Hi all! I’ve been having major stability issues after upgrading to Dragonfish.
App Containers
The first thing I noticed is a bunch of containers being in the yellow, not green state. They’d be green, then go yellow and stay that way. Even if I stop the container, it’s not long before they go from green to yellow again.
I have a mix of TrueCharts and TrueNAS containers.
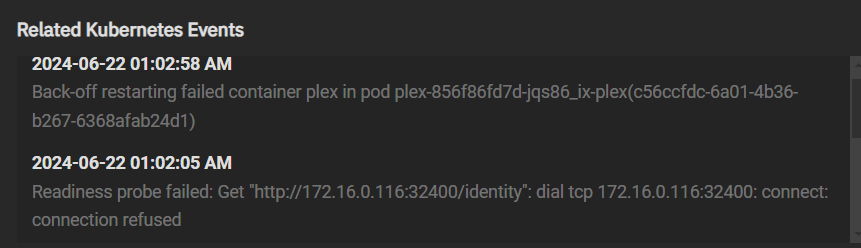
It was most apparent in Plex and Jellyfin. Jellyfin wouldn’t load, and Plex kept having connection issues every so often. If you got a media file to play, you’d probably be fine because of buffering, but the next video file would not load, song lyrics wouldn’t load, song files wouldn’t load, etc. It’s so bad I’m spending a bunch of money to build a new app-only server.
TrueNAS Charts also have issues
I thought it was just TrueCharts containers, but even Pi-Hole and Resilio-Sync won’t start now, and I’m using the official TrueNAS container for them. I need Resilio-Sync to work on a project with someone else, so it’s problematic when this happens.
NAS restarted itself
Just tonight, the NAS restarted itself! I was copying a bunch of large multi-gigabyte video files. It was working, and then suddenly restarted. This is making me think it’s the OS and not the NIC or Kubernetes.
Cache-size maybe?
One thing I know changed in Dragonfish is the ZFS cache size. It’s now dynamic like CORE, so I removed my init script to set it, but I restarted afterward, so this crash is unrelated to that config.
What happened?
I wanna know how I can find out what caused the restart, and prevent it from happening again. My SuperMicro BMC didn’t show anything, so it’s most likely OS-level.