Hi Joe, I might have missed something somewhere, but I’ve noticed in the reports it shows the drives for the data part of the pool, but doesn’t give details on any cache drive you have. Is this intentional?
########## ZPool status report for StarOne ##########
pool: StarOne
state: ONLINE
config:
NAME STATE READ WRITE CKSUM
StarOne ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
f0c58449-55ed-4b10-ab92-a82d351becbe ONLINE 0 0 0
7f454f33-4e6f-434c-b35b-a5236c328074 ONLINE 0 0 0
44186e8f-dffe-4354-a660-118a6952951d ONLINE 0 0 0
56fefbe1-801b-4aaa-a592-c97f8304311b ONLINE 0 0 0
cache
db23c43a-4e29-4695-9abb-aa599c9cecbe ONLINE 0 0 0
errors: No known data errors
Drives for this pool are listed below:
f0c58449-55ed-4b10-ab92-a82d351becbe -> sdj1 -> S/N:PK2334PCG0DG0B
7f454f33-4e6f-434c-b35b-a5236c328074 -> sdk1 -> S/N:PK1334PCHP3PNS
44186e8f-dffe-4354-a660-118a6952951d -> sdl1 -> S/N:PK2334PBKZ6L2T
56fefbe1-801b-4aaa-a592-c97f8304311b -> sdm1 -> S/N:PK2334PCG0HMLB
@Vollans That is a good point. To be honest I personally do not use log, cache, or meta drives so I never saw the issue, and no one has mentioned it before.
I just added some crappy drives to my NVMe machine for each of the above. I will work on the script and toss you a copy of the update to test. If all looks good then it will be in the next release.
Thanks to @Stux for providing me a possible solution for Spencer being integrated and running on Dragonfish. I said I would get this out as soon at it becomes available and I’d like to see if I can get this other thing addressed. It may take me 30 minutes or 2 weeks. I do need to test it in a few version of TrueNAS. And it will take me a little longer, have the daughter visiting from out of town, family first, always.
And if anyone else sees that I am overlooking something, please speak up, let me know. I will evaluate and if it makes sense to incorporate, of course I will.
Thanks for this awesome script. I have an issue not being able to send an email. I’m on TrueNAS CORE 13.3-BETA1. In the GUI the send email button works as intended.
I filled the right information during the configuration file creation. I’m convinced the issue is in my side. Any tip? Thanks!
The tip is the odds are your email client needs you to enter your email address in the “From:” section in the multi_report_config.txt file. A simple text editor will let you edit that portion, or you can use the -config and change the data.
This is more common of a problem than you know and if I can obtain a list of email clients that require this, or maybe the list of clients that don’t need it, I am very willing to update the documentation and even test for it during the configuration file creation. I know MSN.com, Hotmail.com, and Outlook.com work without needing you email address in the From section. I don’t recall if gmail.com does or not. I do have a gmail account, I can test it. If you have a company email client then you need to do what they say.
Bedtime for me, got to work in the morning. @DominikHoffmann just had the same issue and resolved it.
-Joe
EDIT: Because you are running 13.3-Beta, simply because the word “beta” is in the email header information, the text will be red. Once that word is gone, it will return to black. I did this to signify that my script was Beta, but looks like I may need to make a slight adjustment to make it ignore the application title.
Because so many SMTP servers have gotten very fussy about sending email from unknown sources I use a free account on SMTP2Go. With them I can set up trusted sender email addresses, with the free account allowing five of them. There is a verification process for that, but I don’t recall the procedure. I am using the same trusted email sender for all my notification email setups (FreeNAS, router, my clients’ devices, etc.). SMTP2Go’s servers do need authentication via an email address used as a User ID, and a password, which SMTP2Go assigns.
This is excerpted from my script config file:
###### Email Address
### Enter your Email address to send the report to. The from address does not need to be changed unless you experience
### an error sending the email. Some email servers only use the email address associated with the email server.
Email="d*o*f*a*n@*p*e*o*.us" # Send normal emails to this address
From="networkequipment@*p*e*o*.us" # From address (default
works for many)
There is no mailbox associated with networkequipment@peo.us. My email configuration in System Settings → General → Email is
Joe,
I use the script from cron and use the auto update which I like. I agree the issue has been around awhile but I would always know when an update is pushed as I would get the message. I kind of used it as an indicator that an auto update happened. The script always seemed to be successful in the end and If I went and looked the lock file was cleaned up so I never worried about it.
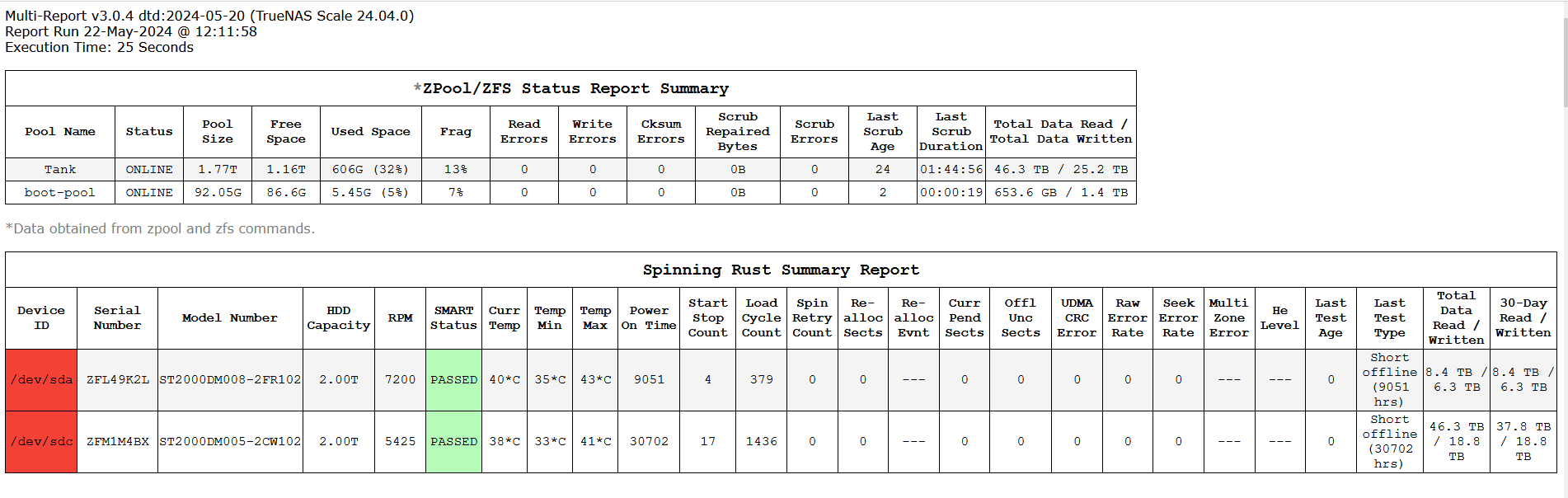
I am running the latest script on both servers and do not have the issue of red device id’s. I currently do have one server with one drive that is failing (bad sectors) and its id is red as it should be.
Could be. I have quite a few SMR drives, will investigate further. Granted that I’m well aware of the risks involved in using them, is there any way to disable this indication?
@Cellobita Examine the “Text Section” of the email just below the graphs. You will have error messages show up there. What does it say?
NOTE: This is for everyone, if you don’t know why you have an error then read the text section for what is going on. If that doesn’t work, run the script with a -dump email to send me troubleshooting data and I will figure it out.
If there are not error messages then I screwed up, but a warning/caution should ONLY be generated if there is a message in the warning or caution log files. As previously mentioned, maybe SMR?
For argument sake, if it is an SMR issue, you can easily disable the SMR check from the command line by running the script with the -disable_smr switch. That will instantly update the configuration file. I added that feature so people could quickly disable or enable SMR vice working through the -config process.
If it is a different error message, let me know. I had an odd SSD that reported MultiZone errors, strange things that are far from normal.
It was the SMR flag, indeed. I’m disabling it for the moment, as most of my clients won’t consider the expense of replacing their SMR drives (their eyes glaze over when I try to explain the issues involved…).
Thank you all for your replies. And I myself consider this a useful feature; perhaps with the option of flagging SMR drives with a different background color (red is very drastic), just to keep reminding the user of this liability, it might be even more useful.
@joeschmuck, thanks again for your very useful script!
I do understand that Red is drastic and I actually appreciate the feedback, however (just my opinion) an SMR drive works great until it doesn’t and then someone could (and has) end up losing data.
The entire reason I incorporated SMR checking is because many people would have a failure and had no idea they had an SMR drive and it was or contributed to the cause. If they run Multi-Report, by default they will get a big red flag notifying them of pending doom. Well at least they know they have SMR drives and can take action or acceptance.
And if anyone has an alarm condition routinely, this should be addressed. Maybe it is as simple as you run the SMART Short test once a week and a Long test once a month. The default settings would have yo in alarm condition most of the time. Just change the alarm setting to 8 days (7 days + 1). If it was a drive having XX failed sectors, then generate a custom drive setting that only changes the warning limit of the sector count. You should be able to get a green board (submarine talk) and that should be your normal report. This prevents overlooking an alarm condition if it is bonafide. And if you don’t know how to zero these errors out, send me a -dump email and I will return an updated config file to fix any issues. Please do not accept the default settings as the only settings allowed, that has never been my intentions.
Well dinner time for the new kitten my wife brought home the other day.
As an IT guy, I understand - and wholeheartedly agree with - the points you are making. It is just that tech budgets in Brazil aren’t what they used to be, and most of my customers do replicate to the cloud or remote systems on a daily basis (I drew the line here, and believe me when I say it was an uphill battle…).
Anyway, being able to turn off the warning will do for now; as always, your script, considerations, and willingness to hear from your users are very much appreciated.
Glad you understand and I also understand many countries have high costs for some technologies, and electrical power. And I am willing to listen and if something needs to be a little more customizable, we can discuss it as I’m not afraid to add additional customization, but I do need to make it a bit nicer looking and some better naming of variables.
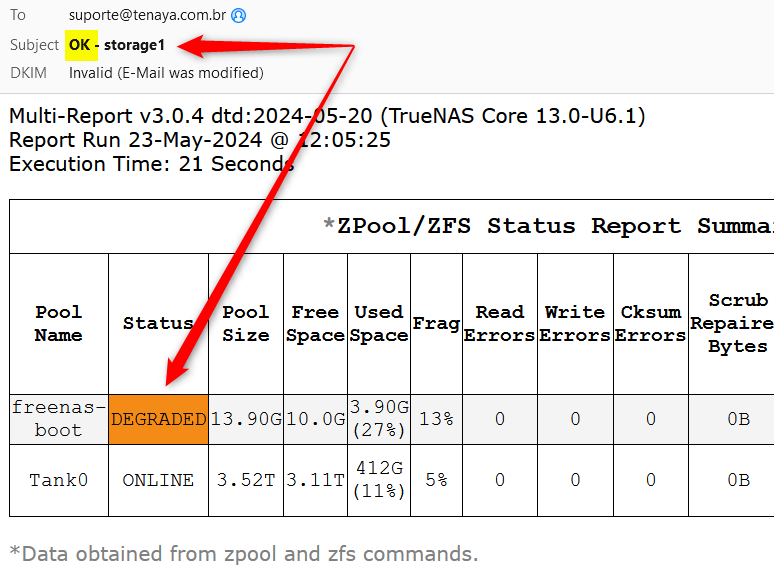
One last question (I hope…): How can I reactivate the Subject_Line_Warning for a degraded boot pool? Since 3.0.4 reports for those come with a Subject_Line_Normal one.
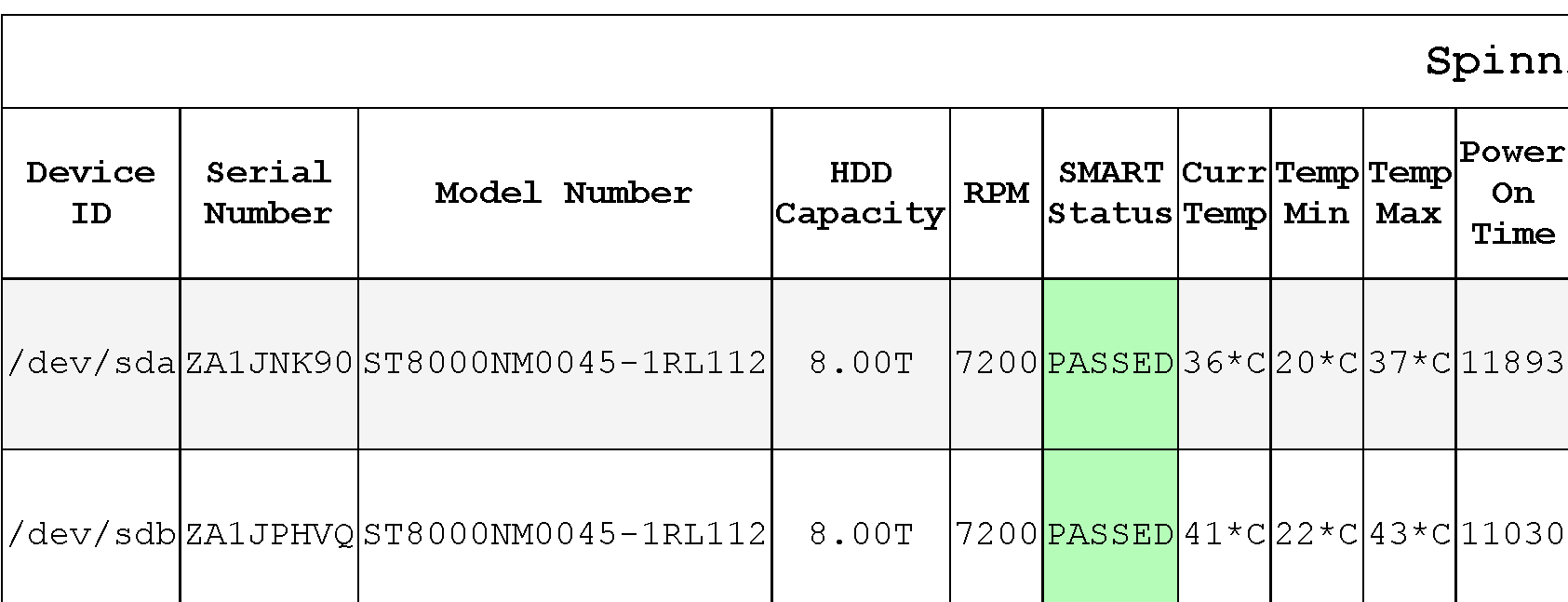
I would suggest adding a column to the spinning rust table right after the RPM column titled sonething like “CMT/SMR Detect” with the result bg color red/smr or bg color green (or blue)/cmr. This would free up the device id field to indicate a more serious fault that may be more urgent while still indicating the system is using SMR drives that could lead to data loss.