I have a Proxmox hypervisor (8.2.2) running a single VM for TrueNAS. Disks are on a sata controller that is passed through in hardware. It was on Cobia until a month or so ago, and then upgraded to Dragonfish 24.4.0. All running fine.
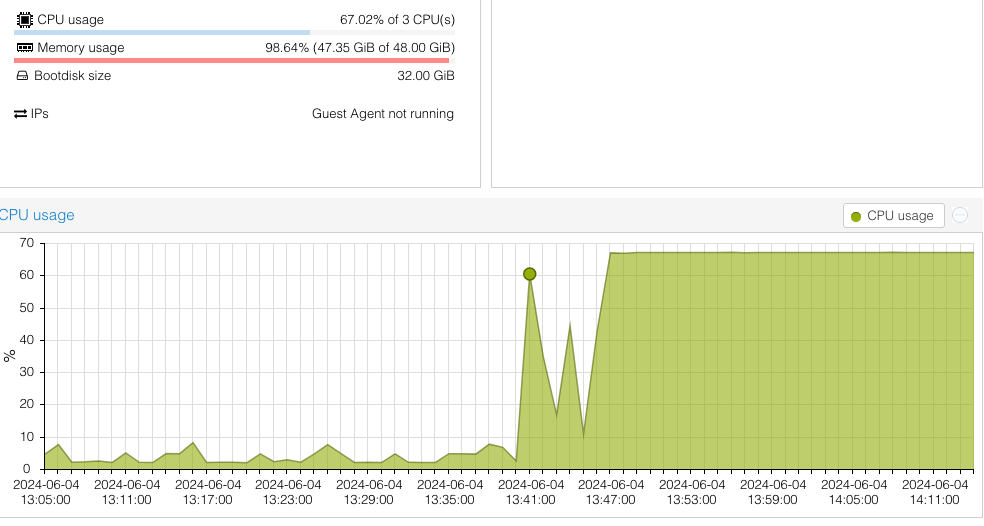
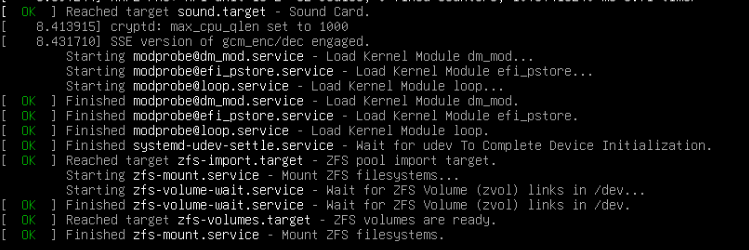
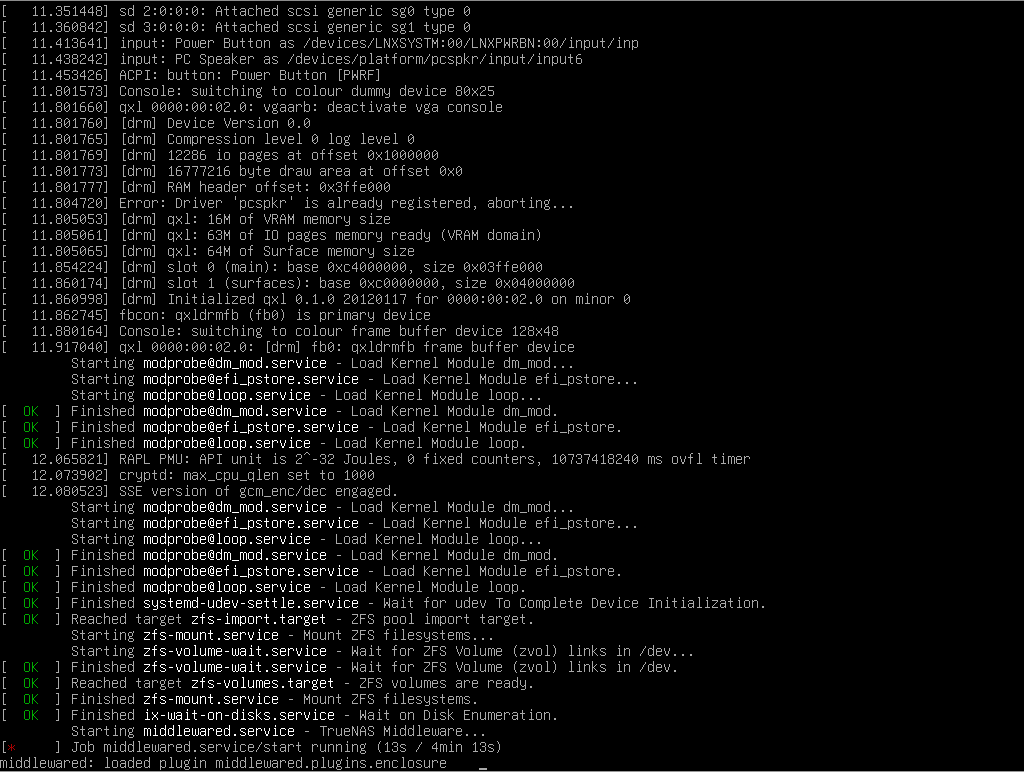
This afternoon, I tried the upgrade to 24.04.1.1, and it hung after rebooting, just after the Finished zfs-mount.service line. CPU usage on the VM was pegged at 67%; the vm has 3 CPU cores allocated, so this is 2 cores at 100%. It stayed this way for 30 mins, unresponsive. Can’t SSH in, no shell to interact with. Tried to gracefully shutdown / reboot using Proxmox controls and nothing worked.
I’ve rebooted and started up using the 24.04.0 boot environment and all is ok again. I’ve checked /var/log/syslog and kern.log, but neither have any record of the failed boot. Both show the shutdown before the upgrade and the boot after reverting the boot environment. If anyone can point me in the direction of alternate logs, I’ll post them.
This seems to be very similar to this report, however my VM has 48GB RAM assigned.
Any reason to not submit a bug report? I suspect IX would want to find the cause and fix it, given that everything is fixing to change with Electric Eel and more folks might be wanting to try it out or use the VM of Eel to migrate their stuff and test it before live updating.
I tried… but I got shot down without them even reading past the first two lines.
Which is especially annoying when @HoneyBadger was only extolling the virtues of VMs a few days ago and the linked blog post emphasises how much their team use them too.
I was happy to help work to find the bug that’s obviously been introduced in the last update, but it’s frustrating when its ignored.
Both issues are interesting and we are trying to keep tabs on how often / where they are reported. As always details matter, so lets gather up as much as we can and see if anything stands out as an important clue. We did investigate and have a resolution to the one issue with super long boot-times, but likely unrelated:
I’m wondering if the kernel update in 24.04.1 (to fix SATA port multipliers) broke something. We’ve just merged in a further update to Kernel that will be in Dragonfish nightly images soon (Tomorrow). Would those with a reproduction case be willing to give it a whirl to see if behavior changes?
My concern is we have a lot of users who may want to actually test Eel before deploying. Due to getting rid of kubernetes, probably more than any other release. I sure will, and I never tested before. So, if this remains a problem on Eel that may be a barrier to adoption of Eel. There is no way I will ever migrate to Eel if I can’t get a test system up and running to potentially modify my stuff. And I am not buying another server just to do that, as many home users will not do either.