I am currently looking for an HBA upgrade for my server that is running TrueNAS-13.0-U6.1.
*** Had to butcher the links, because it only allowed me 2, which makes it impossible to explain, sry ***
There are multiple reasons I want to switch to a different/better model than my LSI 9300-16i. First of all, I want to get all my disks on one PCIe slot to avoid possible future problems I may encounter when troubleshooting a virtualized TrueNAS instance on my Unraid server. I split my HBA into two separate IOMMU groups, which were handled differently by the hypervisor. Currently, I have everything scattered over the LSI the onboard HBA (4 Sata, 1x slimsas-> 4x Sata = total of 8) and I even had one of these (apparently dangerous because JBOD) adapters to get another two sata port from the m2 wifi slot. Next to that I was not totally happy with the upgradability/expansion of the system, because I was already on the edge with sata and even pcie ports while not even fully utilizing the pcie bandwidth. With that being said, to clean up my drive mess I want to put all these drives on one single HBA and into an old office computer (something like a 4th gen i7) and test the existing components for a week to ensure long time stability (and avoid bugs created by virtualization).
So, I did a few days of research and figured out that there are basically no HBAs with more than 24 internal ports (through using the SAS/SFF to SATA cables). What I found are the following types of expanders that are apparently being used to multiplex the signal to multiple ports: /www.ebay.com/itm/165350815615
Or this: HBA Expander 2
And after finding these types of products even more questions came up that I didn’t find a definitive answer too:
- Is the setup different on TrueNas (this one is easy
 ): there was literally no set up for the LSI 9300 I am currently using. So, my guess is the same with eg. this HBA: /www.ebay.com/itm/166481101887 + the Expander card → Just put it in a slot and it works ?
): there was literally no set up for the LSI 9300 I am currently using. So, my guess is the same with eg. this HBA: /www.ebay.com/itm/166481101887 + the Expander card → Just put it in a slot and it works ? - How do I wire these up ? I couldn’t find dedicated wiring diagrams (only YT videos) which explain how to put the expander together with the HBA into a PCIes. According to videos and the official documentation, I did a hypothetical wiring diagram, so how I understand it works like the following:
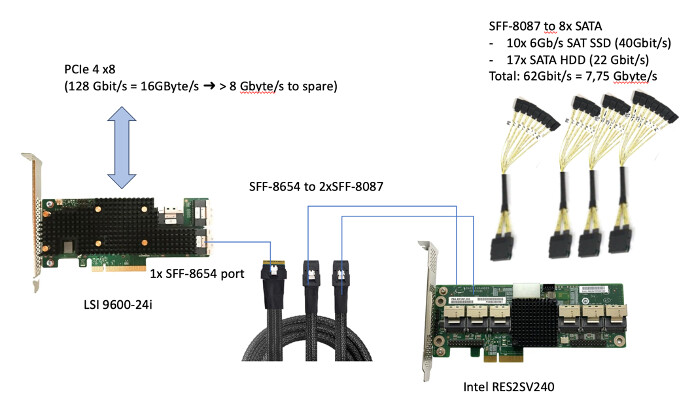
Basically, I want to be able to attach 32 SATA devices while having spare SFF ports for (potential) U.2 drives. Of these 32 two SATA devices I want to utilize 18 ports with HDDs (2x pools (one x15 + one x2) + a hot swap) and 13 ports with SSDs (1x pool + 1x hot spare) while having one port to spare. Would the wiring work as I illustrated? So basically, my idea was to adapt the one big SFF (8654) to two smaller ones (8087) that are both connected to the expander. I read that these expanders basically work like unmanaged switches. So, my idea was to use the ports as either inputs or outputs on this model, am I wrong with this? In another video I saw that two slots were marked as inputs but not on the two models I linked above. Are there always two inputs? Can Passthrough be a problem?
I only found one source for the SFF 8087 to 8x SATA. Are they reliable/ a potential bottleneck ?: /www.datastoragecables.com/sas/internal/minisas68-satax8/
- So talking speeds, assuming I have a lot of HDDs and a bunch of SSDs (as illustrated above), I come up to a needed bandwidth of about 62Gbit/s = 7.75Gbyte/s. While the PCIe Gen 4 x8 slot should have plenty of bandwidth left I am curious about the cables, the expanders and most importantly the SFF 8654 port. Will the system bottleneck when connected to only one SFF 8654 port of the HBA ? Hooking up hypothetically only SSDs would bottleneck the system by 2.25 times by the PCIe (36Gbyte/s needed / only 16 Gbyte/s). Would the number be way lower because of only using one SFF port (so not 1/3 b.c. 3 ports but for example 1/4 of the PCIe speed available) ?
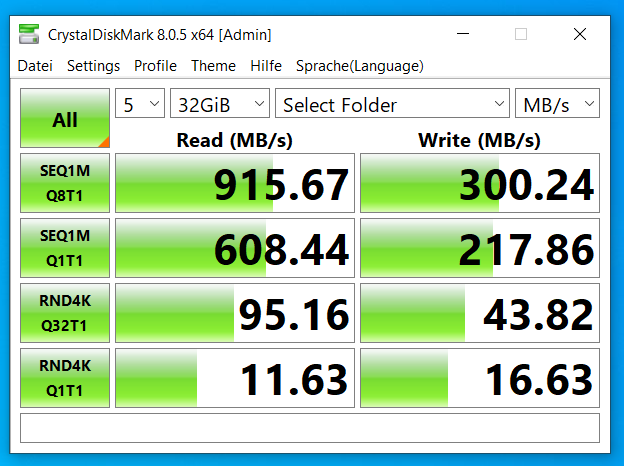
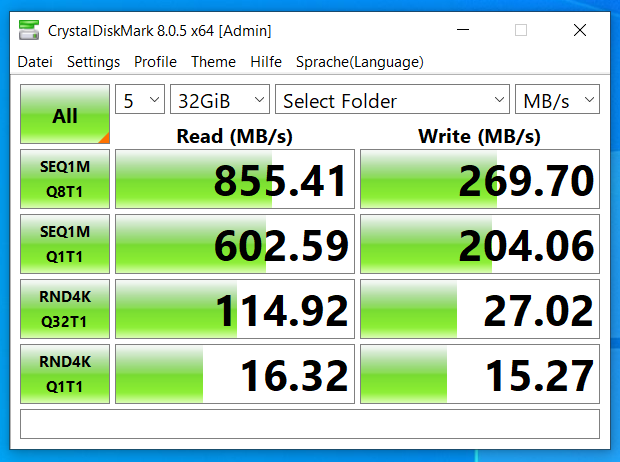
- Why only one SFF port ?? → I am currently using (oh boy here it comes) SLOGs, L2Arcs and Dedups for my system to tinker around with. I know this is a big discussion point where lots of experts just say: Avoid it. You won’t benefit from it either way ! BUT I want to make up my own mind on this and I think there is a good chance to see a difference on a system with >30 drives. Especially Dedup has good potential to save a few percents of storage while not losing performance because I only need to compute that I already had on my system (replicated from: /www.youtube.com/watch?v=KjjSJJLKS_s&t=666s.
I want to use the SLOG for a bunch of other VMs I want to deploy and see if I benefit from it, but rn it is more experimental for me.
For now, my Dedup as well as my SLOG for the ssd mirror vdevs is placed on two intel optane p900. I didn’t split them on separate devices because I lack the PCI lanes for that. And it would be a big waste of NVME considering the SLOG “only” gets 10Gbit data in. The main problem is that it works well for my mirror vdevs but not my RAIDz2 main storage pool, because I am lacking the 3rd NVME for the redundancy rule. My idea was to switch to these: U.2 SSD
Which have the same speeds as these: /harddiskdirect.com/ssdped1d015tax1-intel-optane-ssd-905p-series-1-5tb-pci-express-nvme-3-0-x4-hhhl-solid-state-drive.html?srsltid=AfmBOoqnCqqRmN8-O0aVa2a2e5e84q5Xx0heQeDLwXljfk1BEHGSPvb63vQ
But are way cheaper. I could attach these to the left-out slots of the HBA easily with SFF8654 to 4x U2 cables. Could the xPoint/U2 compared to HHHL be a problem? Speeds are the same but what about IOps (ARK says it’s the same if I didn’t see it wrong)? Are these types of drives not suitable for SpecialVDEVS, LOGs, Dedeups ? From what I saw they are good for this use case, but I am not sure.
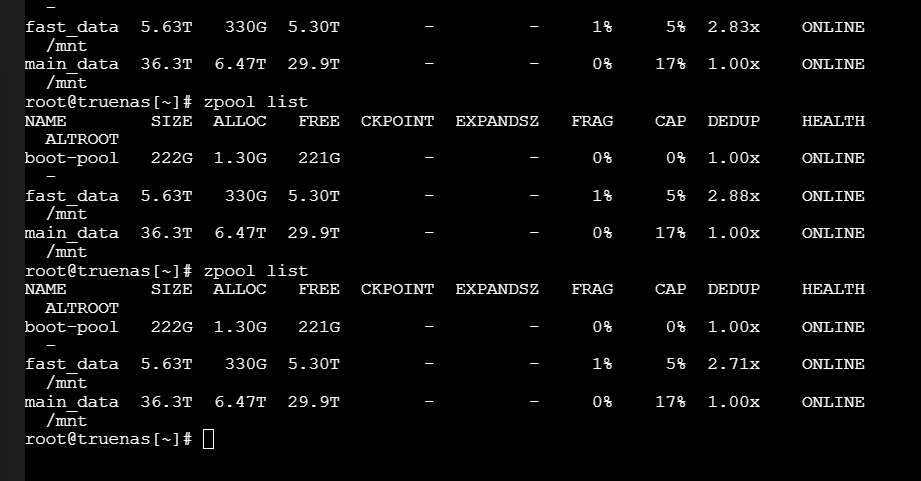
So, considering the intel U2 drives I could easily expand my SpecialVDEVs while keeping the same, if not higher, integrity layout (potential RaidZ2 or mirror with 4 drives). Next to this the space requirement is also getting big for a capacity up to potentially 150TB for my potential main pool (15x 20TB RaidZ2 x3 approx = 150TB net) with 1GB of Dedup for 1TB space.
-
Bottlenecks: These LSI cards can actually connect up to 240 Sata devices which even would bottleneck with only HDDs attached (assuming 0,16 GB/s * 240 = 38,4 GB/s > 16GB/s from the PCIe). Not even talking about all SSDs or the supported 32x NVME/SAS devices. In my setup I don’t mind bottlenecks as long as they are symmetric aka all drives are basically relatively bottlenecked to their native speeds. If I would for example attach 4x or even 8x U2 drives over the two left-out SFF8654 and use these under full load in VMs (not the network) and it makes the “Main” hdd storage pool unusable, then this would render the whole idea useless for my case. Has someone experience with the bottlenecks of these cards? How does ZFS/ TrueNAS handle this ? Is it bad for SpecialVDEVs to put them on shared PCIe connections? We are still talking about Gigabytes per second that could be potentially reached for each separate pool and VDEV (so still NVME/PCIe speeds that would be theoretically available).
-
Another simple one: Do all of these SFF Expanders only need power over PCI ? I don’t have any slots left that is why I want to put this card on an external powered PCI slot. Could that lead to problems? Advice ? Big no-go ?
-
How can I verify the source/quality of the HBA that I want to buy on e.g. ebay? Can I validate that it is not a cheap dupe? Can I test the hardware myself to verify that ?
-
Suggestions for alternative ways ? How is my general idea ?
A few more comments:
- I am currently very restricted with PCIe because I am using Intel consumer CPUs. That is why I want to only use one x8 Gen5/4 slot for all my storage (my guess is there is no Gen5 HBA yet and it will also be unaffordable for me)
- I want to try out the SpecialVDEVs features of TrueNAS on bare metal by myself and see what I could potentially use long term. I can always switch between no SLOG, Dedup through the use of backup to a second server and a recovery afterwards, while keeping all my data and the file structure. And I will do a backup either way.
- I would be glad about links/documentation etc. I researched a lot already and want to tick off boxes that potential experts can answer quickly. Sorry, if I overlooked something major, especially in this forum.
I know this is a long post, but I really want to know as much about this type of HBA before I invest in hardware that will cost me hundreds short term (if not thousands long-term) of dollars. I would be glad about any flaws pointed out by experts or better suggestions on how to solve this.
I really found the community very helpful in my last post which is why I came here and didn’t just go to an arbitrary subreddit or other forums.
And btw here is the whole reason for the 1x HBA → a lot of drives story:
/forums.truenas.com/t/truenas-core-cant-execute-smart-check-not-capable-of-smart-self-check-resulting-in-bug/681/39
Thanks in advance ![]()