This post is more “For Science” than it is a recommendation of any kind.

Benchmarking for special vdev isn’t exactly straight forward. It’s not like adding additional vdevs where you can run standard benchmarking suites and understand the performance implications. We’re specifically modifying how metadata is stored in the pool, and you should really be testing LOCALLY on the NAS first before moving to SMB or another sharing protocol if you’re trying to really see the impact without introducing variables.
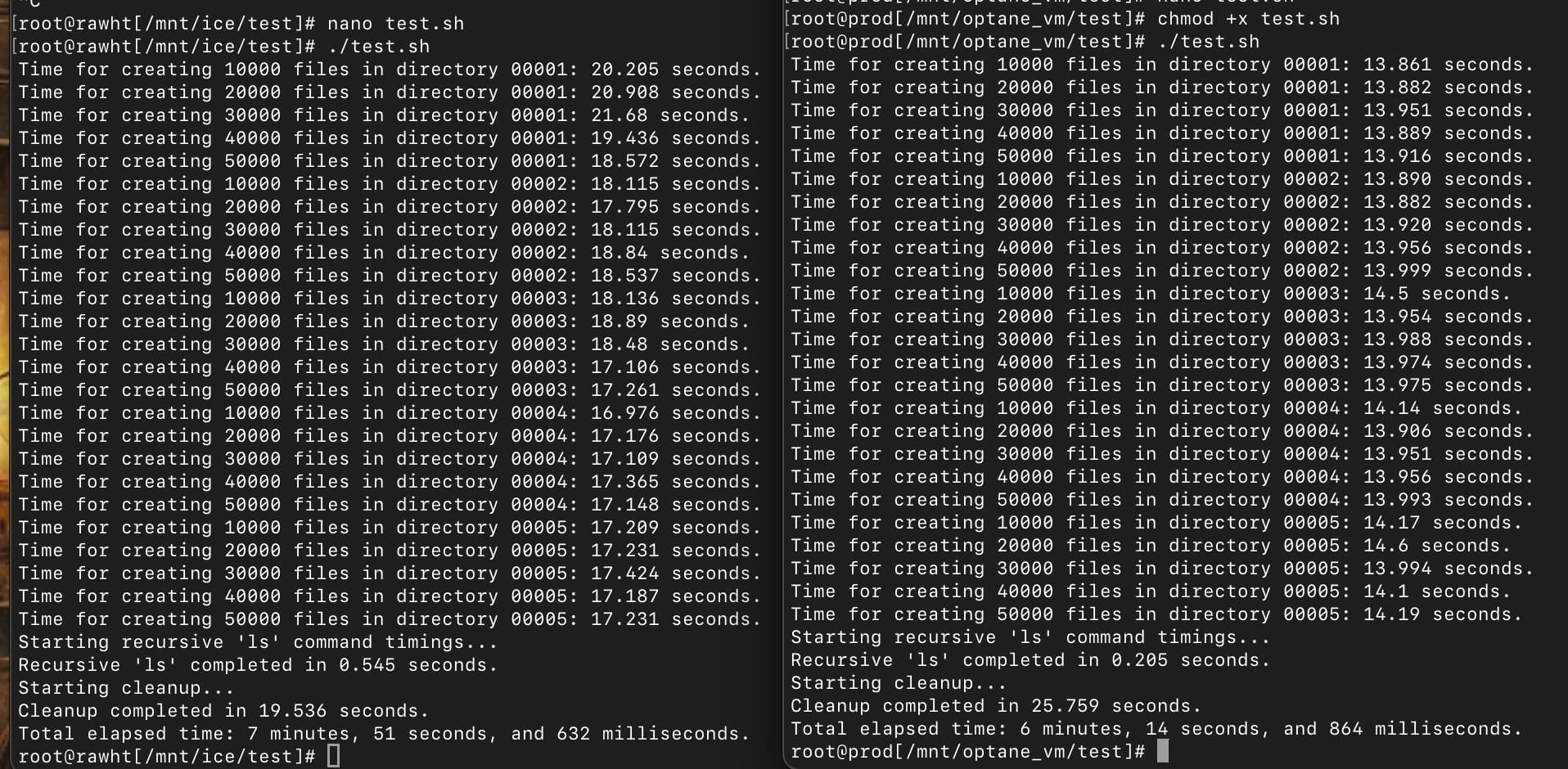
A really quick and dirty approach is to make a bunch of empty files and then time how long it takes to make them, followed by going back through and listing the contents of each of those directories.
For giggles and laughs while reading this thread I made a script that does that. You’d want to go into the shell on your NAS and make a folder inside of a dataset on your pool. From there use nano to make a file called test.sh, paste the contents of the script below (control+o and then control+x to save and exit), and then type chmod +x test.sh. You can then run the script by doing ./test.sh
#!/bin/bash
# Number of directories and files
NUM_DIRS=5
NUM_FILES=50000
MILESTONE=10000 # Milestone to report progress
# Base directory to create all folders in
BASE_DIR="./test_folders"
# Create a base directory
mkdir -p "$BASE_DIR"
# Function to get current time in milliseconds
current_time_ms() {
date +%s%3N
}
# Measure time to create folders and files
START_CREATE_TIME_MS=$(current_time_ms)
# Initialize milestone times
PREVIOUS_MILESTONE_TIME_MS=$START_CREATE_TIME_MS
for ((i=1; i<=NUM_DIRS; i++)); do
# Format the directory name with leading zeros
DIR_NAME=$(printf "%05d" "$i")
mkdir -p "$BASE_DIR/$DIR_NAME"
for ((j=1; j<=NUM_FILES; j++)); do
# Format the file name with leading zeros
FILE_NAME=$(printf "%05d.txt" "$j")
touch "$BASE_DIR/$DIR_NAME/$FILE_NAME"
# Print elapsed time every 10000 files
if (( j % MILESTONE == 0 )); then
CURRENT_TIME_MS=$(current_time_ms)
CURRENT_MILESTONE_TIME_MS=$((CURRENT_TIME_MS - PREVIOUS_MILESTONE_TIME_MS))
echo "Time for creating $j files in directory $DIR_NAME: $((CURRENT_MILESTONE_TIME_MS / 1000)).$((CURRENT_MILESTONE_TIME_MS % 1000)) seconds."
# Update the previous milestone time
PREVIOUS_MILESTONE_TIME_MS=$CURRENT_TIME_MS
fi
done
done
# Silently track the total elapsed time
END_CREATE_TIME_MS=$(current_time_ms)
CREATE_ELAPSED_TIME_MS=$((END_CREATE_TIME_MS - START_CREATE_TIME_MS))
# Measure time to recursively perform 'ls' in the base directory
echo "Starting recursive 'ls' command timings..."
START_LS_TIME_MS=$(current_time_ms)
# Recursively list all files and subdirectories
(cd "$BASE_DIR" && ls -R > /dev/null)
END_LS_TIME_MS=$(current_time_ms)
LS_ELAPSED_TIME_MS=$((END_LS_TIME_MS - START_LS_TIME_MS))
echo "Recursive 'ls' completed in $((LS_ELAPSED_TIME_MS / 1000)).$((LS_ELAPSED_TIME_MS % 1000)) seconds."
# Measure time to remove and clean up all test files
echo "Starting cleanup..."
START_CLEANUP_TIME_MS=$(current_time_ms)
# Remove all test files and directories
rm -rf "$BASE_DIR"
END_CLEANUP_TIME_MS=$(current_time_ms)
CLEANUP_ELAPSED_TIME_MS=$((END_CLEANUP_TIME_MS - START_CLEANUP_TIME_MS))
echo "Cleanup completed in $((CLEANUP_ELAPSED_TIME_MS / 1000)).$((CLEANUP_ELAPSED_TIME_MS % 1000)) seconds."
# Calculate and print total elapsed time
TOTAL_ELAPSED_TIME_MS=$((CREATE_ELAPSED_TIME_MS + LS_ELAPSED_TIME_MS + CLEANUP_ELAPSED_TIME_MS))
TOTAL_ELAPSED_MINUTES=$((TOTAL_ELAPSED_TIME_MS / 60000))
TOTAL_ELAPSED_SECONDS=$(((TOTAL_ELAPSED_TIME_MS % 60000) / 1000))
TOTAL_ELAPSED_MILLISECONDS=$((TOTAL_ELAPSED_TIME_MS % 1000))
echo "Total elapsed time: $TOTAL_ELAPSED_MINUTES minutes, $TOTAL_ELAPSED_SECONDS seconds, and $TOTAL_ELAPSED_MILLISECONDS milliseconds."
This isn’t testing a real-world scenario, but should be a potential way to test for improvement directly associated with a metadata vdev I think.
System on the left is AMD EPYC 7F52 with 5x RAIDZ2 7 wide VDEVs of 8TiB drives and System on the right is AMD Ryzen 3700X with 2x 2-way mirrors of Optane 905P 960GB. Neither has special vdevs. Both are SCALE 24.04.2
Posting just for reference point. CPU (single threaded performance) and other system performance such as RAM speed may be a factor here, so direct comparison between different systems might be of limited value. Really the idea is to compare the pool with and without special vdev for metadata, ON THE SAME SYSTEM, to see if this test can tease out some intelligence.
I’d be interested in seeing the results for a clean fresh pool both without a special vdev, as well as clean fresh pool with a metadata special VDEV @louis
If there’s interest in this topic I can probably come up with better stuff to do, like @Constantin mentioned rsync is a good one to test.