Dear folks!
Let me first apologise for the wall of text. Let me know if anything else is needed though.
I have been scouring the interwebs for about a week now and I am having trouble finding a solution to my issue. I have seen others that have gotten sort of similar issues resolved so I am hoping that this may be the case for me as well.
I’ve been using TrueNAS Scale for roughly 6 months now so I’m still fairly new to it but so far it has been working well for my purposes.
Last weekend I was preparing to backup the personally important stuff and before I could start the actual backup, 1 of the drives in my pool died. It started making the clicking noises of certain death. Luckily, I had a spare drive of the same size in a different system that could be repurposed. So I cleaned the replacement drive and went on my way to start replacing the dead/dying disk.
Before reading any guides on how to actually do this, I shutdown the system in order to replace the drive. Then I thought that maybe I should read up on what the documentation says about replacing a dead drive in a pool. So, reading the guide I noticed I need to first offline the disk, which apparently is done in the dashboard. So booting back up again and expecting to do as the documentation suggests but instead of seeing a degraded pool, the pool is now gone and I have 4 “unused disks”.
I tried understanding what had gone wrong and after many hours of googling, reading on the TrueNAS forums and reddit posts I have come to the conclusion that I need help from someone smarter than myself.
I have a spare machine that is destined to replace another which I have used as a testbed, to make sure it’s not any of the other components that are causing any issues with reading the drive. Moving the drives is physically not an issue.
This has allowed me to confirm that it’s the drive that is borked and not any SATA controllers or motherboard connections (yes, I have also replaced or switched around the cables).
I had this pool set up as “pool1” when it was working.
The pool consists of 4x 4TB drives in a RAIDZ1 configuration (I think it’s RAIDZ1 at least, I do know it had somewhere around 10TB of usable space).
2 of the drives are Seagate IronWolfs and the other two are WD Greens.
The spare drive is a 4TB Toshiba MG04ACA-N Series (a couple of years old but at least no SMART errors or warnings), yet to be connected.
I currently have the drives in the spare machine on a fresh TrueNAS Scale install on bare metal.
It is running Dragonfish-24.04.2 (same as the older machine the pool was originally in)
This system is an old low-ish spec gaming PC
Motherboard: ASUS Prime Z270-P
CPU: Intel i5 7500
RAM: 2x Kingston KHX2666C16/8G
PSU: Corsair VS550
System drive: Intel SSDPEKKF256 (some sort of Intel m.2 NVMe drive)
No other PCIe devices or such
Since I am getting the same issue on both machines, I don’t think it matters which one I’m trying to import the pool on. Correct me if I am wrong though and I will swap back to the older Xeon-based machine.
So, this is roughly where I’m at.
When trying to import the pool, I am left with this error in the GUI:

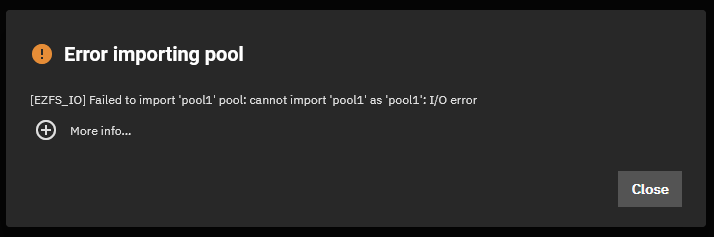
The “More info…” contains this:
Error: concurrent.futures.process._RemoteTraceback:
"""
Traceback (most recent call last):
File "/usr/lib/python3/dist-packages/middlewared/plugins/zfs_/pool_actions.py", line 227, in import_pool
zfs.import_pool(found, pool_name, properties, missing_log=missing_log, any_host=any_host)
File "libzfs.pyx", line 1369, in libzfs.ZFS.import_pool
File "libzfs.pyx", line 1397, in libzfs.ZFS.__import_pool
libzfs.ZFSException: cannot import 'pool1' as 'pool1': I/O error
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/lib/python3.11/concurrent/futures/process.py", line 256, in _process_worker
r = call_item.fn(*call_item.args, **call_item.kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/worker.py", line 112, in main_worker
res = MIDDLEWARE._run(*call_args)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/worker.py", line 46, in _run
return self._call(name, serviceobj, methodobj, args, job=job)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/worker.py", line 34, in _call
with Client(f'ws+unix://{MIDDLEWARE_RUN_DIR}/middlewared-internal.sock', py_exceptions=True) as c:
File "/usr/lib/python3/dist-packages/middlewared/worker.py", line 40, in _call
return methodobj(*params)
^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/schema/processor.py", line 191, in nf
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/plugins/zfs_/pool_actions.py", line 207, in import_pool
with libzfs.ZFS() as zfs:
File "libzfs.pyx", line 529, in libzfs.ZFS.__exit__
File "/usr/lib/python3/dist-packages/middlewared/plugins/zfs_/pool_actions.py", line 231, in import_pool
raise CallError(f'Failed to import {pool_name!r} pool: {e}', e.code)
middlewared.service_exception.CallError: [EZFS_IO] Failed to import 'pool1' pool: cannot import 'pool1' as 'pool1': I/O error
"""
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/usr/lib/python3/dist-packages/middlewared/job.py", line 469, in run
await self.future
File "/usr/lib/python3/dist-packages/middlewared/job.py", line 511, in __run_body
rv = await self.method(*args)
^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/schema/processor.py", line 187, in nf
return await func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/schema/processor.py", line 47, in nf
res = await f(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/plugins/pool_/import_pool.py", line 113, in import_pool
await self.middleware.call('zfs.pool.import_pool', guid, opts, any_host, use_cachefile, new_name)
File "/usr/lib/python3/dist-packages/middlewared/main.py", line 1564, in call
return await self._call(
^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/main.py", line 1425, in _call
return await self._call_worker(name, *prepared_call.args)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/main.py", line 1431, in _call_worker
return await self.run_in_proc(main_worker, name, args, job)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/main.py", line 1337, in run_in_proc
return await self.run_in_executor(self.__procpool, method, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/main.py", line 1321, in run_in_executor
return await loop.run_in_executor(pool, functools.partial(method, *args, **kwargs))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
middlewared.service_exception.CallError: [EZFS_IO] Failed to import 'pool1' pool: cannot import 'pool1' as 'pool1': I/O errorWhen trying to import via terminal (either the shell in the GUI or in a SSH-session) I am getting this:
admin@truenas[~]$ sudo zpool import pool1
cannot import 'pool1': pool was previously in use from another system.
Last accessed by server2 (hostid=2b237ca9) at Sun Jan 26 08:48:14 2025
The pool can be imported, use 'zpool import -f' to import the pool.admin@truenas[~]$ sudo zpool import -f pool1
cannot import 'pool1': I/O error
Destroy and re-create the pool from
a backup source.After reading through other threads where people have gotten help, I deduced that this information may be necessary so I’m including it in the initial post:
admin@truenas[~]$ sudo lsblk -bo NAME,MODEL,ROTA,PTTYPE,TYPE,START,SIZE,PARTTYPENAME,PARTUUID
NAME MODEL ROTA PTTYPE TYPE START SIZE PARTTYPENAME PARTUUID
sda ST4000VN008-2DR16 1 gpt disk 4000787030016
└─sda1 1 gpt part 4096 4000784056832 Solaris /usr & Apple ZFS 735b5279-e7d5-4279-ad07-d91d724a7ac3
sdb ST4000VN008 1 disk 4000787030016
sdc WDC WD40EZRX-00SP 1 gpt disk 4000787030016
└─sdc1 1 gpt part 4096 4000784056832 Solaris /usr & Apple ZFS 24879df8-0fb5-4ae1-ae5b-4c3aa9a88b69
sdd WDC WD40EZRX-00SP 1 gpt disk 4000787030016
└─sdd1 1 gpt part 4096 4000784056832 Solaris /usr & Apple ZFS 42939b6d-2e31-431a-aaab-9ca4c278ca3d
nvme0n1 INTEL SSDPEKKF256 0 gpt disk 256060514304
├─nvme0n1p1 0 gpt part 4096 1048576 BIOS boot c4dd014f-0e2d-4b97-b3d5-e5693ed9a4ee
├─nvme0n1p2 0 gpt part 6144 536870912 EFI System 6dc10828-bb05-4c4a-b9a7-e2fbaa8baa80
├─nvme0n1p3 0 gpt part 34609152 238340611584 Solaris /usr & Apple ZFS 13fa5bcb-dc62-44f4-bf0e-708a330357cf
└─nvme0n1p4 0 gpt part 1054720 17179869184 Linux swap 26ea4599-1fb6-49cb-a973-44c86fa70947
└─nvme0n1p4 0 crypt 17179869184admin@truenas[~]$ sudo lspci
00:00.0 Host bridge: Intel Corporation Xeon E3-1200 v6/7th Gen Core Processor Host Bridge/DRAM Registers (rev 05)
00:02.0 VGA compatible controller: Intel Corporation HD Graphics 630 (rev 04)
00:14.0 USB controller: Intel Corporation 200 Series/Z370 Chipset Family USB 3.0 xHCI Controller
00:16.0 Communication controller: Intel Corporation 200 Series PCH CSME HECI #1
00:17.0 SATA controller: Intel Corporation 200 Series PCH SATA controller [AHCI mode]
00:1b.0 PCI bridge: Intel Corporation 200 Series PCH PCI Express Root Port #17 (rev f0)
00:1c.0 PCI bridge: Intel Corporation 200 Series PCH PCI Express Root Port #1 (rev f0)
00:1c.7 PCI bridge: Intel Corporation 200 Series PCH PCI Express Root Port #8 (rev f0)
00:1d.0 PCI bridge: Intel Corporation 200 Series PCH PCI Express Root Port #9 (rev f0)
00:1f.0 ISA bridge: Intel Corporation 200 Series PCH LPC Controller (Z270)
00:1f.2 Memory controller: Intel Corporation 200 Series/Z370 Chipset Family Power Management Controller
00:1f.3 Audio device: Intel Corporation 200 Series PCH HD Audio
00:1f.4 SMBus: Intel Corporation 200 Series/Z370 Chipset Family SMBus Controller
03:00.0 Ethernet controller: Realtek Semiconductor Co., Ltd. RTL8111/8168/8411 PCI Express Gigabit Ethernet Controller (rev 15)
04:00.0 Non-Volatile memory controller: Intel Corporation SSD 600P Series (rev 03)admin@truenas[~]$ sudo sas2flash -list
LSI Corporation SAS2 Flash Utility
Version 20.00.00.00 (2014.09.18)
Copyright (c) 2008-2014 LSI Corporation. All rights reserved
No LSI SAS adapters found! Limited Command Set Available!
ERROR: Command Not allowed without an adapter!
ERROR: Couldn't Create Command -list
Exiting Program.admin@truenas[~]$ sudo sas3flash -list
Avago Technologies SAS3 Flash Utility
Version 16.00.00.00 (2017.05.02)
Copyright 2008-2017 Avago Technologies. All rights reserved.
No Avago SAS adapters found! Limited Command Set Available!
ERROR: Command Not allowed without an adapter!
ERROR: Couldn't Create Command -list
Exiting Program.From what I can deduce in the lsblk command, it would appear that the broken drive ST4000VN008 (designated /dev/sdb in this instance) appears to have lost the entire GPT-table. The machine has since been restarted and is currently on /dev/sda, not that it matters much but I’m clarifying for this next bit.
I ran the following command with this result
admin@truenas[~]$ sudo fdisk -l /dev/sda
fdisk: cannot open /dev/sda: Input/output errorIt also doesn’t seem like the disks inside the drive are spinning up as I can’t feel it moving at all, so I would assume this is why I’m getting the I/O errors.
I do not have any backups of the data that was on the pool and it contains both personal important stuff as well as non-important media. The media I can live without even if it’ll be a hassle to rebuild, but the personal data is very important that I save. I think I maybe able to recover most if not all of it using recovery tools. I would however prefer not to have to do that as importing the pool and replacing the broken drive would be the easier (well, cheaper at least) solution.
Any help from any of you wizards out there would be extremely appreciated!