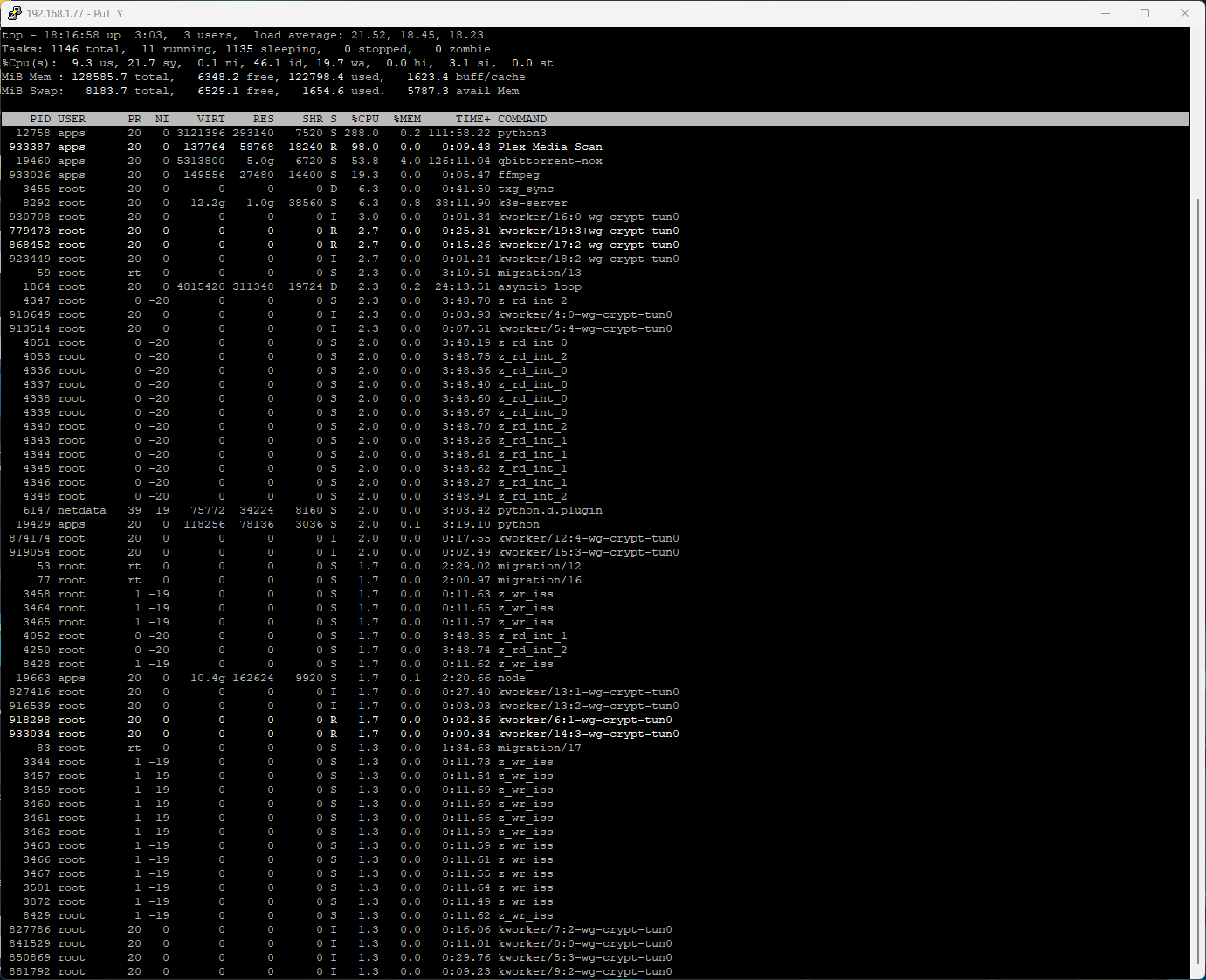
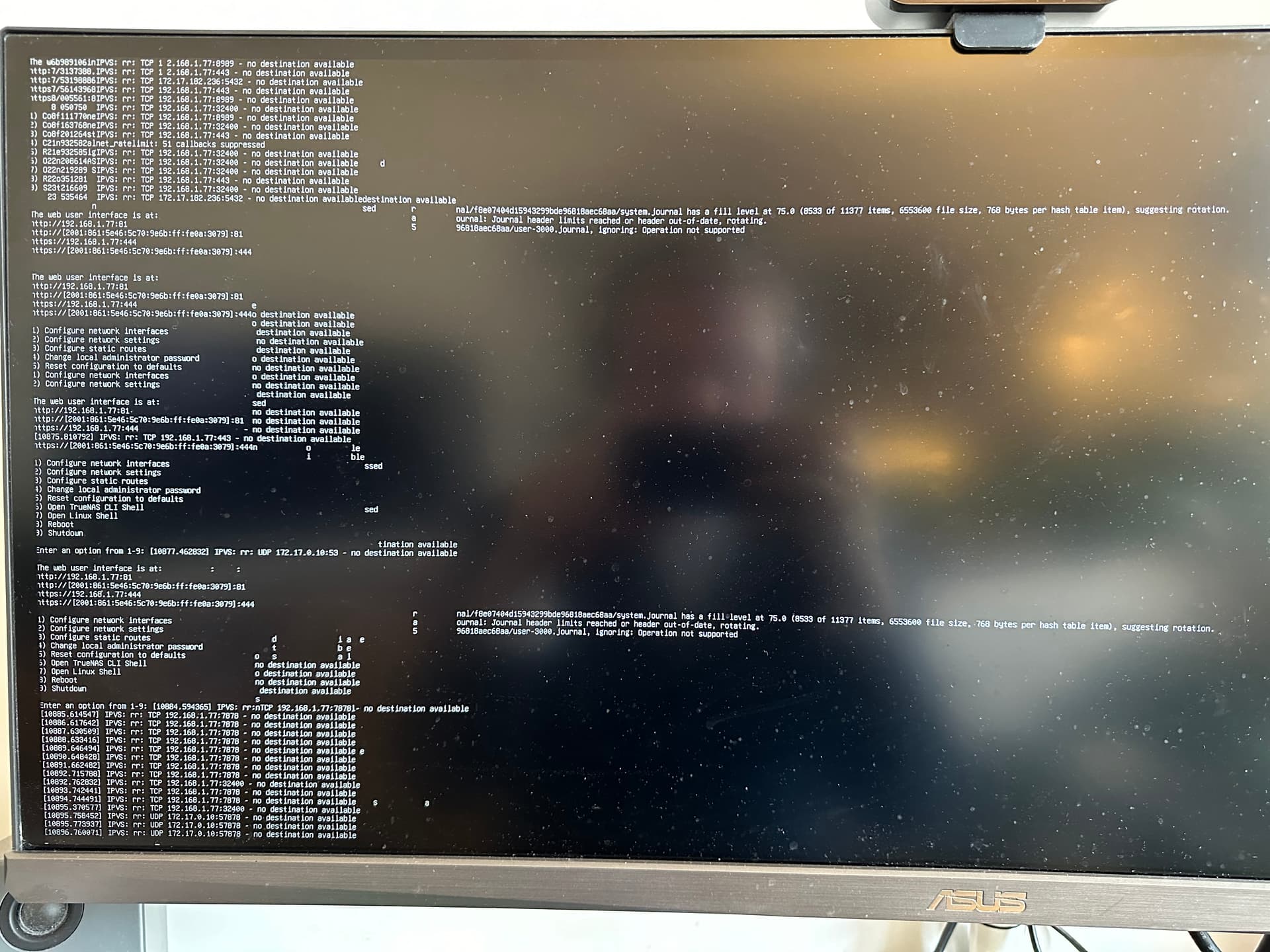
After having re-installed a fresh copy of dragonfish 3 times for various buggy issues, I am once again in a situation where the webui just dies. Eventually my uptime monitors start to fail and then downtime happens for a few seconds for the apps.
An hour after booting the system, the webui no longer loads. “Connecting to TrueNAS …”
SSH still works but slowly, running heavyscript to list apps fails. Killing all apps seems to get the webui back but that is obviously not the solution. Leaving a page open on the apps UI shows the cpu/ram usage still updates but all kubernetes events no longer load, so I suspect there is something there.
I am going insane, this is supposed to be an enterprise platform. Stability should be fundamental. Last week I spent 5 days debugging a custom app qbittorrent client that refuses to work on dragonfish, and now the system just randomly dies?
I don’t understand, is this where I give up and go to a competing platform? Anyone have an idea on how to fix this? Do I need to re-install again so it runs for a few days before dying again?
I’ve run into similar problems, where SCALE would become completely unresponsive after updating to Dragonfish. by any chance, are you using NFS extensively? because I solved it by swapping all my NFS app shares to HostPath. (actually after doing this, I turned off the service completely in the UI).
in my console output I had a bunch of errors about NFS so I guessed it was worth a try.
but I can’t see anything related to NFS in your errors so not sure.
Same here. Only using SMB with Proxmox and a few apps using PVC. I just read about NOT using PVC storage and ill be switching to host path soon. rebooting the NAS (not a good option) works for a few days then the UI is SLOW again and unusable. going back a version to 23.10 works well for many weeks
Did you reboot after applying this parameter? I don’t believe Linux is just going to retrieve swapped pages back into RAM just because the ARC size suddenly shrank.
I would persistently apply the “back to 50% default” parameter, then reboot, and then see if the problem re-manifests after some usage.
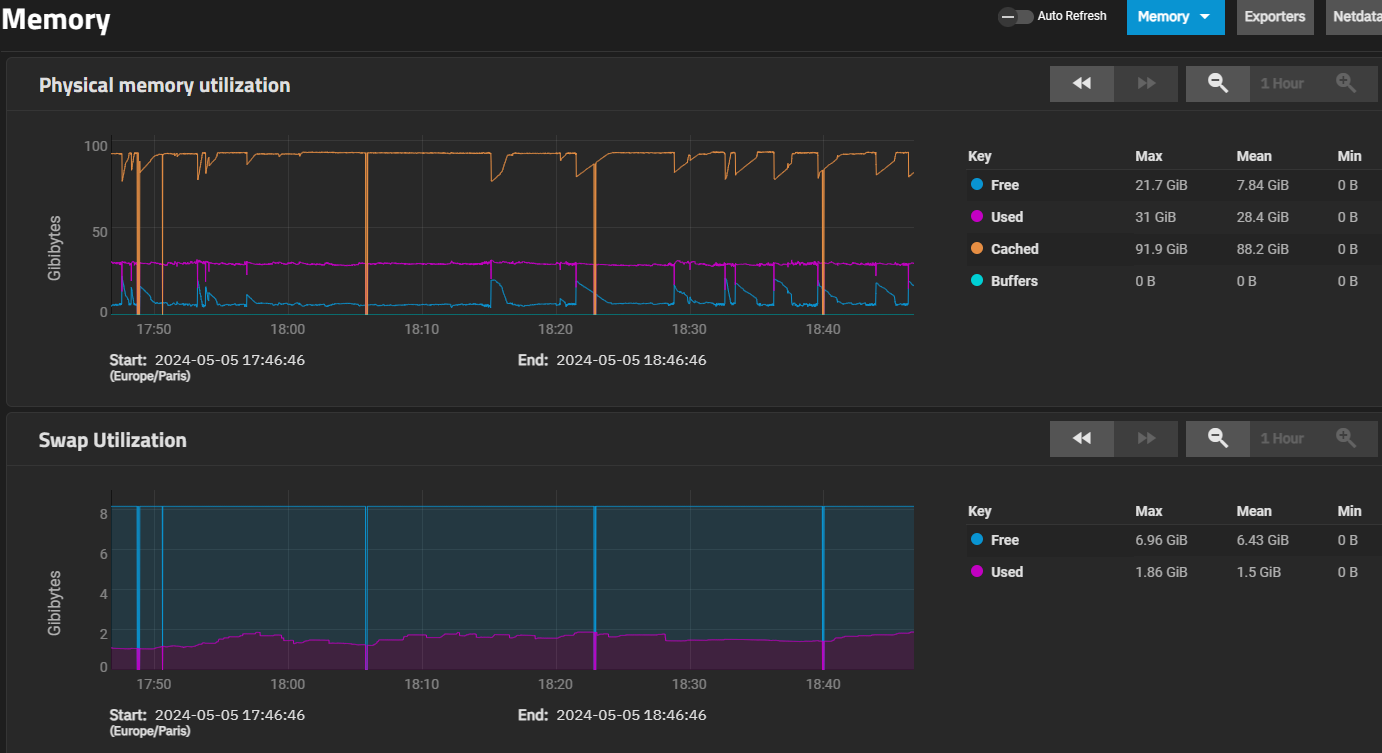
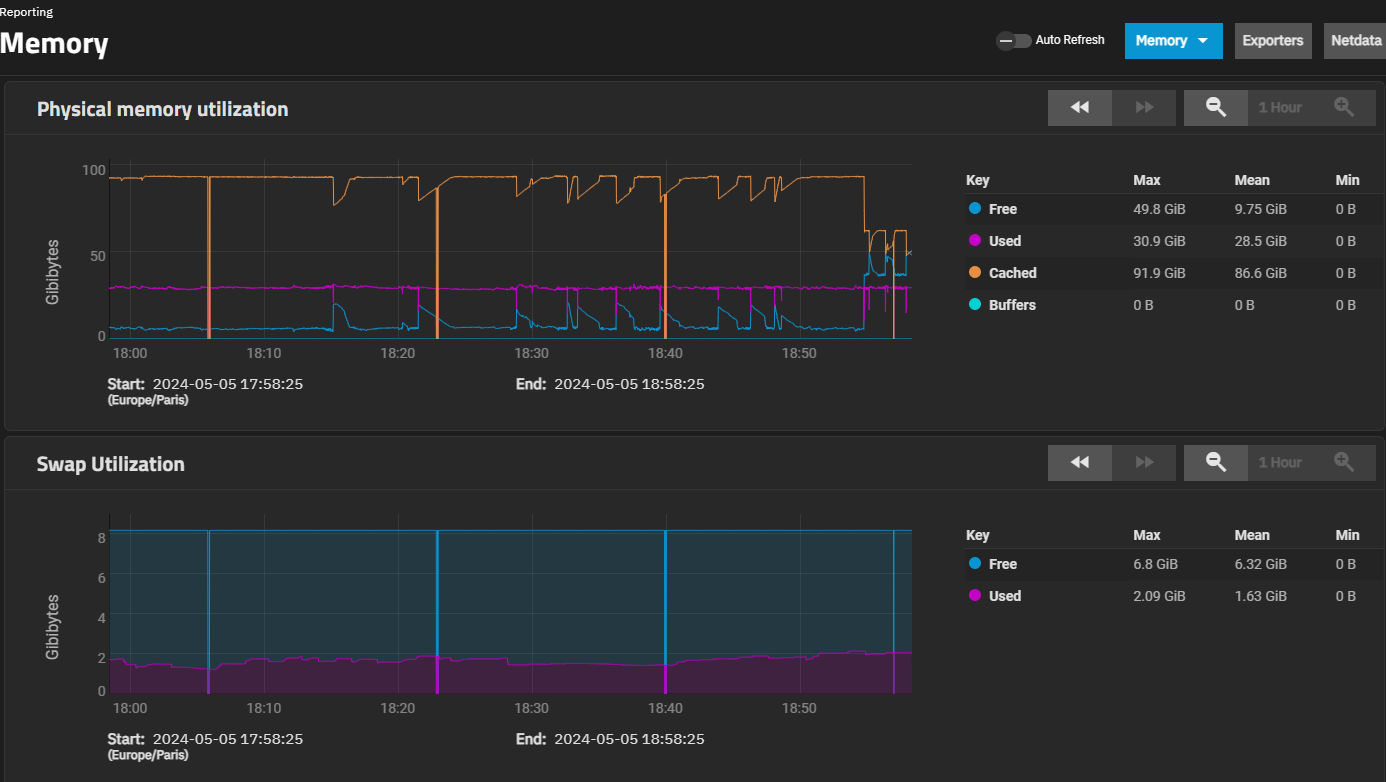
My system has always showed some swap usage even though plenty of ram, on any Scale version. Current show 33GB free memory, yet, a couple GB swap usage as always.
@pinoli not using NFS, only SMB but manually to look at the file system from my windows pc. @Dave I am not using any PVC storage, only host paths. @winnielinnie did not reboot yet, will do and report back
similar behavior to me; and I am seeing more and more similar issues popping up, which made me believe it’s scale 24 bug. Although this is my first TrueNas experience, I haven’t extensively tested it before on 22, 23 , and 24RC1, didn’t show this behavior before until I was committed and went with 24 and started really using it.
I “suspect” without any evidence that could be the way they tuned dragonfish to leverage RAM dynamically, and eventually some memory leak or bug will occur during this dynamic adjustment.
When your Web UI locks up, your swap usage is almost identical to mine about 1.6GB/8GB . I have 1TB RAM and locks up when 900ish GB ARC and with 5% total RAM left(50~60GB FREE). and I will see “asyncio_loop” start to chewing up swap. You can monitor it by going to top, enable swap monitor with “f”, and “s” to sort based on swap usage.
I was really trying to avoid this, using everything stock, and debugging, but at some point need to give in to the “hacky” approach, bit sad
For those looking for a similar solution. Add this to your init/shutdown scripts:
echo 68720000000 >> /sys/module/zfs/parameters/zfs_arc_max
Add it at post-init
Adjust the number 68720000000 to the ram amount you want to assign. 68720000000 is in bytes, and in my case equals 64 GiB. Use wolfram alpha for your own calculations
The irony is that the “hack” was overriding the default of 50%. Prior to Dragonfish, SCALE followed OpenZFS’s upstream default of the 50% limit.[1] So in a sense, you just set it back to the default behavior.
@SnowReborn: Did you try this, followed by a reboot? Change the numbers accordingly to tailor to you’re system’s total physical RAM:
UPDATE: To simplify resetting it to the default, without having to calculate 50% of your RAM, you can set the value to “0” in your Startup Init command, and then reboot.
echo 0 > /sys/module/zfs/parameters/zfs_arc_max
You might have better luck with a “Pre Init” command.
If that doesn’t work, then go ahead and manually set the value in your Startup Init command. See @cmplieger’s post above.(You might not be able to “set” it to “0”, since SCALE likely sets it to a different value shortly after bootup. And it doesn’t accept setting it to “0” on a “running system”.)
Nevermind. Only use @cmplieger’s method to return to Cobia’s bevhaior. See this post as to why.
Maybe for some, but there are other reports like this one where there is tons of free ram. I saw a few posts somewhere where people have even reset the arc to default 50% and the problem still occurs. The thread below has several examples which indicate a different issue perhaps, but still manifests in the UI. Hopefully they can find the issue(s).
I know, agree of course. Whether or not they have, someone has to follow up. But that other thread is much more concerning to me as it indicates more of a middleware problem. I mean a guy with 1TB ram and tons and tons of free memory even? Hopefully enough bug reports will be filed to assist IX in finding the culprit(s).
I certainly wouldn’t be surprised if arc played a role in some of them. The conditions of how/when that happens could hopefully be sorted one day. It’s one reason I will keep my swap space for those memory issues temporarily needing to be resolved. But many of these reports indicate it may be something else too. High middleware CPU, just sitting there? I believe I even saw other reports of a middleware memory leak too. Might be many issues.
Don’t forget in the Beta, many people did not experience these issues too. So, it shouldn’t be a case of it’s a problem for all. Some did, like Truecharts documenter.