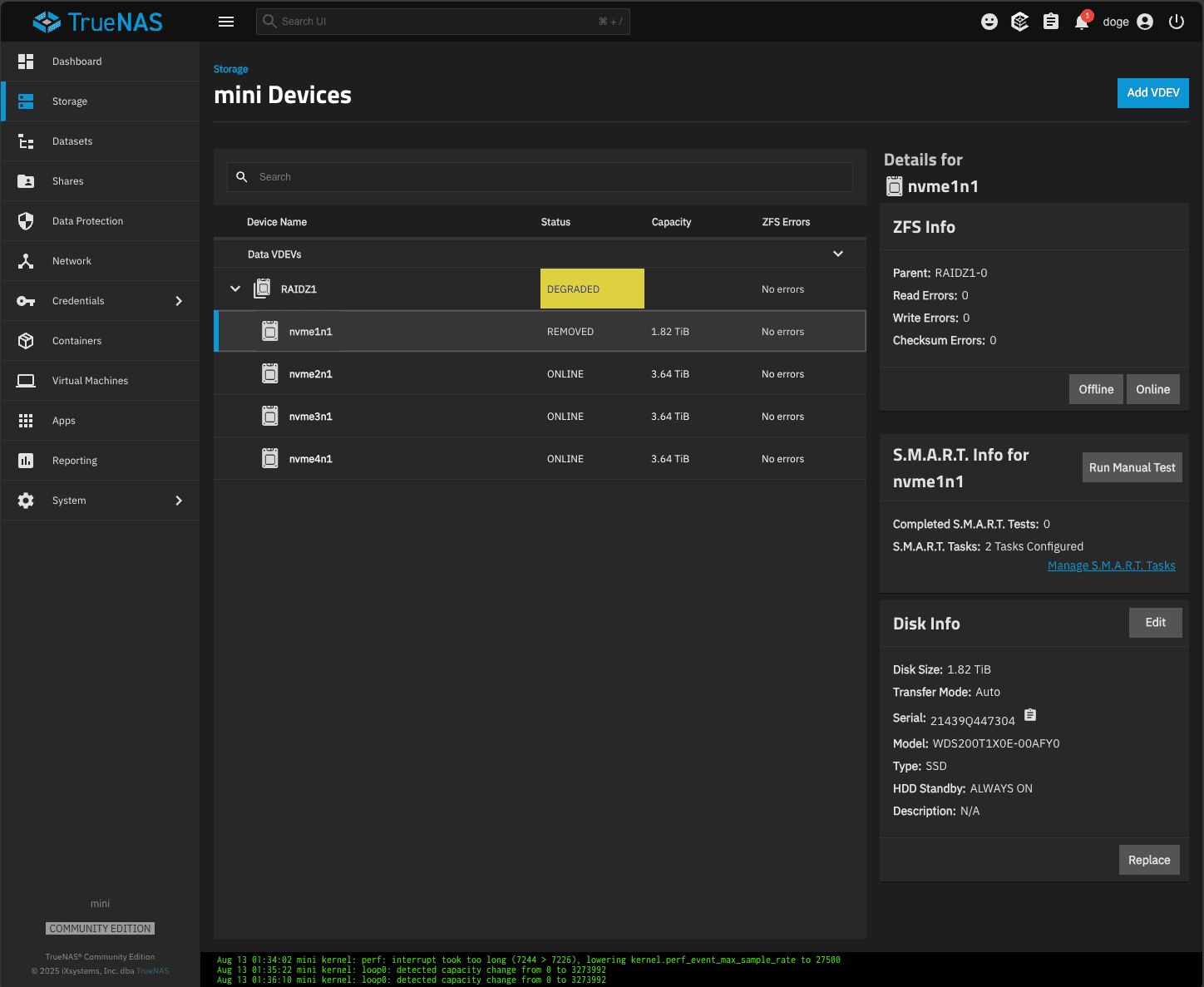
Now i have a 2 WD_BLACK (slots 2, 3) and 3 Crucial (slots 4,5,6) installed.
My pool is composed of 3 Crucial + 1 WD_BLACK.
Have this error with all my WD_BLACK M.2s :
Controller failed: NVME_IOCTL_ADMIN_CMD: Input/output error.
Device: /dev/nvme0n1, failed to read NVMe SMART/Health Information.
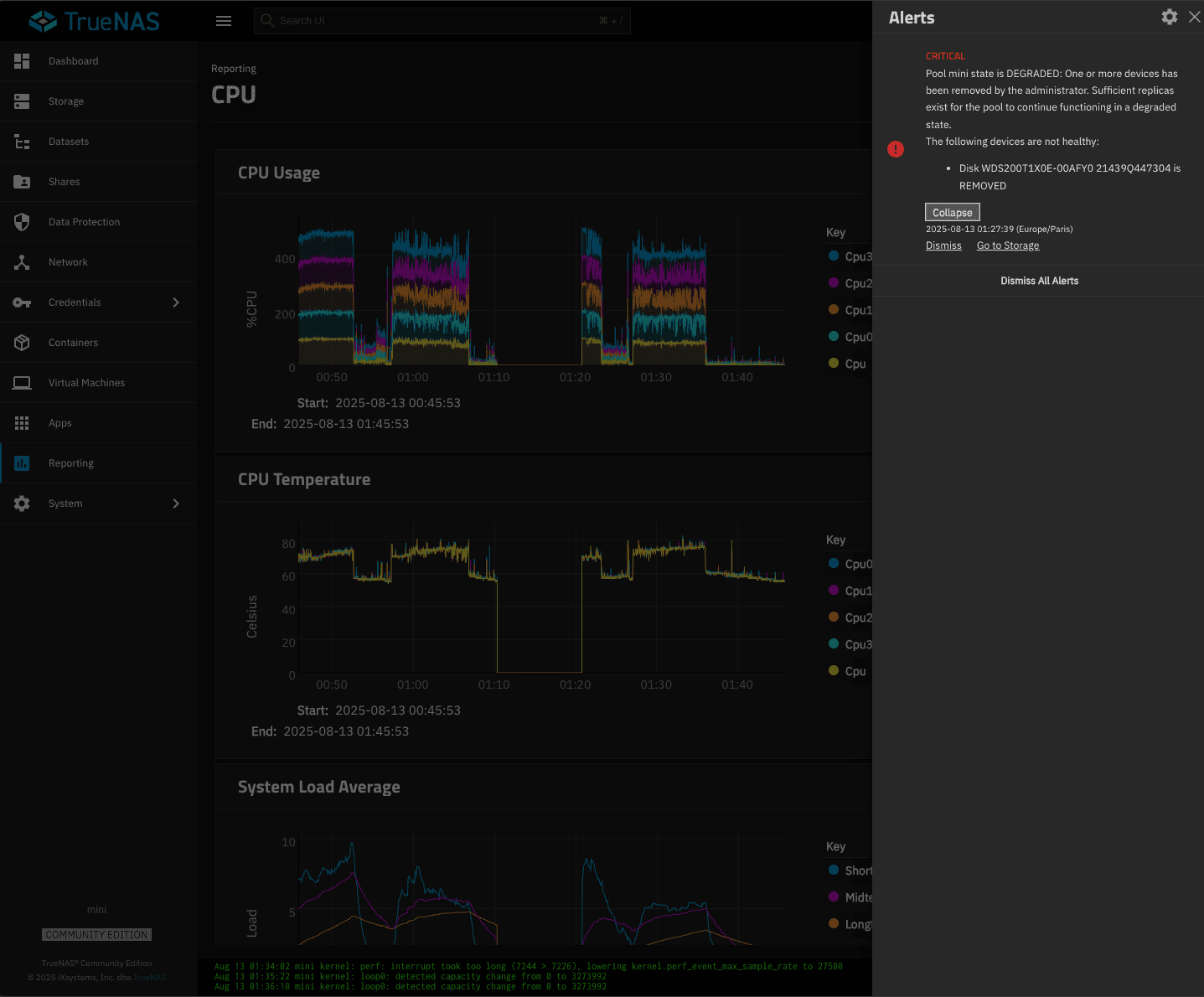
SSD disconnected, pool degraded, after reboot i could repair pool replacing failed drive with other drive (resilver, scrub).
But then other drive diconnects the same way in an other slot some time later.
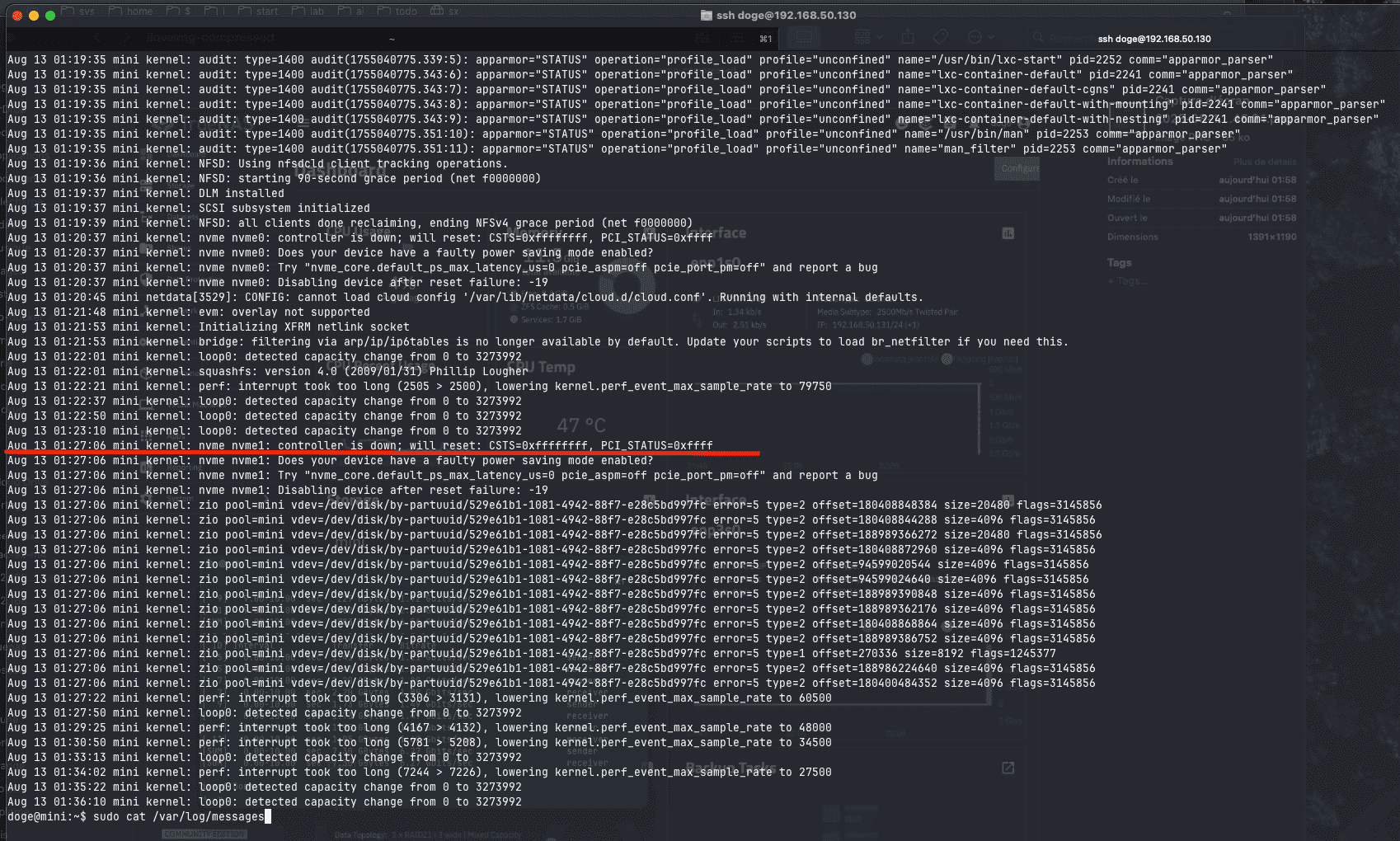
Also i see this in sudo cat /var/log/messages :
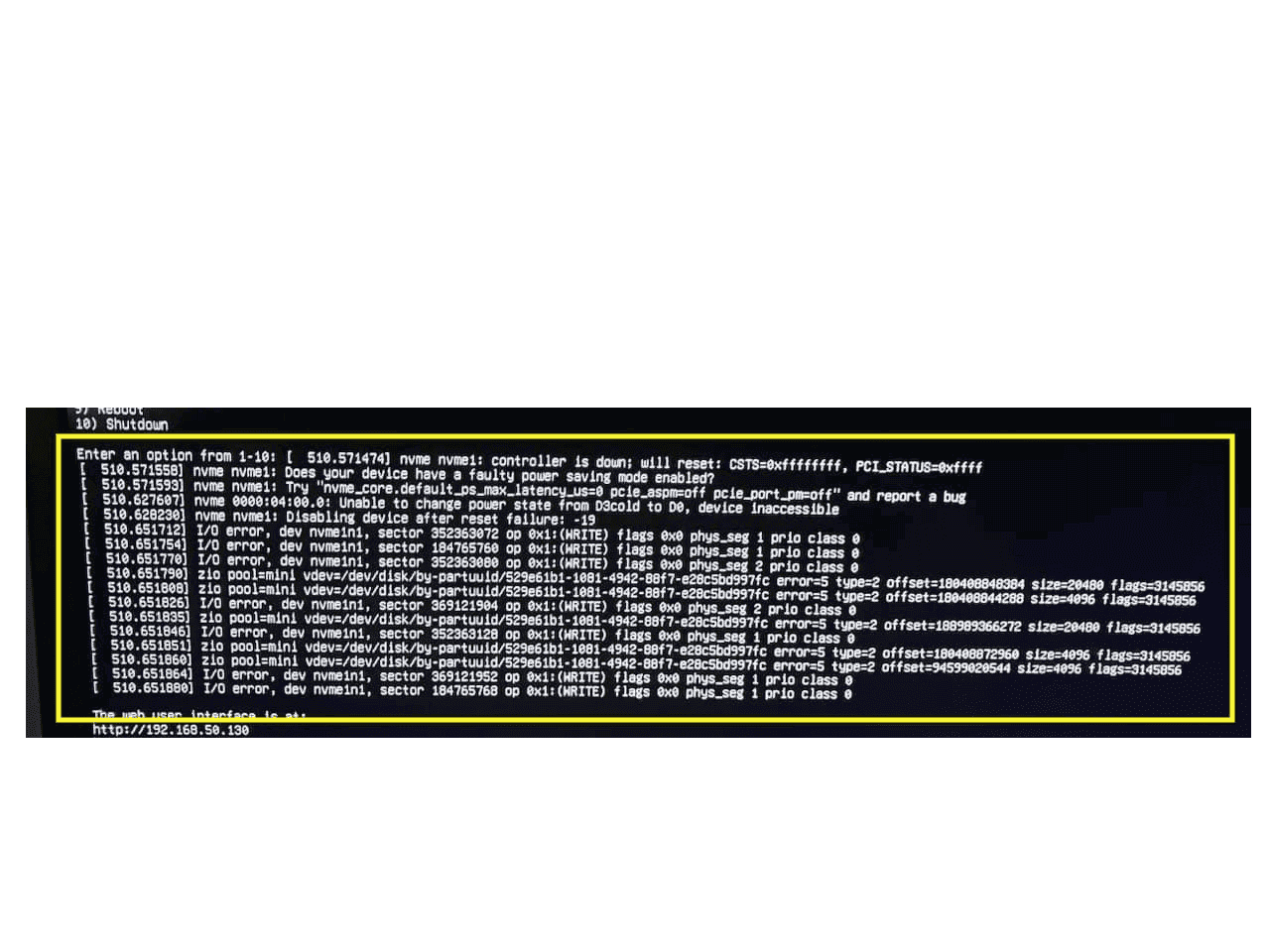
Aug 13 01:27:06 mini kernel: nvme nvme1: controller is down; will reset: CSTS=0xffffffff, PCI_STATUS=0xffff
Aug 13 01:27:06 mini kernel: nvme nvme1: Does your device have a faulty power saving mode enabled?
Aug 13 01:27:06 mini kernel: nvme nvme1: Try “nvme_core.default_ps_max_latency_us=0 pcie_aspm=off pcie_port_pm=off” and report a bug
Aug 13 01:27:06 mini kernel: nvme nvme1: Disabling device after reset failure: -19
2/ Tryed 5gbe USB wavelink ethernet adapter
It disconnected after few minutes/hours of testing.
3/ Tryed 10gbe Ethernet card via M.2 adater in slot 1
It disconnected after few tests with iperf3.
To test disks i disconnected ethernet 5/10gbe adapters, so the problem appears without anything connected (anything other than NVME themselves).
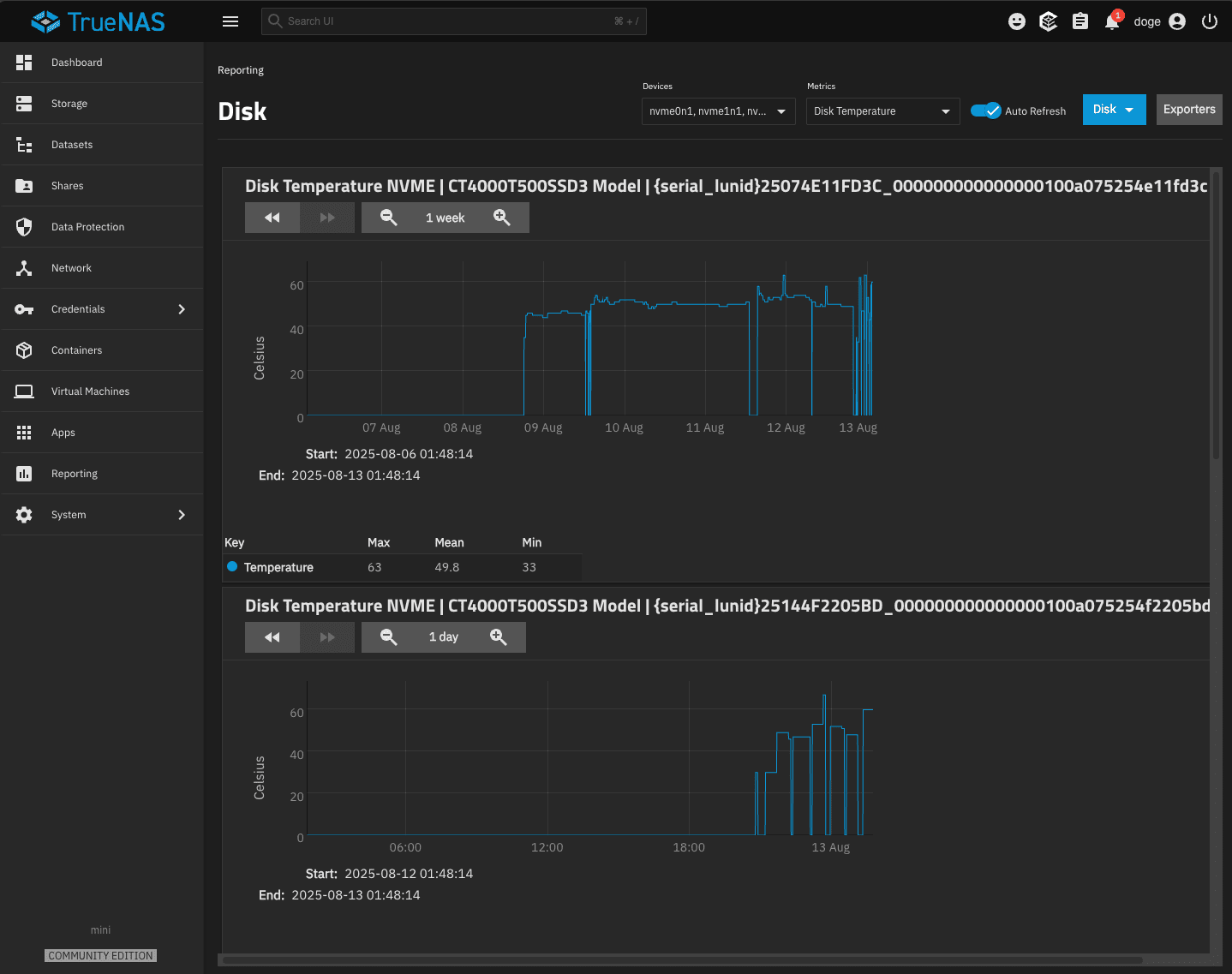
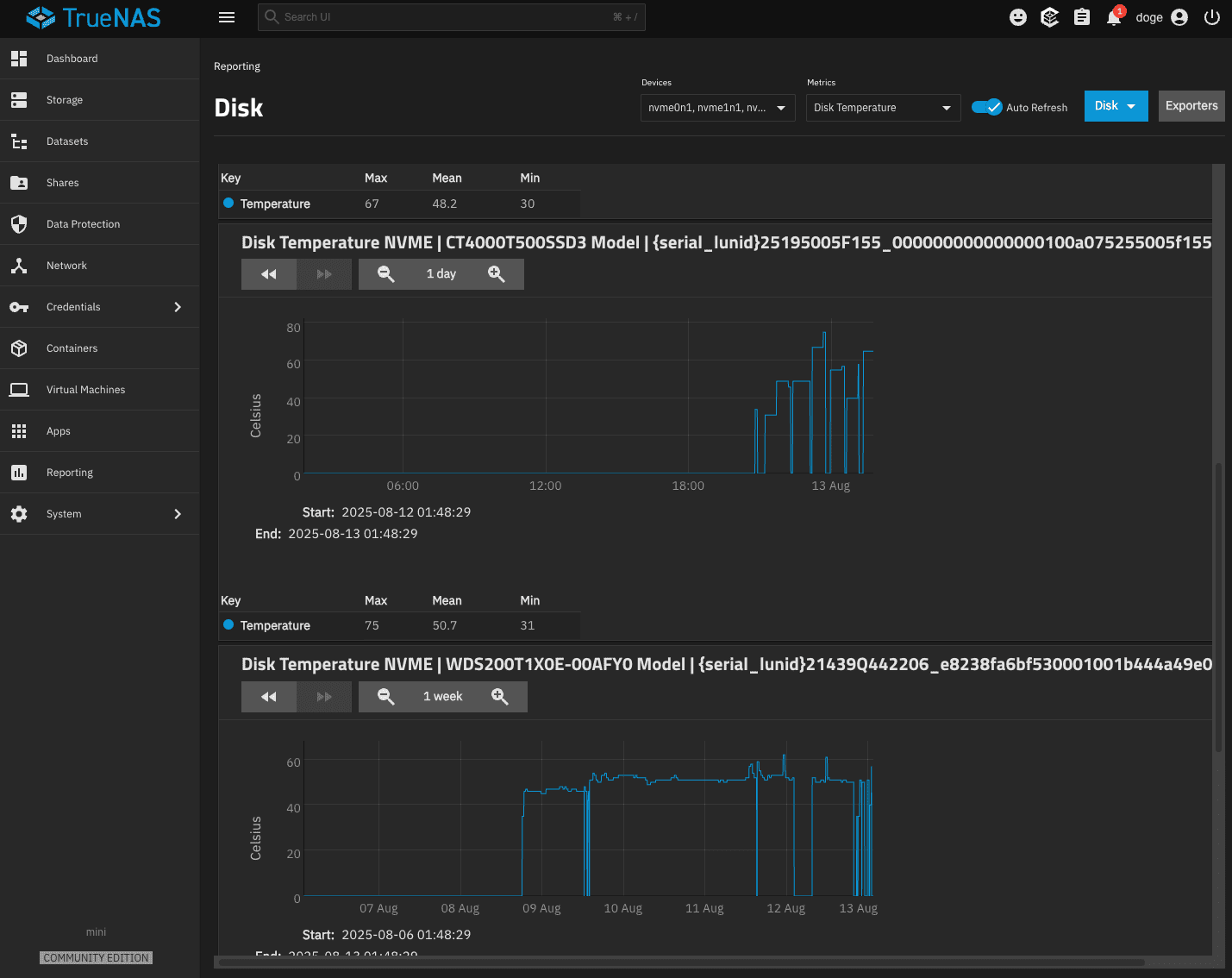
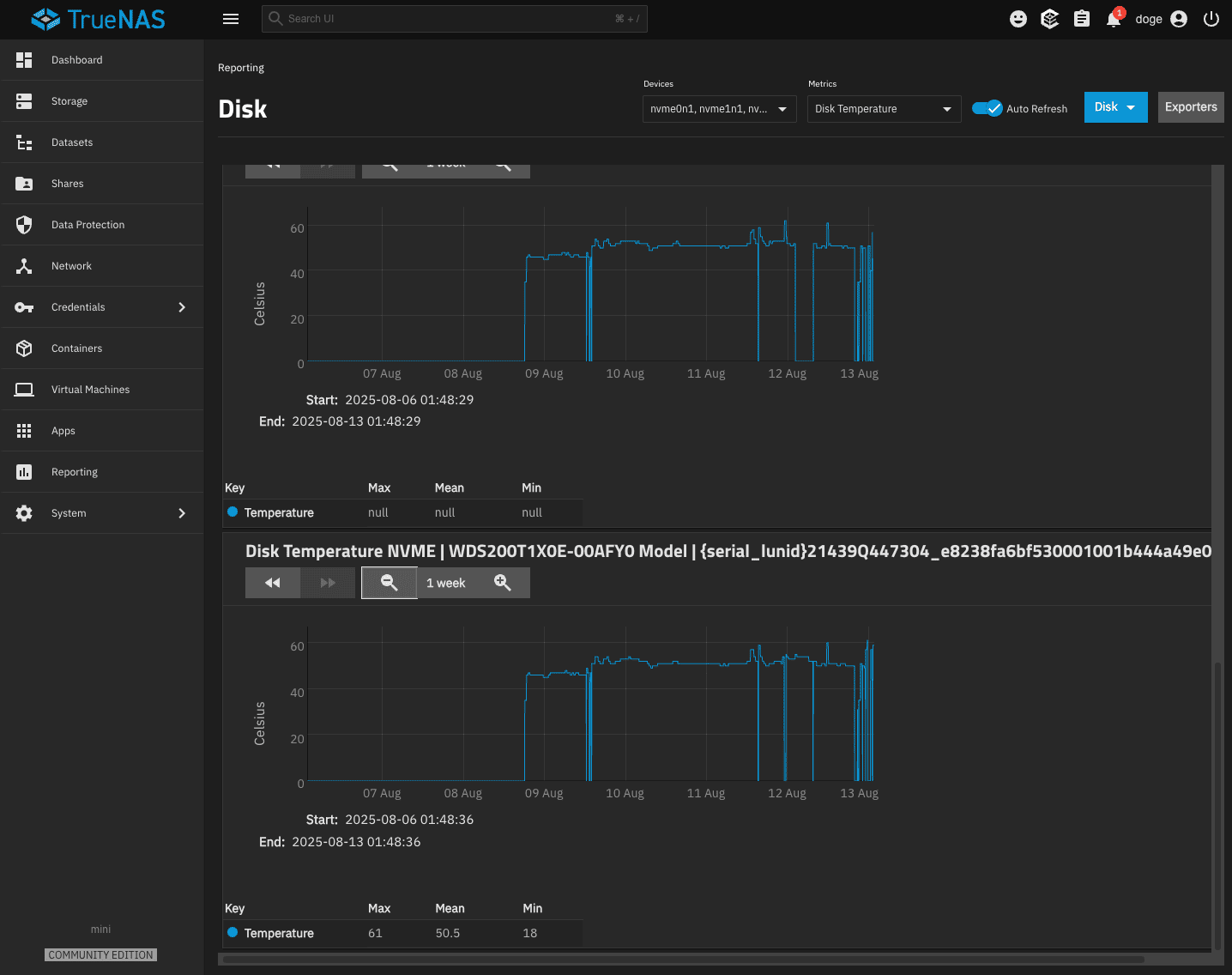
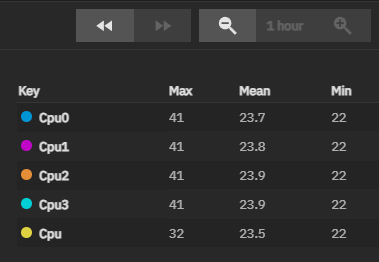
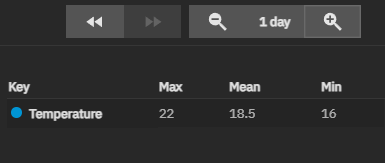
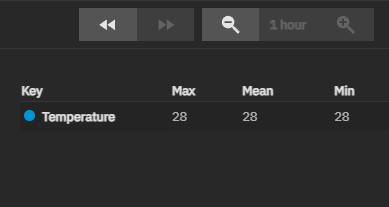
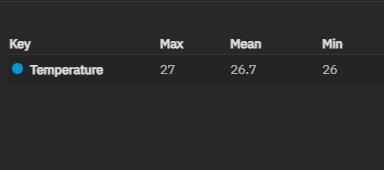
CPU and Disks go to 60-80 degrees celcius quickly when there is activity.
I opened the ME Mini to see if fan is working, it works but does not seem to do much.
I do not hear it at all.
Looks like my WD_BLACK drives are removed all the time few minutes after stop / wait 5 min / restart.
Perhaps they use too much power and are not properly dissipate heat ?
Perhaps the system is overheating quickly when there is activity ?
Is there bios settings or something to boost the fan ?
Help please ![]()
Note :
Also posted in Beelink forum, here :