Oh good point. So yes, create the dataset. Then drop into TrueNAS cli and sudo chown -R 2147000001:2147000001 /mnt/<pool>/<dataset> if you need it owned by root in Incus - for a Docker data-root for example.
Or sudo chown -R 2147001001:2147001001 /mnt/<pool>/<dataset> if you want it owned by uid 1000, default first user in Debian or Ubuntu.
Adjust offset to whatever uid you need in Incus.
This assumes the dataset is fresh and really for Incus and Incus alone.
If you need it in Incus but also accessible in a share, then I’d guess the best bet is an advanced ACL - owner and group with offset to make Incus happy, then ACL handles access rights from the TrueNAS side.
If you’re doing type: disk, then I’m doing that in the op in the cloud init config. I’m just creating a separate dedicated dataset for jails rather than using .ix-virt. I also addressed the reasons behind breaking out earlier in this thread.
Yes, I could leave the OS dataset in .ix-virt and continue to break out the data disks like I do in the OP. It’s just a preference to keep everything in one central location to K.I.S.S. and clean. It’s also to separate unsupported vm’s/containers in their own dataset.
In the OP, the security change is because I’m running mine in a VM currently and it requires nesting.
I’m going to work on migrating my bare metal box to TNS 25.04 this week since the BETA is out now and start migrating all my jailmaker machines over to Incus. See what we get with Nvidia… Wheee.
data:
path: /mnt/data
source: /mnt/pool/data/apps
shift: true
type: disk
I’m using the TrueNAS CE UI instead, and that doesn’t use shift. Fresh dataset into /mnt/docker, then chown it on the TrueNAS side so root owns it on the Incus side, and set Docker data-root to use it.
Basically I’m staying in the UI and middleware, instead of handling Incus from CLI.
I see the entry where you talk about easier snapshots and such. I think for me, my requirements are simpler, and so KISS means just sticking with what TrueNAS does and mounting a dataset in where the Docker data-root will live. Almost 100% UI, and will definitely survive TrueNAS upgrades.
I can see the merit of what you’re doing for more complex use cases.
That’s ONLY for the data datasets, NOT the OS datasets. Since there are multiple apps running on a single host and multiple permissions required, it’s just easier to set shift and set the permissions down the tree on said datasets. It’s up to you how you want to handle it and I get it.
I may look at expanding this into a script ala jailmaker or collection of clout-init configs as well. I may possibly add a config to incorporate the Incus Management UI as well. So I’m going a slightly different direction then IX on this one.
Hmm, I’m assuming those apps are in systemd then, or use Docker bind mounts?
I use Docker volumes, and permissions are handled correctly for different containers with different users, without shift and with Docker handling the contents of the dataset that’s in /mnt/docker
Different approaches I think. I avoid bind mounts for the most part, because permissions get so ugly. I only run lxc at all because this one particular app is a little more complex and doesn’t lend itself well to the Custom App flow in TrueNAS.
I could persuade my boss to let me keep a decommissioned desktop PC from work for a few weeks before they threw it in the trash so I could play around with fangtooth. Playtime starts Saturday.
BTW, I found a recommendation from stgraber to use block based file systems for docker in incus
but, the benefit of passing in a dataset is that you have full visibility of it from outside the container, and the neat thing is with Incus you can actually delegate zfs to the container so that it actually has access to zfs features on its dataset.
I’m keen to hear that goes, although I’m using an Intel Arc A380 which does make things a little easier.
With the change to Incus for VMs and LXCs, I hope this means we eventually get an easy supported method for backup and restore. In the interim I guess it’s simple enough to script backups for storage when the need arises. I know I can snapshot, but I still like to have a couple of backups archived that aren’t necessarily on systems that run TrueNAS.
Something like that should work right? I’ve never used incus before, so does ‘incus stop’ wait for the instance to shutdown gracefully or would I need to add an arbritrary ‘sleep 60’ line in there for a bash script?
So using the default store for the OS disks is easy enough for bringing up machines and having custom disks attached to the local datasets works fine. Machines should persist this way as well since we’re working within the IX default configuration. It was pretty seamless in bringing up a new LXC container. You can see how root would work using default which would drop the OS disks under /mnt/pool/.ix-virt. This should be fine for now. I’m still hoping that IX will support custom datasets outside the one’s managed by middlewared.
I will work on the GPU next… automating that part is going to be a little more involved for NVIDIA based GPU’s, amd and intel will likely be just adding the GPU to the config and going to town… but basically I will need a script to do the following:
Call initial cloud-init to install everything including nvidia drivers
Enable nvidia configs
incus config set docker-gpu nvidia.runtime=true
Start container again
Run nvidia-ctk runtime configure --runtime=docker
Restart docker systemctl restart docker
Profit?
I’m open to suggestions as well for creating machines. I’m thinking a simple BASH script that will let you pick a gpu or non-gpu instance and create the instances and run all the needed commands. I’m thinking something simple like and let it go to town:
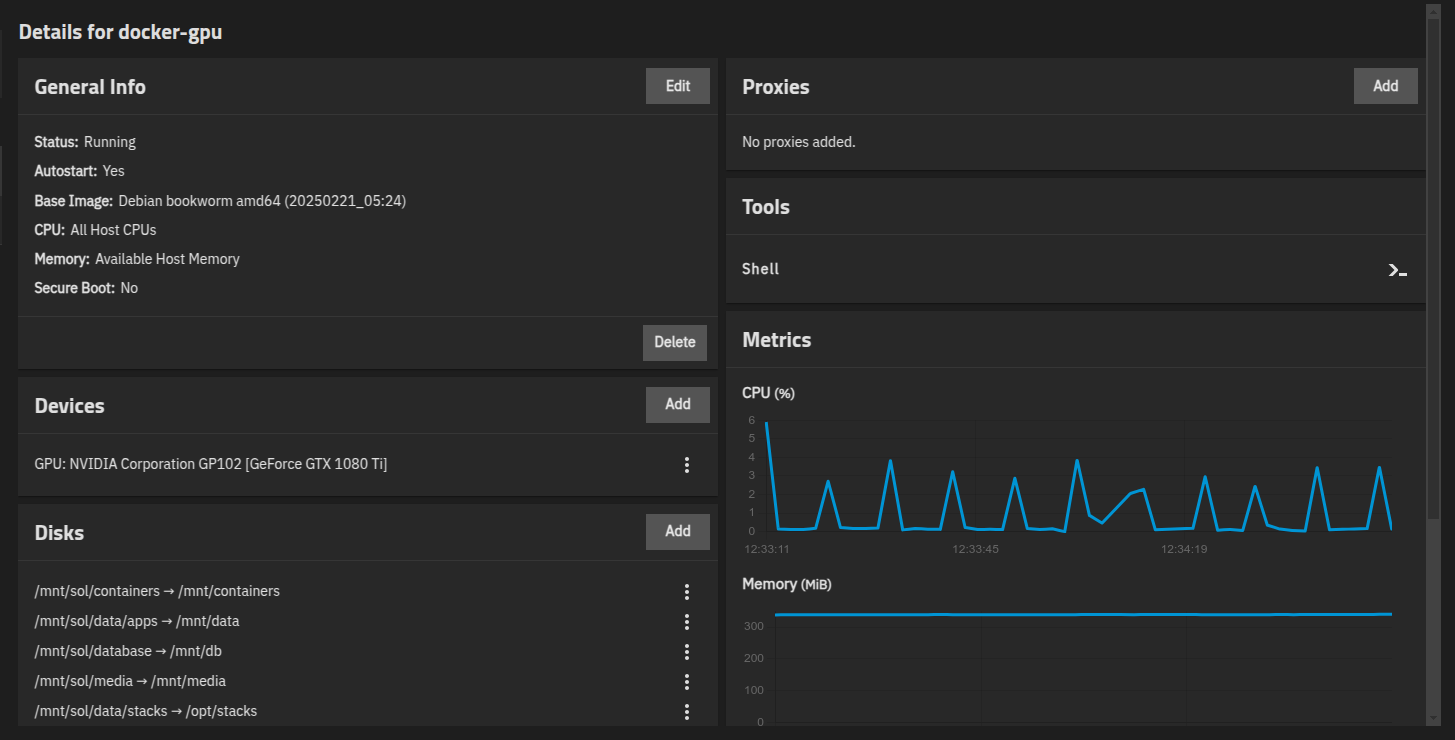
Ran into some additional issues with the GPU and starting gpu docker containers:
nvidia-container-cli: mount error: failed to add device rules: unable to find any existing device filters attached to the cgroup: bpf_prog_query(BPF_CGROUP_DEVICE) failed: operation not permitted: unknown
Setting the following in /etc/nvidia-container-runtime/config.toml seems to have worked around the issue in LXC. I’m not 100% sure if this is a proper fix at this time…
no-cgroups = true
and mounting the GPU path:
nvidia-gpu:
path: /proc/driver/nvidia/gpus/0000:2b:00.0
source: /proc/driver/nvidia/gpus/0000:2b:00.0
type: disk
Working on some additional issues with storage not passing through properly that were working previously in the nightly phase that are not working in BETA-1.
This mounted the extra datasets missing below in the tree.
This brings up in issue in the TrueNAS Web UI… it doesn’t like passing through that directory for the nvidia-gpu disk… but as far as I can tell it’s a necessary evil until either LXC is fixed or nvidia fixes their stuff…
Error: Traceback (most recent call last):
File "/usr/lib/python3/dist-packages/middlewared/api/base/server/ws_handler/rpc.py", line 310, in process_method_call
result = await method.call(app, params)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/api/base/server/method.py", line 49, in call
return self._dump_result(app, methodobj, result)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/api/base/server/method.py", line 52, in _dump_result
return self.middleware.dump_result(self.serviceobj, methodobj, app, result)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/main.py", line 785, in dump_result
return serialize_result(new_style_returns_model, result, expose_secrets)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/api/base/handler/result.py", line 13, in serialize_result
return model(result=result).model_dump(
^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/pydantic/main.py", line 212, in __init__
validated_self = self.__pydantic_validator__.validate_python(data, self_instance=self)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
pydantic_core._pydantic_core.ValidationError: 1 validation error for VirtInstanceDeviceListResult
result.7.DISK.source
Value error, Only pool paths are allowed [type=value_error, input_value='/proc/driver/nvidia/gpus/0000:2b:00.0', input_type=str]
For further information visit https://errors.pydantic.dev/2.9/v/value_error