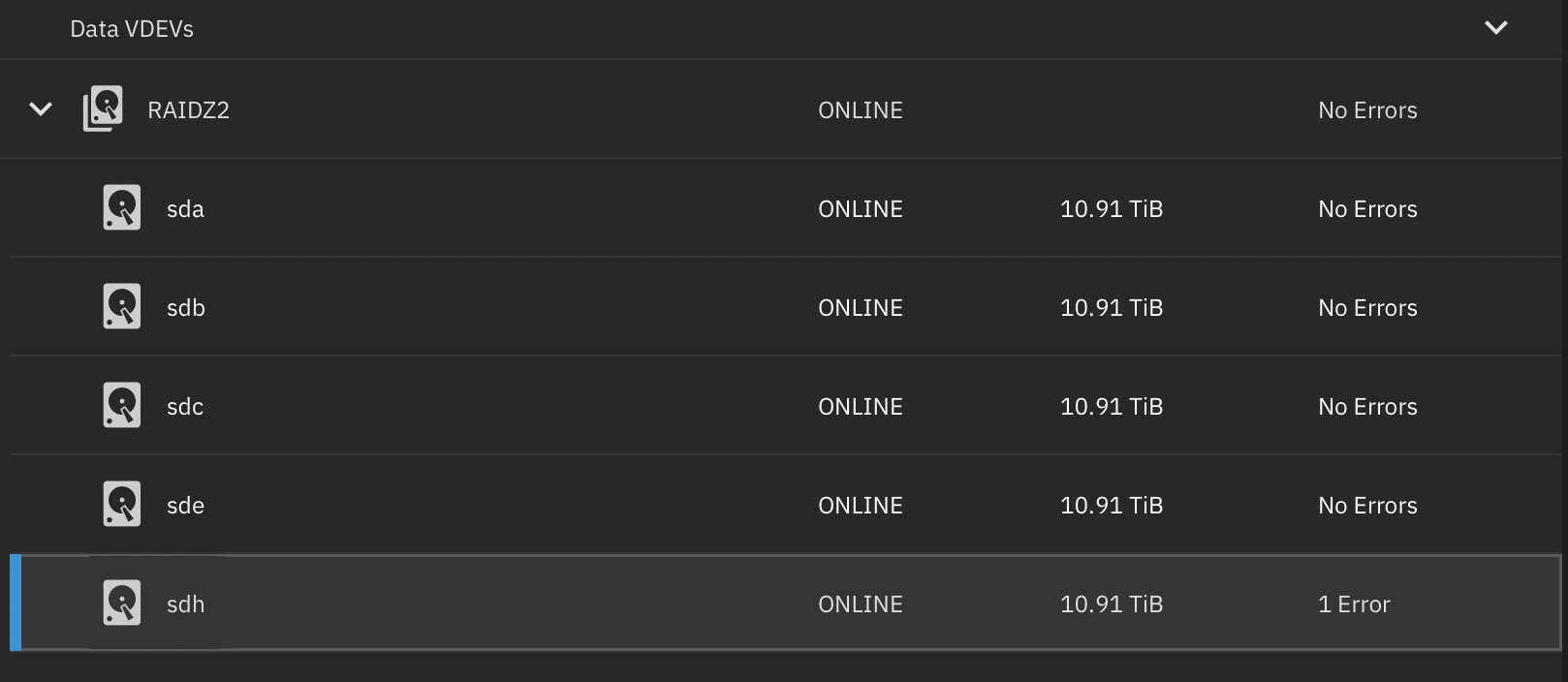
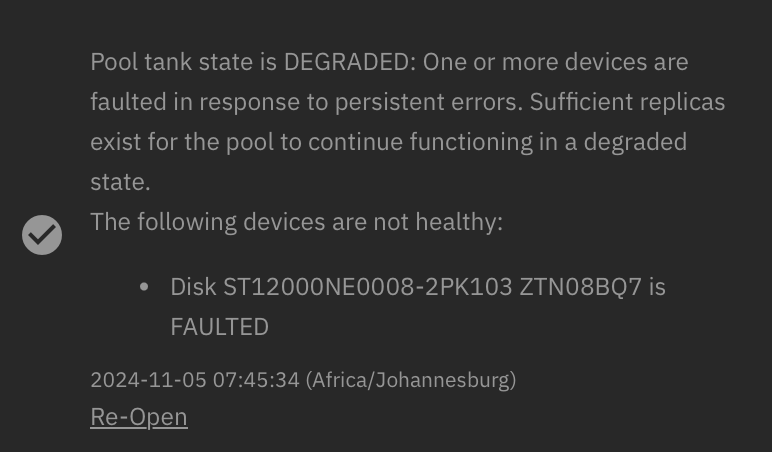
Of course, I replace my 5 x 4TB HDD (1 had errors via SMART) with 5 x 12TB to grow the Diskpool and replace that drive.
4 days after replacement 1 of the new drives are reporting a error.
I’ve run a scrub, completed. tried a single disk scan, err’s out because of error…
I’ve ordered a new HDD, different merchant (Aliexpress shop is saying never had problems… demanding I to ship back at my expense, knowing the distance time etc make it near impossible/annoyed… and trying to get AliExpress main other than the shop to respond is near impossible).
Is there a way to “mark” the ad sectors and clear the error count on the storage view?
Exactly what was the error? maybe post the entire output of smartctl -x /dev/sd? so we could see what you are talking about. This may not be anything or maybe it is something. Let us help you decide.
A SMART error and a SCRUB error are not the same thing, not unless the disk error caused significant data loss (likely only in a STRIPE).
The ONLY thing I see that is wrong is you allowed the drive to exceed the maximum allowable temperature. Your drive was at 65C, the maximum allowed is 60C. Looks like it was there for 130 seconds. This would void your warranty.
I see nothing else at all. Wait for someone else to verify I read the data correctly before you do anything at all. If my data is correct, I would continue to use the drive, that is my advice.
You do need to figure out how to keep those drives cool.
I marked up the text file and placed an asterisk ‘*’ in column 1 to denote what values I typically look at. This is the starting place and some of the other data may be relevant for other failures.
First: you have a Seagate drive so ID 1 and 7 have to be converted, these numbers at face value can be ignored unless you have other errors and then I’d convert those into a useable number. Here both are zero errors.
All the other marked values look good. I don’t like ID 195 however that just means the drive is doing what it should. If you had any other data related problems then would look at it harder however that is not the case.
You should run a SMART Long Test, something not done yet to first verify your drive is working. That should have been your very first test on each drive. Then run badblocks to test the drive for writing issues, followed by another SMART Long test. And that would complete it in my book.
hi there.
some questions…
thanks for the above.
re the SMART, it always failed previously due to errors on record, going to schedule one for tonight for this drive.
wrt badblocks… can that be run on a drive thats part of a disk pool ? just asking…
These 5 drives was to replace a previous set… so did not really have any open power/SATA ports to connect them and run tests. i needed to offline old drive… remove, install and do replace… guess i could have offline’d old drive… install, run tests and then do replace.
i have a modular power supply so trying to get additional/3rd SATA power cable.
Also have an addition 1015 LSI controller, but not been able to flash that to IT mode… and discovered I have sort of a problem, no open PCI slot… as the last slot is used by a dual port 2.5GbE NIC atm to be replaced by the dual port x520 10GbE Fiber card, hopefully by end next week.
only option might be to cable additional drives into MB SATA ports, but physical space also seem to be a challenge, where the HDD would go and where the above x520 would sit, nothing is even easy…
G
Well, yes and no. Yes you can do a Non-Destructive test however the real value is in the destructive test where it write data. So I would say it is too late to run badblocks if the drive is in use.
An option to test your drives all at once (provided there is no heat issue), you can power down, remove your drives, including the boot drive. Install your new drives and install TrueNAS to a USB Flash drive. Boot from the new flash drive and then run the badblocks tests on all the drives at once using tmux, @NugentS has posted a link above.
Depending on the capacity of the drives, it could take 1 day or 10 days to fully run badblocks on the drives. Badblocks write 4 different test patterns and verifies the data written. It takes time. Typically a 16TB drive will take 3-4 days to test, but it does depend on the drive.
If you do this then you are without your NAS for a few days. Is that something you can do? An alternate method which I don’t really care for, purchase an external USB case, or if you have an available SATA data connection, an external SATA drive case. Pay attention to the connectors, external SATA connectors are a little different and you may need an adapter cable. I have one of these and it works great. Not sure I would test individual drives this way, it would take a long time, but it is very doable.
You can take any old computer, boot up an Ubuntu Live CD, or other Live CD, and run badblocks from there. Think about it, one CD-R drive, one CD with Ubuntu Live, and then you connect up your drives to be tested. For those folks who have old computers just sitting around.
Also, just to be clear, do not run badblocks on SSD/NVMe drives. You would be using up the wear level (life) of these devices.
ok, looking at the 2 files… give me a second here… these are 2 different drives…
i need to get my bearings… see if the original file/drive/log uploaded was the wrong drive stats… brb