When transferring large video files (10-100 GB) over a 10GbE connection, the speed tends to slow down, fluctuating between 200 and 1000 MB/s.
I’m considering whether a dedicated metadata vdev might improve performance in my situation. I’m not concerned with the performance of small files; my main focus is achieving sustained read speeds for larger files. These files will only be accessed once, so using an L2ARC won’t be beneficial, as multiple reads won’t occur to build it up.
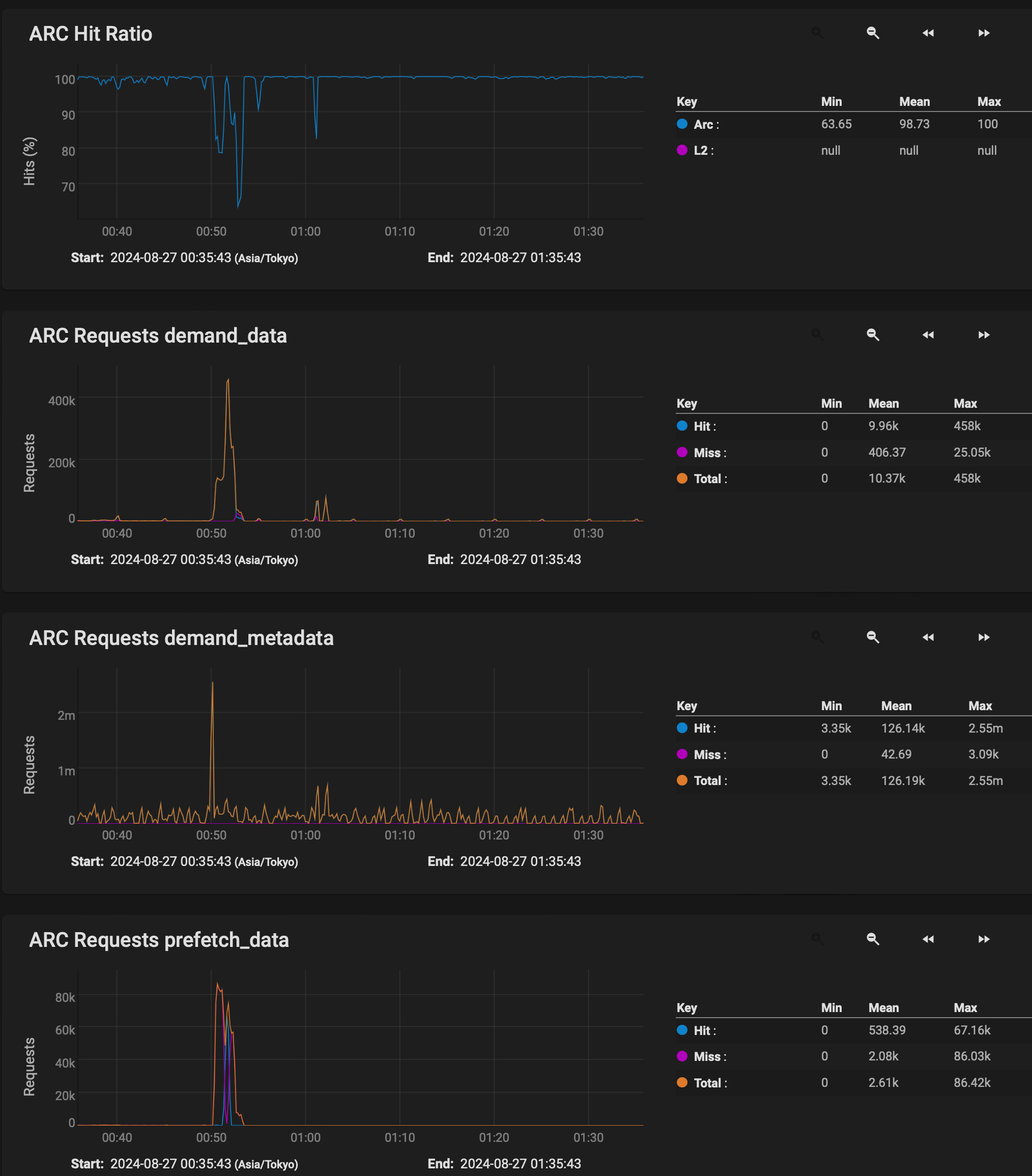
Below is an image of the ZFS filesystem during a 100GB file transfer. As shown, the ARC hit rate sometimes drops to 60%.
The only real way to speed up your access would be to add VDEVs. 12-wide is pretty wide and the performance penality you are seeing is likely due to the width of that single VDEV. I’d suggest 2 VDEVs of 6 dives would improve your performance, but it would come at a cpacity cost. However, a metadata VDEV would not help here.
I opted for a single VDEV setup to ensure more redundancy in case two drives fail. Having two VDEVs isn’t really feasible for me.
The screenshot indicates a high peak in demand_metadata. From my understanding, a special metadata VDEV would allow metadata to be accessed ‘instantly,’ eliminating metadata latency when reading blocks from the HDDs.
Given this, I’m curious why a special VDEV wouldn’t help in this situation. Am I misunderstanding the role of metadata, where it’s only read once at the start of accessing a file? Would this mean a special VDEV is only beneficial for handling many small files and not for a single large file?
A special vdev is pool critical and cannot be removed. What might work better, and be cheaper in resources for your purposes, is an L2ARC set as metadata only.
Its not pool critical and can be removed if it doesn’t achieve your objectives.
However I tend to agree that in the circumstances posted neither solution will achieve a speed increase
How does it look, when you re-read the same file from cash?
A 12-wide raidz2 should have enough IOPS to read one file.
Also remember, that any special vdev is pool critical, so losing it means your data is toast.
Therefore it should have the same redundancy as your pool . So you would need a 3-way mirror.
Thank you. I’m going to explore using L2ARC for metadata first.
I’m aware about the special vdev needing redundancy and was prepared to go the 3-4 mirror route. I’d prefer the l2arc option though, since importing/transferring the hdd’s to another system would be less stressful.
Currently, the first 60-70 GB of a file transfer is quite fast 750+ MB/s, but then the speed drops to 200-300 MB/s. It’s not a huge issue, but it doesn’t make sense to me, and I would like to resolve it.
Right now it’s in the middle of something so in a few days I hope to give an update.
The sVDEV consists of 2 partitions - 75% of its space is allocated to small files by default, another 25% to metadata - (this can be changed based on your use case)
Speeding up metadata helps with directory traversal, find files, and like tasks. For example, I found a metadata-only, persistent L2ARC as well as a sVDEV very helpful to speed up rsync tasks. Neither have a realistic impact on the transfer rate of large files.
The small files aspect of a sVDEV may have an impact on your read / write speed in case said pool intersperses such files with the larger files you’re also reading/writing. Since sVDEVs are traditionally built using SSDs, small file transactions happen a lot faster. That can have a big impact if there are a lot of small files to deal with - either via the recordsize settings and/or the small file cutoff setting for each dataset.
That is the reason why App pools, virtual machines, etc. used to be housed in separate SSD pools from the main data repositories consisting of HDDs. With a sVDEV, you can tailor each dataset - and some of them can reside 100% in the sVDEV. This ‘fusion’ approach is a great way to make better use of all drives in a NAS, with the caveat that the sVDEV is essential to pool health and has to be at least as redundant as the data drives. I run a 4-wide sVDEV mirror consisting of Intel S3610 SSDs with ridiculous limits re: writes-per-day.
You can see if the L2ARC set to metadata-only and persistent has any impact, provided your NAS has at least 64GB of RAM. Pretty much any decent SSD will do. Since the L2ARC is redundant, a loss of the SSD will not affect pool health (just performance). I found that I needed at least three complete directory traversals before all metadata found its way into the L2ARC (that has to do with the rate with which L2ARC is filled with metadata - the system limits writing ‘missed’ metadata to the L2ARC).
The pool is currently at 48% capacity, with fragmentation at 3%.
The issues are read related. The receiving end (NVMe) is more than capable, as should be the VDEV with 12 (10) HC550 drives.
I know I need to populate the L2ARC using a command at the start, but my understanding is that this only caches a file index and some small files depending on the settings. It doesn’t cache the location of all the data blocks? This might be useful in some scenarios, but not in mine.
What I essentially need is for all block locations of every file to be cached. Otherwise, how would this approach improve a sequential file transfer that requires faster metadata access, especially in the middle or near the end?
Seeing the hit ratio dip during a long single file transfer while no one else is using the system is very strange to me.
That easily surpasses your physical RAM, and you even said these specific files would not be “repeat” transfers. So you’re at the mercy of the speed of your vdev.
sVDEVs aren’t partitioned in the actual “disk partition” sense, but rather there’s a preconfigured 25% “buffer space” for metadata - prior to a write, ZFS checks for the allocated space and ensures that it’s below the limit.
This also means that in a scenario where you have 25% of your drive full of metadata already, and you enable special_small_blocks it’s going to cut you off when 50% of the drive size has been allocated for small files (less any new metadata.) Only metadata is allowed to eat into that 25% buffer.
@Videodrome an L2ARC set to metadata-only might help here, if that’s truly the bottleneck point, but you might also be hitting a case where prefetch is somehow not keeping up. A single thread of copies should be an ideal workload for it though.
I saw you mention a “Xeon with 96GB of RAM” - can you provide some more information about the system (board/storage controller?) and the version of TrueNAS you’re running?
Intel(R) Xeon(R) CPU E5-2699 v3
Asrock X99WS
LSI 9300
TrueNAS-13.0-U6.2
Intel X540-T2 nic
I’ll add a 500GB NVMe L2ARC in a few days as a test to see if it improves performance. I might upgrade to 13.3 to utilize the zfs_arc_meta_balance setting.
Yes, they do.
However, temperature isn’t an issue.
I have five fans in the case, with an additional fan directed at this card and the NIC. The HDDs and backplane are in a separate enclosure with their own fans.
Just so that I’m clear, I’m not discouraging the use of RAIDZ2, I’m just saying that having a relatively large number of disks in a single VDEV is going to limit performance.
Can you please run zpool iostat -vvyl 360 1
You can adjust the 360 to be closer to the expected amount of time it would take to copy a file, I’m assuming 5 minutes here and the value is in seconds.
I believe you’re hitting the saturation point of your disks, and given the topology I’d expect to see some pretty high disk_wait times.
Here’s an example so you can see what the output looks like
Before setting up this server, I used several small 2.5" HDDs to benchmark some configurations. Although the two-VDEV setup had better read performance, none of the tests showed any slowdowns over time.
Now, I’m starting to worry about temperature, even though I thought I had that covered. The slowdown after one minute of transferring data makes it plausible that things could be heating up to a critical point. I’m planning to add three temperature sensors to the HBA, NIC, and backplane heatsinks to monitor what’s happening.