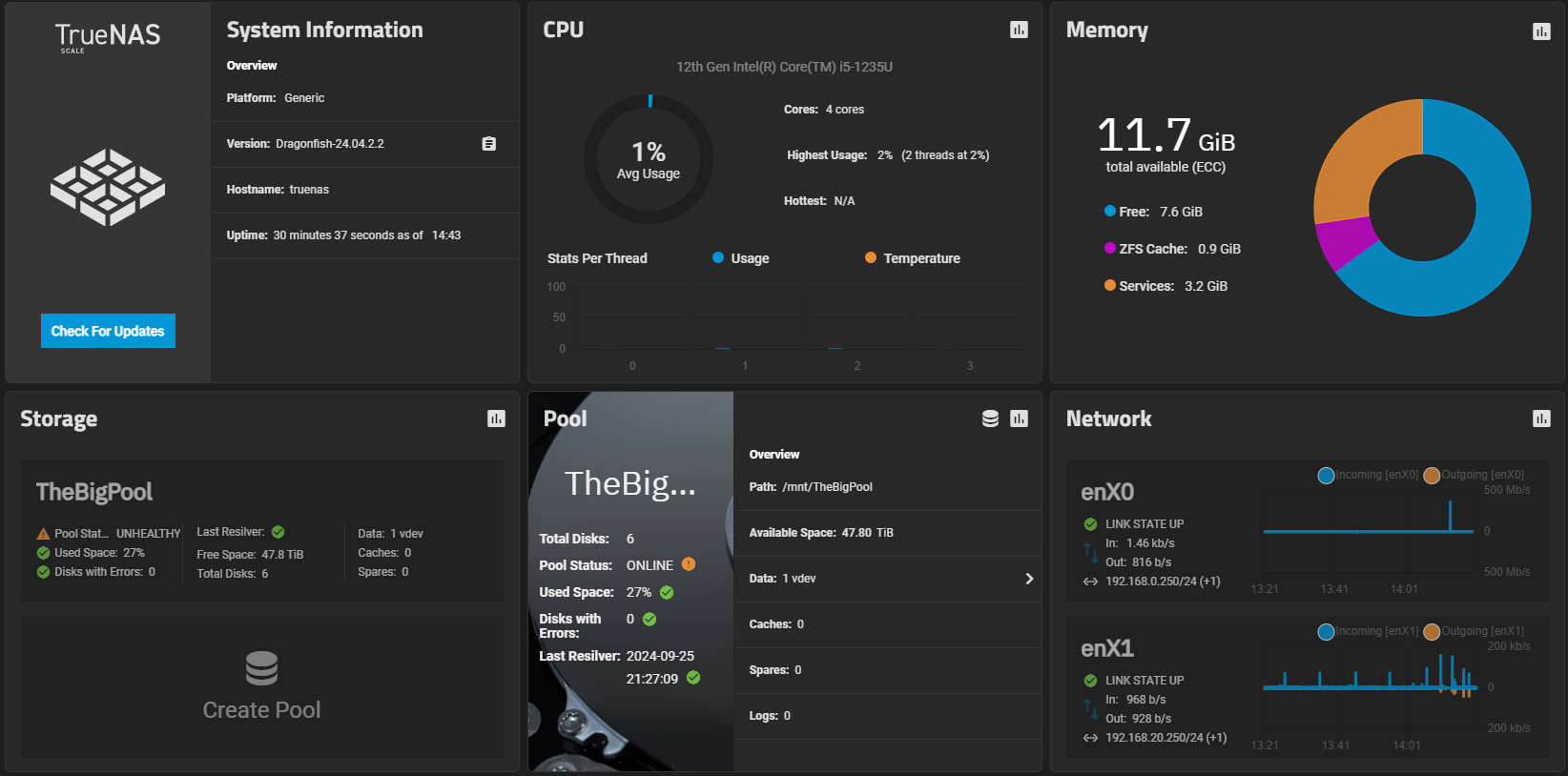
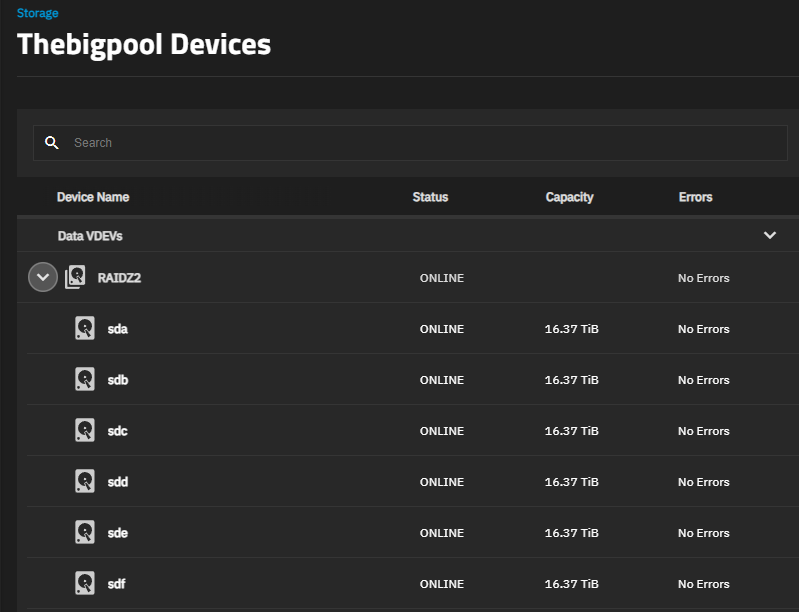
I had to replace a drive in my 6 x 18G (identical IronWolfs) raidz2 array due to sector errors. The new drive appears to have re-silvered correctly but an lsblk listing doesn’t show the raid1 (should it be 1) or crypt partitions. Searching, I found this post, but there’s no real answer given.
admin@truenas[~]$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:0 0 16.4T 0 disk
├─sda1 8:1 0 2G 0 part
│ └─md126 9:126 0 2G 0 raid1
│ └─md126 253:0 0 2G 0 crypt
└─sda2 8:2 0 16.4T 0 part
sdb 8:16 0 16.4T 0 disk
├─sdb1 8:17 0 2G 0 part
└─sdb2 8:18 0 16.4T 0 part
sdc 8:32 0 16.4T 0 disk
├─sdc1 8:33 0 2G 0 part
│ └─md127 9:127 0 2G 0 raid1
│ └─md127 253:1 0 2G 0 crypt
└─sdc2 8:34 0 16.4T 0 part
sdd 8:48 0 16.4T 0 disk
├─sdd1 8:49 0 2G 0 part
│ └─md127 9:127 0 2G 0 raid1
│ └─md127 253:1 0 2G 0 crypt
└─sdd2 8:50 0 16.4T 0 part
sde 8:64 0 16.4T 0 disk
├─sde1 8:65 0 2G 0 part
│ └─md126 9:126 0 2G 0 raid1
│ └─md126 253:0 0 2G 0 crypt
└─sde2 8:66 0 16.4T 0 part
sdf 8:80 0 16.4T 0 disk
├─sdf1 8:81 0 2G 0 part
│ └─md127 9:127 0 2G 0 raid1
│ └─md127 253:1 0 2G 0 crypt
└─sdf2 8:82 0 16.4T 0 part
sr0 11:0 1 1024M 0 rom
xvda 202:0 0 32G 0 disk
├─xvda1 202:1 0 1M 0 part
├─xvda2 202:2 0 512M 0 part
└─xvda3 202:3 0 15.5G 0 part
nvme0n1 259:0 0 476.9G 0 disk
└─nvme0n1p1 259:1 0 476.9G 0 part
admin@truenas[~]$
TrueNAS is running virtual, under XCP-ng on a ZimaCube with the SATA controller passed though to it. I’m not seeing any SMART, or indeed any other, issues with the drive, other than the partition layout.
Am I OK leaving this, or do I need to drop the drive and re-silver (again) and if so what’s the best way to do that.
I’m curious what this answer is too. I’m not sure why a ZFS setup would have anything listed as “raid” but it is there for all your drives except sdb.
Not enough information. Which drive? I’m making an assumption it was sdb.
If that is true, then you might have partitioned your original drives not using TrueNAS originally. I’m not saying that you didn’t use TrueNAS, but maybe you had partitioned them in Linux, then destroy it, and recreated in TrueNAS. It is a guessing game until you provide some better details.
TrueNAS SCALE (older versions) used mdadm + dmcrypt for the swap partitions of the storage drives.
Probably because recent versions of SCALE no longer create/use swap anymore. Yet they will still reserve 2 GiB of buffer to safeguard against a new drive not being “large enough” to replace an older drive that is “ever-so-slightly larger”.
Nope, all the 6 original drives were brand new and only had SMART Long Offline tests run on them before creating the Pool about a month ago (I know, I should have run some sort of burn-in on them, but I didn’t have 3 months to spare LOL).
There was an issue with the backplane in the ZimaCube I had which eventually caused a bunch of sector errors on 1 drive. I replaced the backplane and the replacement drive was the same, shipped as an RMA from Seagate, SMART Long Offline run on another system, and then it replaced the bad drive and re-silvered.
The original Pool was built with 24.04.2 about a month ago.
You know, I’m not too worried about HDD burning anymore for a home system provided the user builds with decent redundancy. Plus, it is like beating a dead horse.
I don’t know why you have the partitions that you have then. While I doubt (not a definite) you will have any problems, if it were me, I would backup all my data, destroy the pools, write over the partition tables (or the entire drive but 16TB is a lot of space to write over), and start all over. Also, I would create my pool(s) using TrueNAS CORE. That is me and me alone, my personal preferences. Then I would switch to SCALE. I’m certain you could recreate the pool(s) using SCALE with no issues. Then check out the partitions, are they the same?
If you have a lot of data, maybe you will just live with it and wait for another person to chime in to either agree with @winnielinnie assessment or refute it, or do some more searching on the internet.
The Pool was created with 24.04.2, the re-silver with 24.04.2.2. Are you talking between these (sub) versions.
The partition /dev/sdb1 is still tagged as a Linux swap, but not as a linux_raid_member:
xPartition UUID: 6917E2ED-C19E-4E52-BE0B-B0A983B66A8F x
xPartition type: Linux swap (0657FD6D-A4AB-43C4-84E5-0933C84B4F4F) x
For comparisoion
x Partition UUID: A5990360-250B-456F-8EEE-29974C2FF922 x
x Partition type: Linux swap (0657FD6D-A4AB-43C4-84E5-0933C84B4F4F) x
x Filesystem UUID: 74e96cb2-1a18-9ab3-5509-0fb68e908c61 x
xFilesystem LABEL: truenas:swap0 x
x Filesystem: linux_raid_member x
It’s possible (since SCALE is going through some recent changes) that not everything has been fully converted.
There is, for example:
swap being activated
a reserve space of the first partition for swap devices (upon pool creation)
a reserve space of the first partition for swap devices (upon resilvering a new drive)
While swap has been “disabled” recently (bullet-point #1), there might still be a discrepancy between pool creation (bullet-point #2) and drive resilver (bullet-point #3).
For all we know, the different partitioning schema between a newly created pool and a newly added (resilvered) drive might have been overlooked for 24.04.2.x.
The layout of top is misleading. That last column is not “available swap”. You’ll notice there’s a “period” instead of a “comma” right before that field.