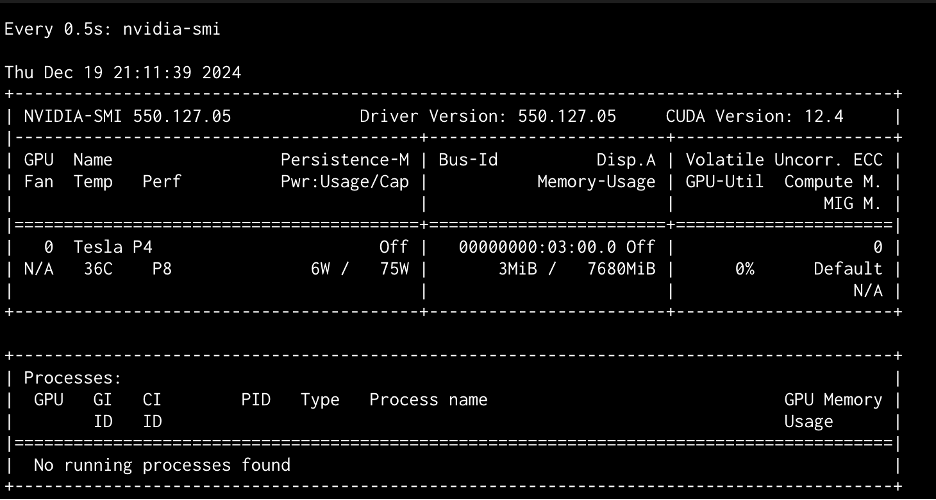
After confirming the installed GPU resources were detectable with the lspci | grep -i nvidia command and isolating GPU resources for use with a VM or container, I saw and added said resources in the VM config and went to spin up the VM. It failed and here is the error message I got:
Traceback (most recent call last):
File “/usr/lib/python3/dist-packages/middlewared/plugins/vm/supervisor/supervisor.py”, line 189, in start
if self.domain.create() < 0:
^^^^^^^^^^^^^^^^^^^^
File “/usr/lib/python3/dist-packages/libvirt.py”, line 1373, in create
raise libvirtError(‘virDomainCreate() failed’)
libvirt.libvirtError: internal error: process exited while connecting to monitor: 2024-12-14T04:40:30.869788Z qemu-system-x86_64: -device {“driver”:“vfio-pci”,“host”:“0000:03:00.0”,“id”:“hostdev0”,“bus”:“pci.0”,“addr”:“0x7”}: vfio 0000:03:00.0: failed to setup container for group 13: Failed to set iommu for container: Operation not permitted
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File “/usr/lib/python3/dist-packages/middlewared/main.py”, line 208, in call_method
result = await self.middleware.call_with_audit(message[‘method’], serviceobj, methodobj, params, self)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/usr/lib/python3/dist-packages/middlewared/main.py”, line 1526, in call_with_audit
result = await self._call(method, serviceobj, methodobj, params, app=app,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/usr/lib/python3/dist-packages/middlewared/main.py”, line 1457, in _call
return await methodobj(*prepared_call.args)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/usr/lib/python3/dist-packages/middlewared/schema/processor.py”, line 179, in nf
return await func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/usr/lib/python3/dist-packages/middlewared/schema/processor.py”, line 49, in nf
res = await f(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^
File “/usr/lib/python3/dist-packages/middlewared/plugins/vm/vm_lifecycle.py”, line 58, in start
await self.middleware.run_in_thread(self._start, vm[‘name’])
File “/usr/lib/python3/dist-packages/middlewared/main.py”, line 1364, in run_in_thread
return await self.run_in_executor(io_thread_pool_executor, method, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/usr/lib/python3/dist-packages/middlewared/main.py”, line 1361, in run_in_executor
return await loop.run_in_executor(pool, functools.partial(method, *args, **kwargs))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/usr/lib/python3.11/concurrent/futures/thread.py”, line 58, in run
result = self.fn(*self.args, **self.kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/usr/lib/python3/dist-packages/middlewared/plugins/vm/vm_supervisor.py”, line 68, in _start
self.vms[vm_name].start(vm_data=self._vm_from_name(vm_name))
File “/usr/lib/python3/dist-packages/middlewared/plugins/vm/supervisor/supervisor.py”, line 198, in start
raise CallError(‘\n’.join(errors))
middlewared.service_exception.CallError: [EFAULT] internal error: process exited while connecting to monitor: 2024-12-14T04:40:30.869788Z qemu-system-x86_64: -device {“driver”:“vfio-pci”,“host”:“0000:03:00.0”,“id”:“hostdev0”,“bus”:“pci.0”,“addr”:“0x7”}: vfio 0000:03:00.0: failed to setup container for group 13: Failed to set iommu for container: Operation not permitted
This happened in any GPU mode I selected in the UI.
Is this a Jira case I need to log, or am I doing something wrong?
Thanks!
-Rodney