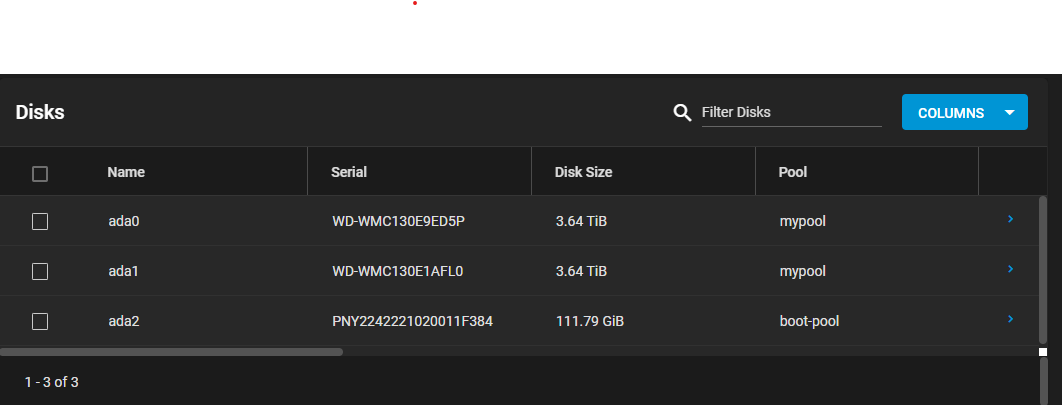
I have a disk (ada0) that is degraded but it is still usable. I went and brought a new disk (ada1) and added ada1 as the mirror. Truenas resilvered successfully somehow. No data loss (yay!)
Now, I need some help. ada0 is still under warranty, so I want to remove it and send back to seller for a new one
Before that, I need to prove it. So need some help on this. I want to look at why it is degraded and is it enough for seller to give me a replacement.
Anyone know what is the approach? Is it something I can do on UI, or I must use the shell? I am not familiar with running the shell.
You want to send them a screen or a copy of the smartctl error log after a long test. Do note that a checksum error on the GUI is not an indication of a drive failing.
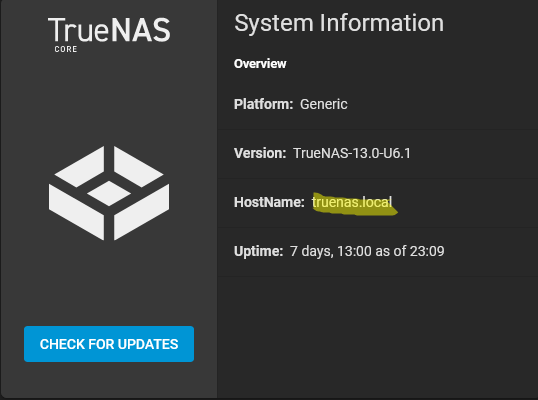
Activate the SSH service, check your system’s hostname in the dashboard (see below), and then copy it.
Then open the CMD in windows and write ssh root@truenas.local (or your hostname if it’s different). It may ask you something, accept everything and log in with the root password.
Once you are inside and see something like the following message:
Warning: the supported mechanisms for making configuration changes
are the TrueNAS WebUI and API exclusively. ALL OTHERS ARE
NOT SUPPORTED AND WILL RESULT IN UNDEFINED BEHAVIOR AND MAY
RESULT IN SYSTEM FAILURE.
Write tmux new and push enter.
Write smartctl -t long /dev/ada0 or ada1 depending on which drive you want to RMA.
Wait for the test to complete, it will take hours; you can close the CMD and do your things, as long as TN is not powered off or rebooted, the test will go on until completed.
You can access back anytime with the CMD by following the same process and writing tmux attach instead of new.
To check the progress, write smartctl -l selftest /dev/ada0: when the test is completed, you will see something like the following.
=== START OF READ SMART DATA SECTION ===
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Extended offline Completed without error 00% 2087 -
Once completed, please post the output of smartctl -a /dev/ada0.
@Stux
The warranty situation is a bit more complicated. The warrenty is actually with the seller. They sell harddrive that are out of warranty with the manufacturer.
@Davvo
I think the test is finished(?), since i see # 1 Extended offline Completed without error 00% 16075
Below result with smartctl -a /dev/ada0. It mentioned that the over health is “PASSED” - Does this mean the drive is actually fine? I don’t need to worry about DEGRADED?
root@truenas[~]# smartctl -a /dev/ada0
smartctl 7.2 2021-09-14 r5236 [FreeBSD 13.1-RELEASE-p9 amd64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Western Digital Re
Device Model: WDC WD4000FYYZ-05UL1B0
Serial Number: WD-WMC130E9ED5P
LU WWN Device Id: 5 0014ee 00400a8b1
Firmware Version: 00.0NS05
User Capacity: 4,000,787,030,016 bytes [4.00 TB]
Sector Size: 512 bytes logical/physical
Rotation Rate: 7200 rpm
Device is: In smartctl database [for details use: -P show]
ATA Version is: ATA8-ACS (minor revision not indicated)
SATA Version is: SATA 3.0, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Tue Apr 16 08:03:02 2024 PDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x82) Offline data collection activity
was completed without error.
Auto Offline Data Collection: Enabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: (47580) seconds.
Offline data collection
capabilities: (0x7b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003)
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 514) minutes.
Conveyance self-test routine
recommended polling time: ( 5) minutes.
SCT capabilities: (0x70bd) SCT Status supported.
SCT Error Recovery Control supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 0
3 Spin_Up_Time 0x0027 236 236 021 Pre-fail Always - 7200
4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 43
5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0
7 Seek_Error_Rate 0x002e 200 200 000 Old_age Always - 0
9 Power_On_Hours 0x0032 078 078 000 Old_age Always - 16084
10 Spin_Retry_Count 0x0032 100 253 000 Old_age Always - 0
11 Calibration_Retry_Count 0x0032 100 253 000 Old_age Always - 0
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 42
16 Total_LBAs_Read 0x0022 000 200 000 Old_age Always - 14720125016
183 Runtime_Bad_Block 0x0032 100 100 000 Old_age Always - 0
192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 31
193 Load_Cycle_Count 0x0032 200 200 000 Old_age Always - 11
194 Temperature_Celsius 0x0022 108 103 000 Old_age Always - 44
196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0
197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0030 200 200 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0
200 Multi_Zone_Error_Rate 0x0008 200 200 000 Old_age Offline - 19
SMART Error Log Version: 1
No Errors Logged
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Extended offline Completed without error 00% 16075 -
# 2 Extended offline Completed: read failure 10% 12342 3049407010
# 3 Extended offline Completed: read failure 10% 12316 3055598006
# 4 Extended offline Interrupted (host reset) 60% 12074 -
2 of 2 failed self-tests are outdated by newer successful extended offline self-test # 1
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay.
I also forgot to mention. I get these email alert from the nas:
TrueNAS @ truenas.local
The following alert has been cleared:
* Pool mypool state is DEGRADED: One or more devices has experienced an error
resulting in data corruption. Applications may be affected.
The following devices are not healthy:
* Disk WDC WD4000FYYZ-05UL1B0 WD-WMC130E9ED5P is DEGRADED
Current alerts:
* Device: /dev/ada0, Self-Test Log error count increased from 0 to 1.
* The following system core files were found: rrdcached.core. Please create a
ticket at https://ixsystems.atlassian.net/ and attach the relevant core files
along with a system debug. Once the core files have been archived and attached
to the ticket, they may be removed by running the following command in shell:
'rm /var/db/system/cores/*'.
Also in the Truenas UI alert:
Pool mypool state is DEGRADED: One or more devices has experienced an error resulting in data corruption. Applications may be affected.
The following devices are not healthy:
Disk WDC WD4000FYYZ-05UL1B0 WD-WMC130E9ED5P is DEGRADED
That means you are not out of the woods yet…
There are no bad sectors (pending/reallocated) but non-zero Multi-Zone is not good. This could be a bad cable or a misbehaving controller though.
@Davvo
Thanks you so much. I will contact the seller.
@etorix
Here is the output of zpool status -v mypool. This does look worrying.
root@truenas[~]# zpool status -v mypool
pool: mypool
state: DEGRADED
status: One or more devices has experienced an error resulting in data
corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the
entire pool from backup.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-8A
scan: resilvered 530G in 03:52:00 with 20 errors on Sun Apr 14 15:30:14 2024
config:
NAME STATE READ WRITE CKSUM
mypool DEGRADED 0 0 0
mirror-0 DEGRADED 0 0 0
gptid/ae061260-743a-11ee-84ff-1c6f65f98779 DEGRADED 0 0 40 too many errors
gptid/26b96453-fa8e-11ee-8173-1c6f65f98779 ONLINE 0 0 40
errors: Permanent errors have been detected in the following files:
mypool/.system/rrd-b85043590a434da692c02c2416a40e36:/localhost/nfsstat-client/nfsstat-mkdir.rrd
mypool/.system/rrd-b85043590a434da692c02c2416a40e36:/localhost/df-mnt-mypool-J/df_complex-reserved.rrd
mypool/.system/rrd-b85043590a434da692c02c2416a40e36:/localhost/zfs_arc/cache_size-mru_ghost_size.rrd
mypool/.system/rrd-b85043590a434da692c02c2416a40e36:/localhost/zfs_arc_v2/gauge_arcstats_raw_hash-hash_collisions.rrd
mypool/.system/rrd-b85043590a434da692c02c2416a40e36:/localhost/cpu-2/cpu-interrupt.rrd
mypool/.system/rrd-b85043590a434da692c02c2416a40e36:/localhost/cpu-2/cpu-nice.rrd
mypool/.system/rrd-b85043590a434da692c02c2416a40e36:/localhost/cpu-4/cpu-idle.rrd
mypool/.system/rrd-b85043590a434da692c02c2416a40e36:/localhost/cpu-4/cpu-user.rrd
mypool/.system/rrd-b85043590a434da692c02c2416a40e36:/localhost/cpu-5/cpu-idle.rrd
mypool/.system/rrd-b85043590a434da692c02c2416a40e36:/localhost/cpu-5/cpu-user.rrd
mypool/.system/rrd-b85043590a434da692c02c2416a40e36:/localhost/cpu-6/cpu-user.rrd
mypool/.system/rrd-b85043590a434da692c02c2416a40e36:/localhost/cputemp-3/temperature.rrd
mypool/.system/rrd-b85043590a434da692c02c2416a40e36:/localhost/ctl-tpc/disk_time-0-0.rrd
mypool/.system/rrd-b85043590a434da692c02c2416a40e36:/localhost/df-mnt-mypool-J/df_complex-free.rrd
mypool/.system/rrd-b85043590a434da692c02c2416a40e36:/localhost/df-mnt-mypool-J/df_complex-used.rrd
mypool/.system/rrd-b85043590a434da692c02c2416a40e36:/localhost/disktemp-ada0/temperature.rrd
mypool/.system/rrd-b85043590a434da692c02c2416a40e36:/localhost/disktemp-ada1/temperature.rrd
Additionally, I strongly suggest setting up periodic long tests on all your drives in order to not get the short stick all of a sudden. You can do so on the WebUI.
I use weekly long tests (and daily short ones, but I am a bit overzealous) alongside @joeschmuck’s Multi-Report.