Hi all.
OK, so I made some progress.
The anal in me decided to go for dual parity anyway, I have a Lenovo SA120 JBOD with plenty of place for disks, so I shelled a bit more money and got myself a 3rd (new) 18TB Exos drive.
So I have 3 new drives and 1 old drive that I will add later. I decided to RTFM a bit and did the following:
Created a sparse file:
dd if=/dev/zero of=/tmp/foo.img bs=1 count=0 seek=18T
Created the pool:
zpool create main_pool raidz2 /dev/sda /dev/sdd /dev/sdf /tmp/foo.img -f
I had to use -f to get it to use the file
Mark the sparsefile as faulty:
zpool offline -f main_pool /tmp/foo.img
export so I could import it into truenas:
zpool export main_pool
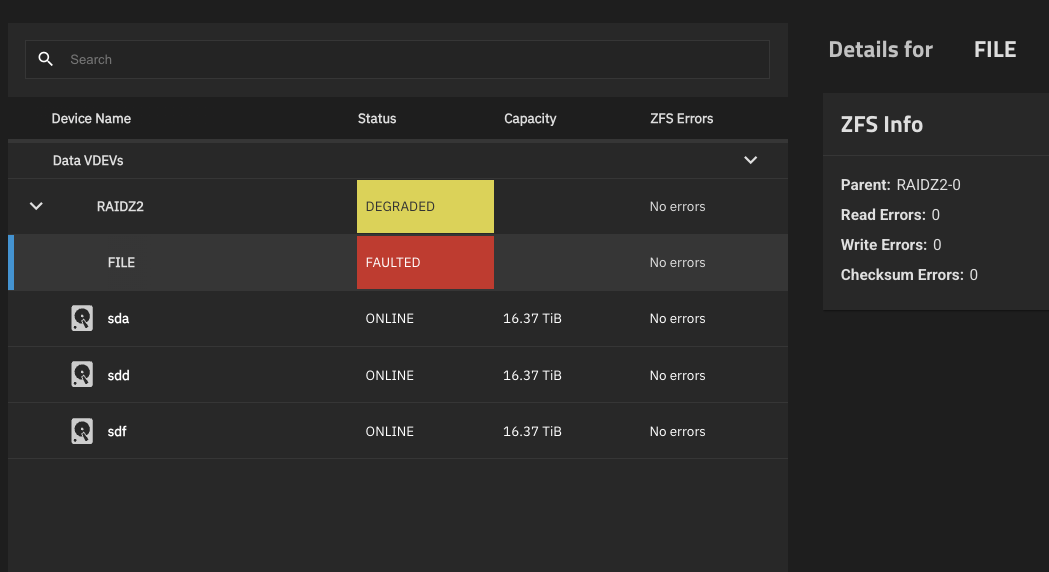
I then imported it into TrueNAS, it shows:
Data VDEVs 1 x RAIDZ2 | 4 wide | 16.37 TiB
Usable Capacity: 31.59 tiB
And says it is in degraded mode.
Honestly, much easier than I thought, I am now copying all the data from the old drive to the array and I will then plan to add the drive.
Now, here is a question:
During my testing I noticed that I can also do this:
zpool create main_pool raidz2 /dev/sda /dev/sdd /dev/sdf
This will create a 16TB array 3 disks wide with 2 used for parity and not in degraded mode
What would be the safest approach? do this and expand with the 4th drive or keep it in degraded mode and then resilver using the old drive once I finish copying everything (or it doesn’t really matter).
I wonder if extending is more “expensive” than resilvering / replacing a defective drive
Thanks!