Morning all,
We’re tracking an issue with Apps that impacts NVIDIA users, which we’ve now added to the Known Issues page of our release notes.
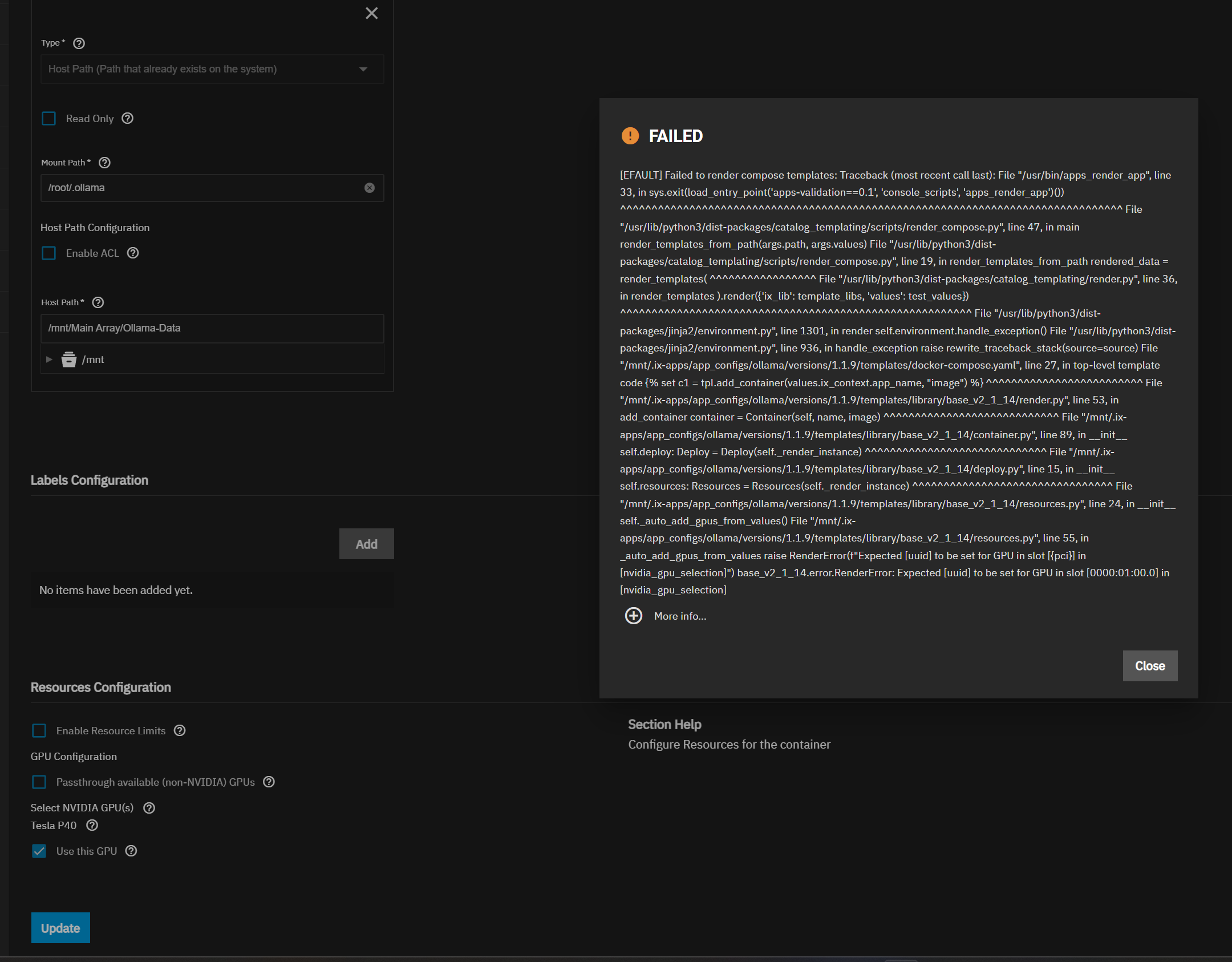
Some users who have upgraded to 24.10.0 from a previous version, and who have applications with have NVIDIA GPU allocations, report the error Expected [uuid] to be set for GPU inslot [<some pci slot>] in [nvidia_gpu_selection]) (see NAS-132086).
Users experiencing this error should follow the steps below for a one time fix that should not need to be repeated.
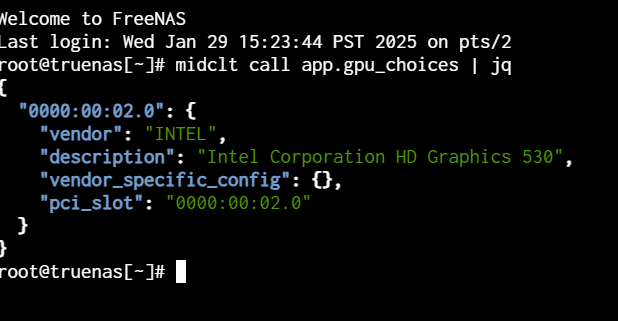
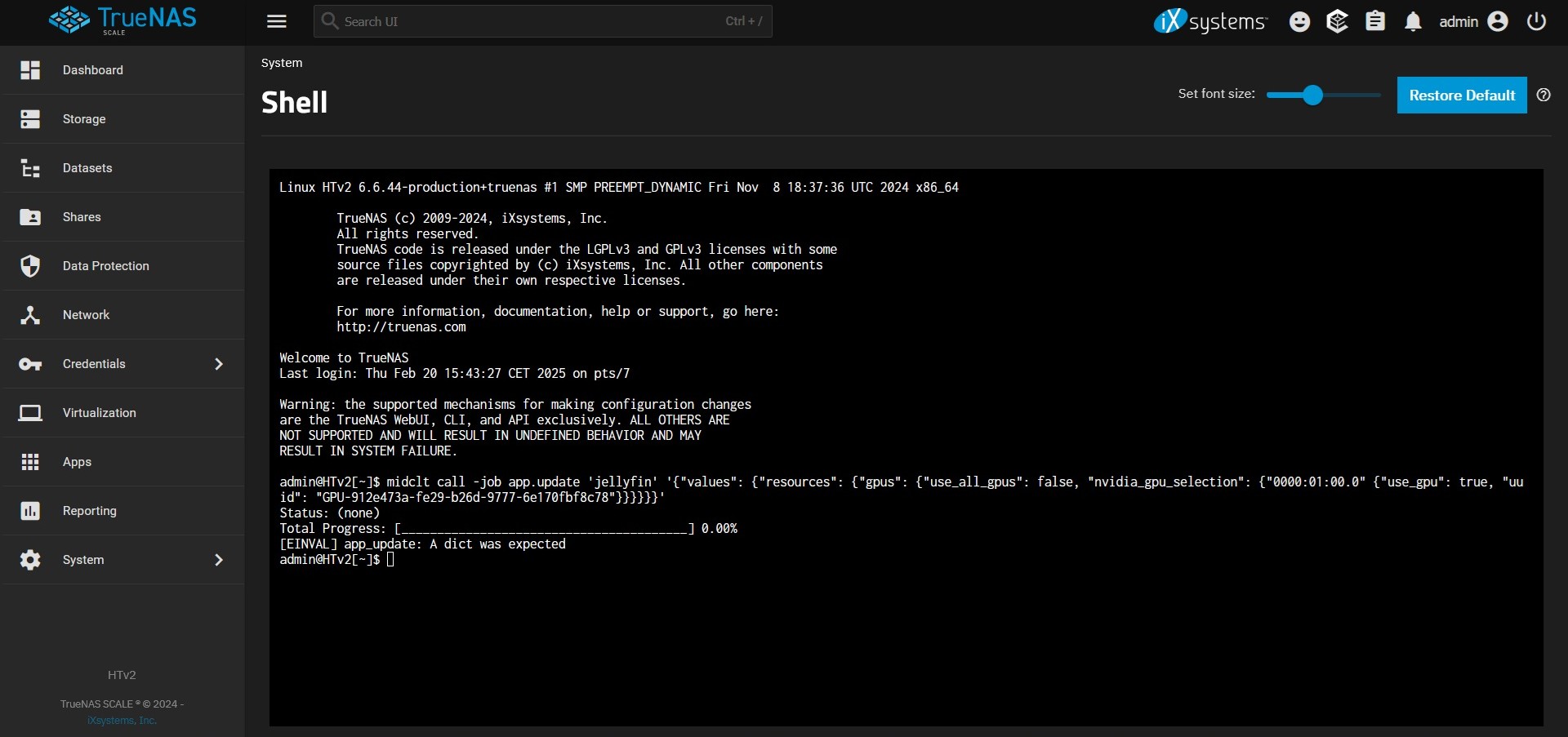
Connect to a shell session and retrieve the UUID for each GPU with the command midclt call app.gpu_choices | jq.
For each application that experiences the error, run midclt call -job app.update APP_NAME '{"values": {"resources": {"gpus": {"use_all_gpus": false, "nvidia_gpu_selection": {"PCI_SLOT": {"use_gpu": true, "uuid": "GPU_UUID"}}}}}}'
Where:
APP_NAMEis the name you entered in the application, for example “plex”.PCI_SLOTis the pci slot identified in the error, for example "0000:2d:00.0”.GPU_UUIDis the UUID matching the pci slot that you retrieved with the above command.
Engineering is digging into the root cause of this - it may be related to the NVIDIA drivers being installed at first-boot, and the apps system isn’t refreshing the UUIDs correctly after the installation.
If you’re having an issue with NVIDIA that isn’t related to the missing UUIDs, please start a separate thread, and ideally include the exact text of the error message. If you have an issue with driver installation, please also include the /var/log/nvidia-installer.log file as an attachment.