It depends on the size/alignment of the writes vs the underlying block size.
Read-modify Write is needed for small writes… not good for Z1 configs.
It depends on the size/alignment of the writes vs the underlying block size.
Read-modify Write is needed for small writes… not good for Z1 configs.
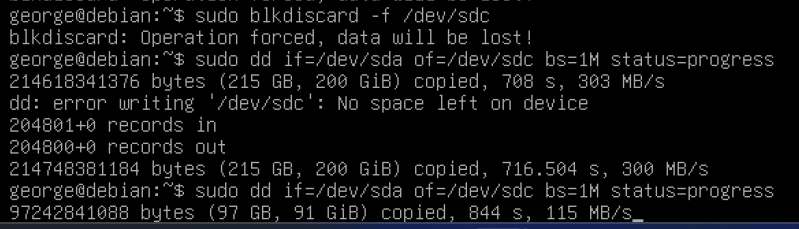
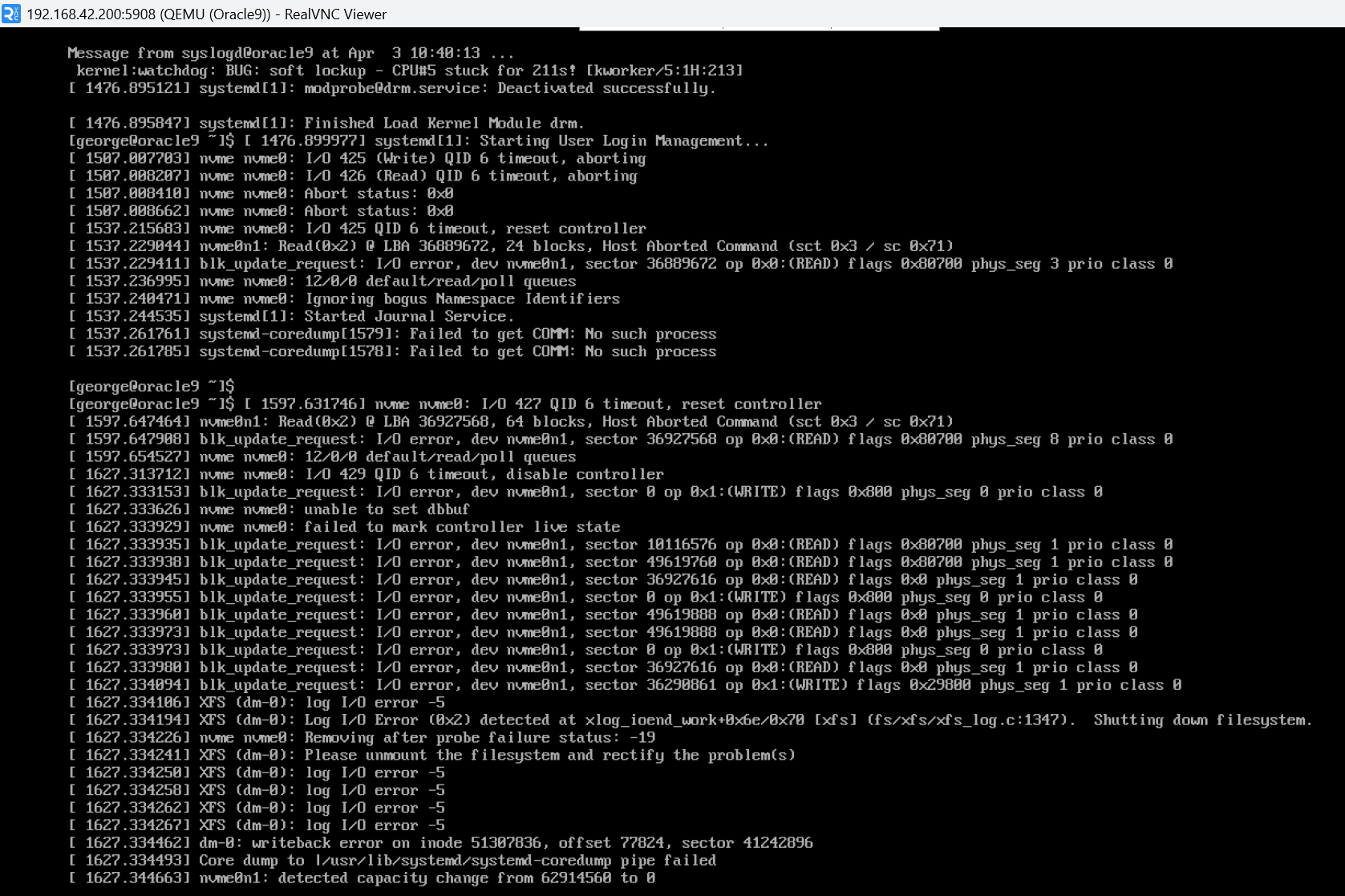
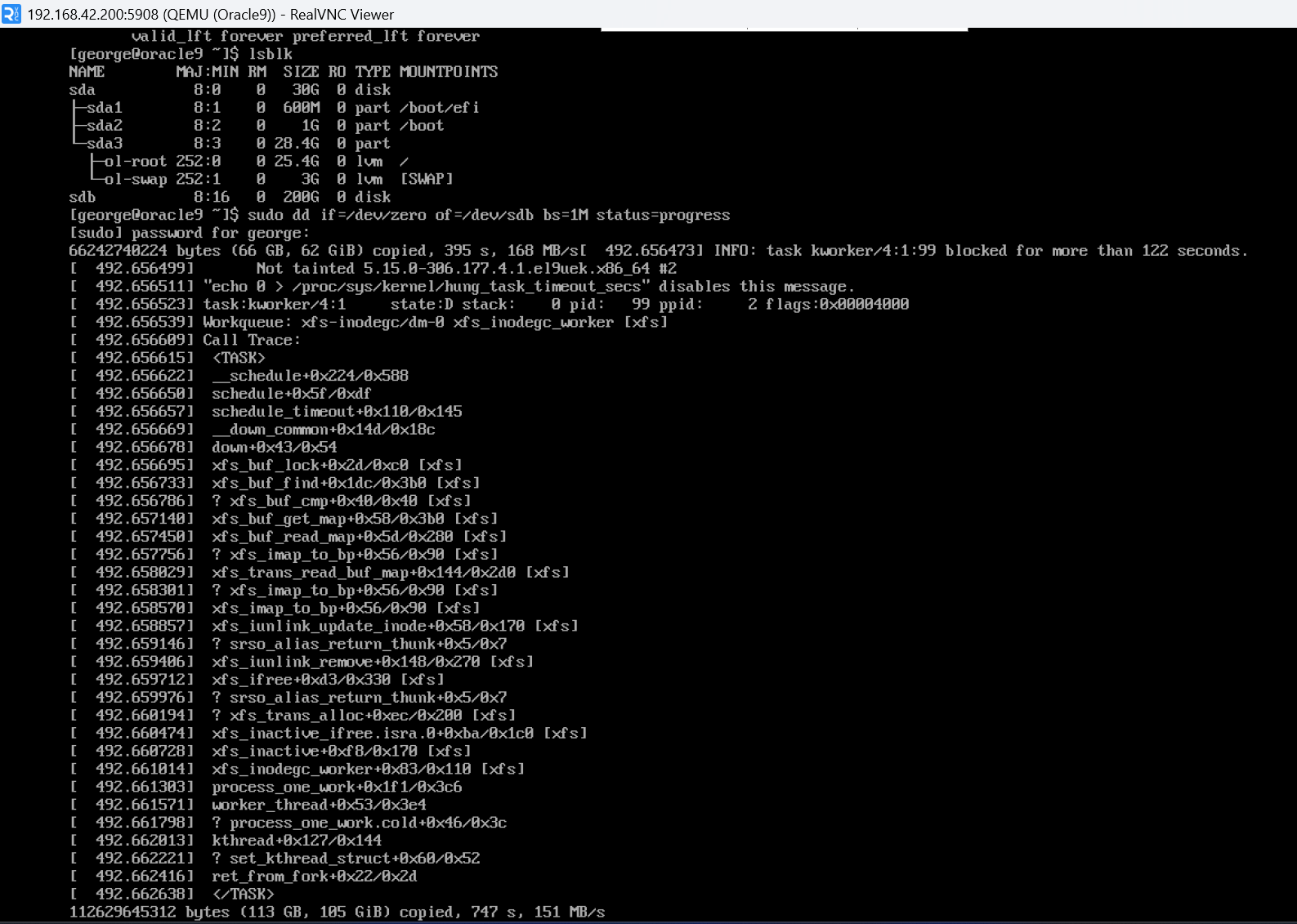
I’m doing 1MB block sizes, so that shouldn’t be the issue. I flipped the script and went sda to sdc (backed by the 3vdev pool of mirrors) and it’s still having the same issue.
I’m pretty confident this is just wrong.
Writing zeros with compression and sync = disabled is an edge case. Its a like car driving down a hill with no brakes - there’s not much to write and there’s nowaiting for acks.
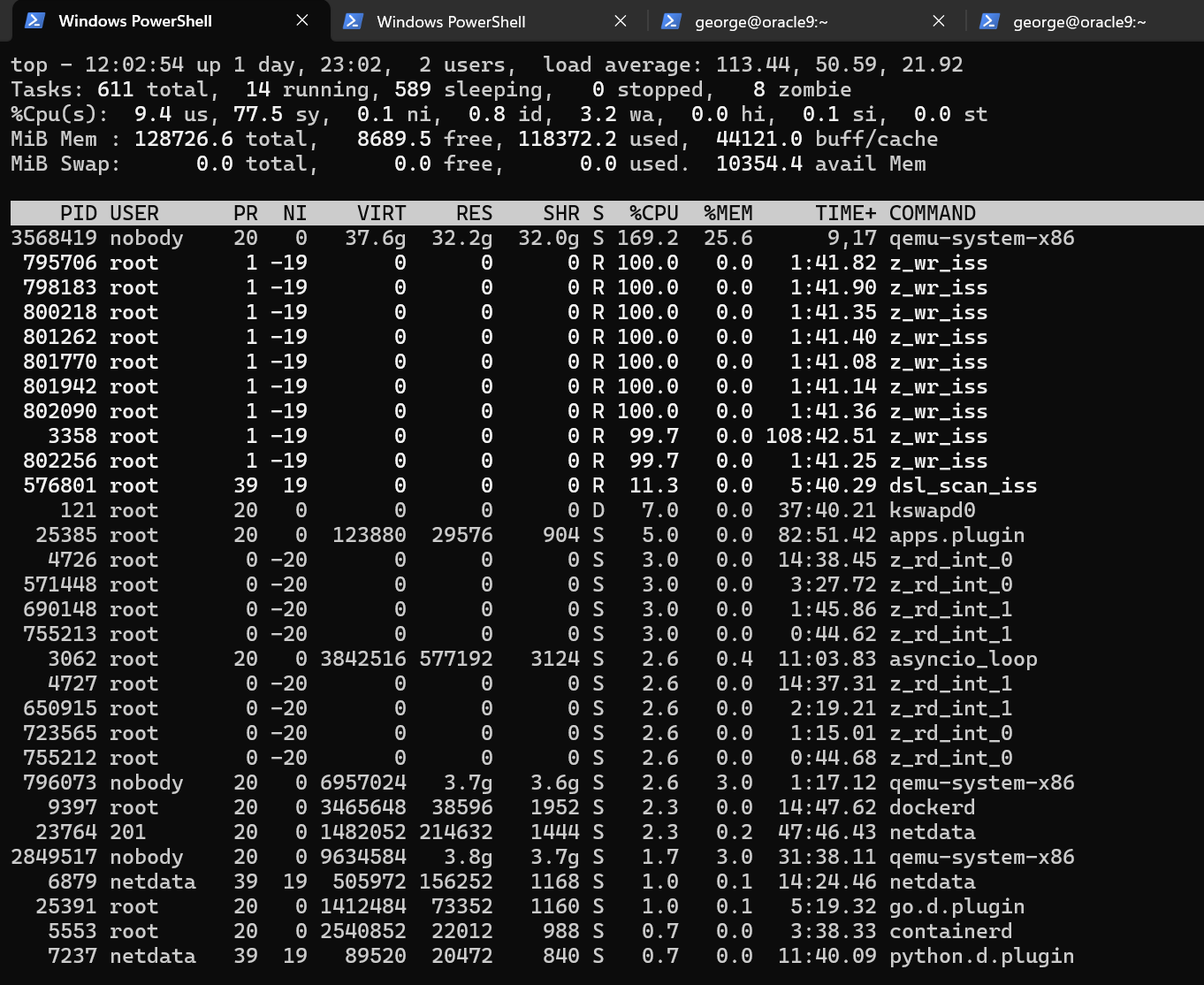
I can’t tell if its metadata reads or something else. Its reading about 2500 blocks/s for 50K writes/sec.
The 100% util number sounds scary, but it just means that there’s a continuous queue/pipeline of writes.
But the real question is whether its safe and reliable. It doesn’t seem to be failing.
Can we conclude its only with SO that it fails??
I know it’s an edge case, that’s the point. Something weird is going on, I’m trying to figure out what. I felt like that IO in VMs has been kinda sluggish and weird since beta1, but I’m trying to put a finer point on what exactly is wrong.
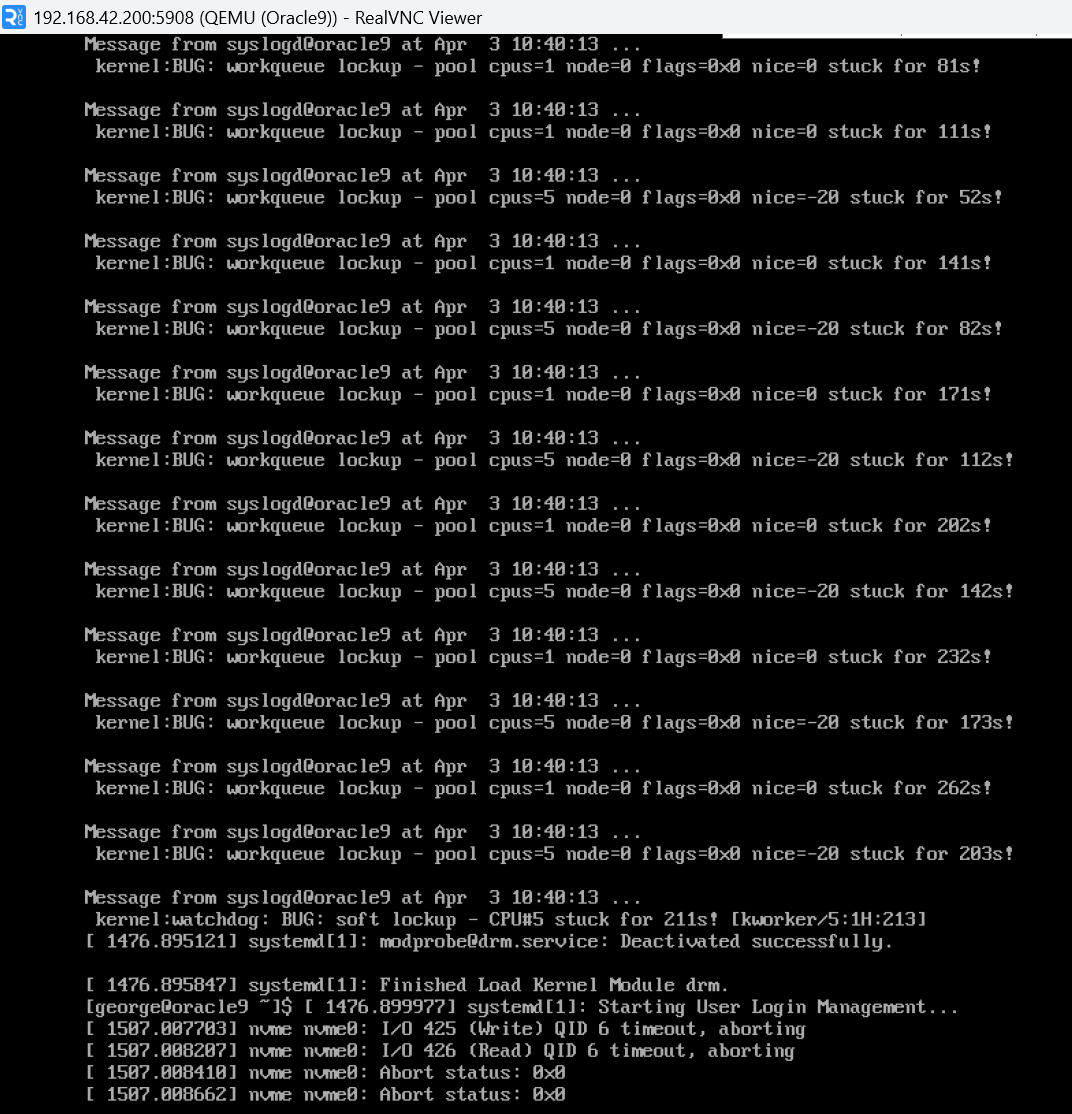
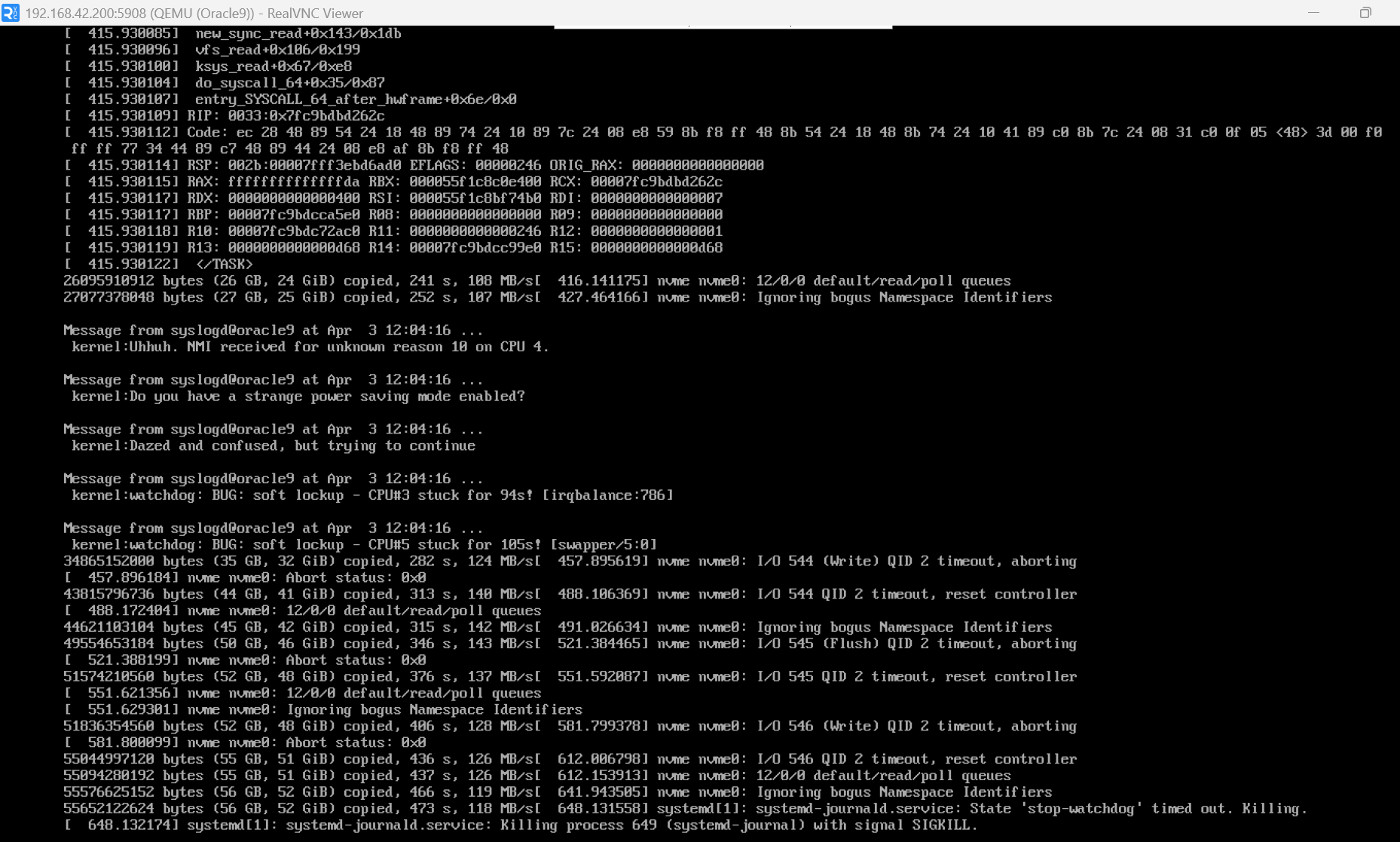
Oh wow, it broke real hard. I wasn’t even writing to the NVMe devices.
OK, how about this, I disabled compression and I’m just writing zeros. The IO should be unencumbered and the limiting factor should just be the disk IO, right?
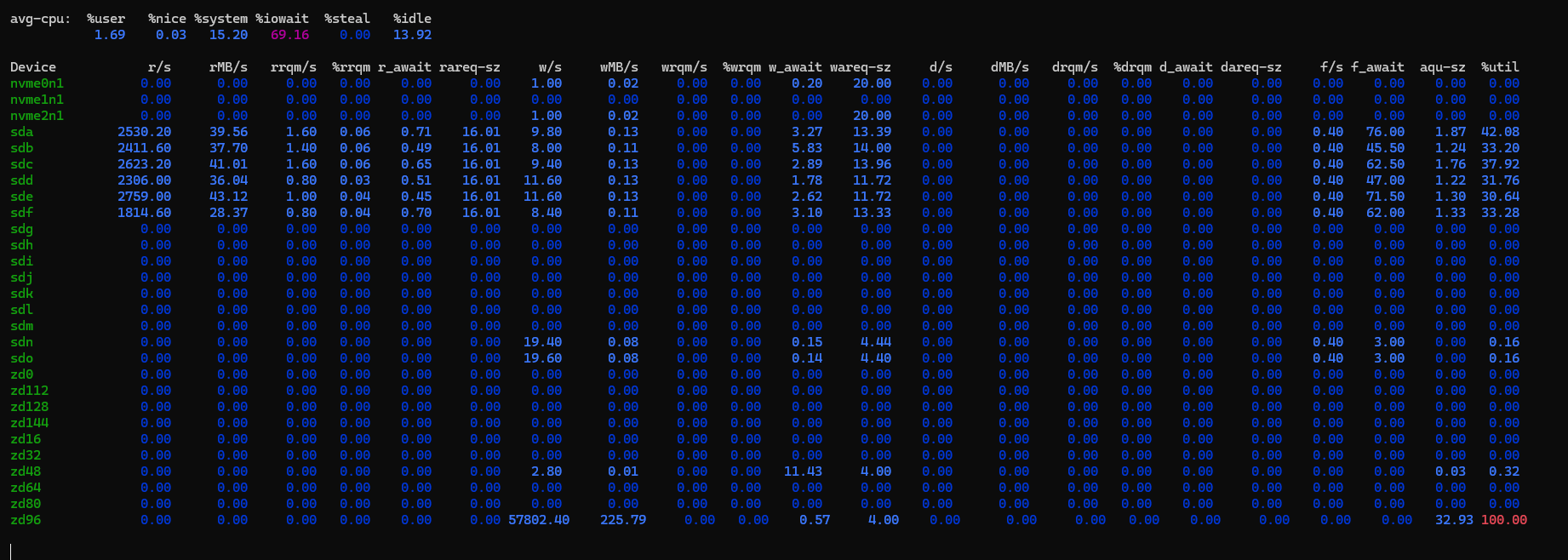
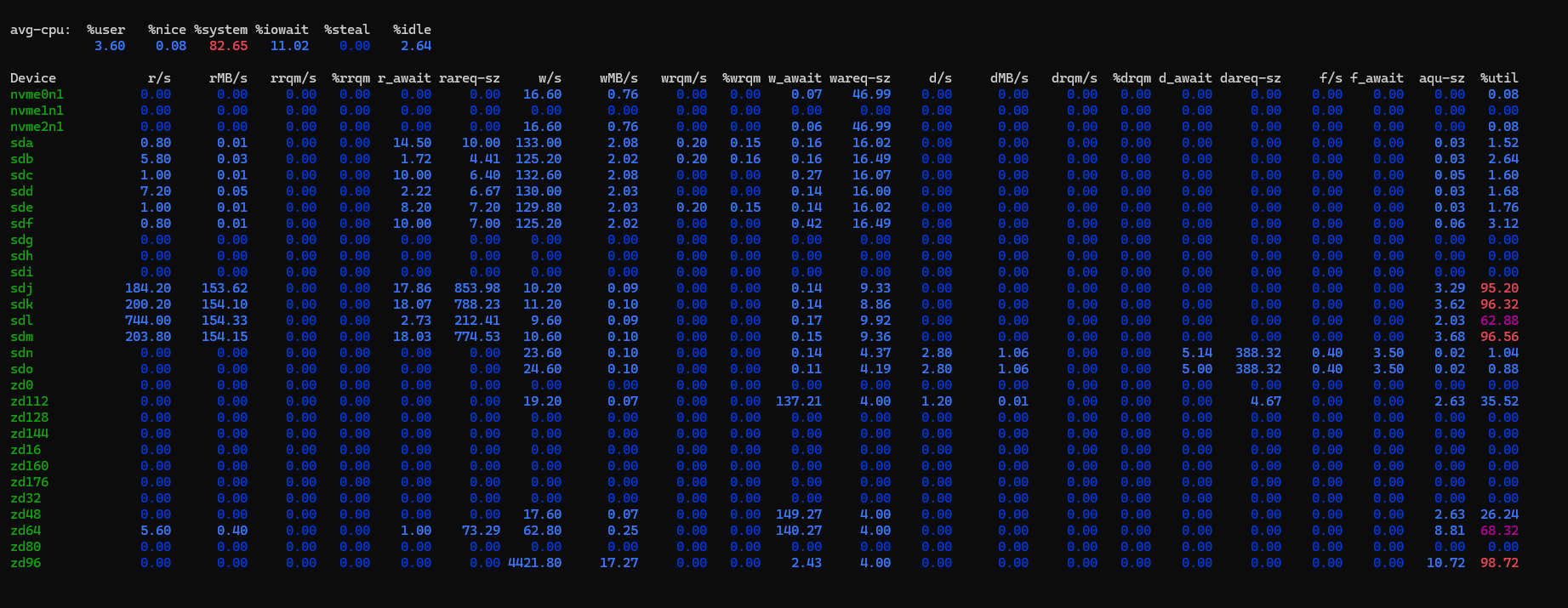
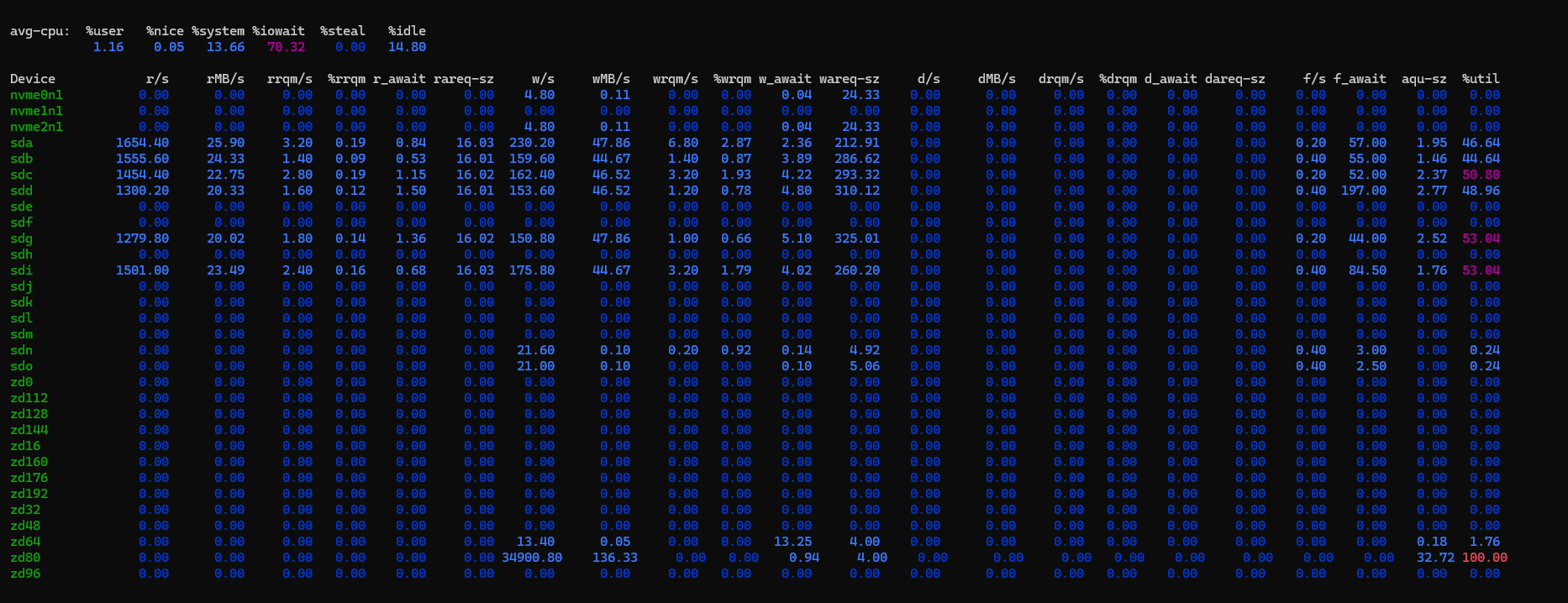
4421 w/s and 17MB/s on zd96
Isn’t that 4KB I/O size?
Correct, but I told dd to do 1MiB blocks. If I look at iostat stat in the VM, it’s sending 1MB blocks to the disk, but the truenas iostat reports 4K blocks. ![]()
Can you post the config of your VM:
incus config show VMNAME --expanded
@gedavids
For the sake of testing here and given the errors you are getting from the guest VMs kernel, I would be curious if you can reproduce this issue while using the SCSI IO bus type rather than the NVME one.
I recently had issues with my Windows VMs while using the NVME IO bus in Incus and once I changed them to use the SCSI one the problem went away.
For each disk attached to your system, you can run this command to change it to SCSI, and you can validate it with the command in my previous post. You will have to power down the VM before running this.
incus config device set VMNAME ix_virt_zvol_root io.bus virtio-scsi
Strange… lets start with resolving that issue since its easily documented and might be the underlying cause of your issues. (maybe its the NVME IO bus above)
Can you verify your zvol record size?
george@truenas42:~$ sudo incus config show Oracle9 --expanded
[sudo] password for george:
architecture: x86_64
config:
boot.autostart: "false"
limits.cpu: "6"
limits.memory: 4096MiB
raw.idmap: |-
uid 568 568
gid 568 568
raw.qemu: -vnc :8
security.secureboot: "true"
user.autostart: "false"
user.ix_old_raw_qemu_config: -vnc :8
user.ix_vnc_config: '{"vnc_enabled": true, "vnc_port": 5908, "vnc_password": null}'
volatile.cloud-init.instance-id: 68b02fa8-0e3a-4d46-819d-d880d48ca2ee
volatile.eth0.hwaddr: 00:16:3e:99:1b:e4
volatile.last_state.power: STOPPED
volatile.uuid: 6fd644f2-64be-41d2-8d95-defc3e51d874
volatile.uuid.generation: 6fd644f2-64be-41d2-8d95-defc3e51d874
volatile.vsock_id: "2887855691"
devices:
disk0:
source: /dev/zvol/Array/VMs/test4
type: disk
eth0:
nictype: bridged
parent: br0
type: nic
root:
io.bus: nvme
path: /
pool: default
size: "32212254720"
type: disk
ephemeral: false
profiles:
- default
stateful: false
description: ""
Array/VMs/test4 volblocksize 16K default
incus config device set Oracle9 disk0 io.bus virtio-scsi
incus config device set Oracle9 root io.bus virtio-scsi
I did those, and it’s a little better, but still mad.
The system CPU processing overhead is back to normal at least, but I throughput is still way down from 24.10. It was seeing 300-400MB/s with 24.10 in the same test. And I’m still seeing the massive number of reads along with my writes, which wasn’t happening with 24.10. Like if it’s reading metadata to do the writes, it’s being very inefficient with those reads and re-reading constantly.
EDIT: I’m going to try virtio-blk after this. Then I’ll try a thick provisioned disk.
EDITEDIT: Also, @Captain_Morgan I’m still seeing things as 4K block writes.
You are writing to an unformatted disk, which is emulated to have a block size of 4K, as a normal physical disk would. So that is probably expected. I’m not sure why specifying 1M in dd isnt working tho, but this is something on the guest OS side.
It is not, the guest OS shows 1M block writes. It’s the translation to the zd device that’s making 4k blocks, and again 24.10 did not have this issue.
Okay. I’ll do some more testing later today and report back to see if I can figure out anything else. Haven’t dug into Linux VMs much on Incus.