@Cellobita With respect to the Degraded Boot-Pool and the Subject Line being okay (not in alarm condition), I must have made a change and didn’t realize this was affected. That should not have happened and I will try to replicate the error and then have it fixed within the next 24 hours and message you an updated version to test and verify it is actually fixed, and then I can publish that.
@PhilD13 I like the idea however I am leary about stating the drive is CMR. The SMR script only identifies SMR drives that are listed in it’s script. Any new SMR drives not in the script yet would provide false information if I just said that if it is not listed in the SMR file then it must be a CMR drive. That is not a good way to do it. I would prefer to state it is an SMR drive when the drive is listed in the SMR script. Hope you understand that perspective.
I will see if I can generate a change to the SMR notification in the next change tomorrow.
And while I’m not fond of seeing problems with the script, I’d rather hear about it and fix it than just ignore it.
@joeschmuck
Sure, that’s fine. I would be leary too. I didn’t look if the list was coded in and thought maybe you were pulling a list from of drives from Github.
I am happy with the script and think it’s a great addition to the community, so thank you.
I find it’s a great early warning script for drives that are starting to fail if run daily. Gives a person time to order a new drive or to schedule the drive replacement before the drive actually fails.
I just saw the discussion where there could be an issue if SMR check was on and flagged the device id as red (for eing on the SMR list) and the user ignored the red flag then at some point later was also getting re-allocated sectors or some other more urgent drive issue being reported and that was what popped into my head to suggest.
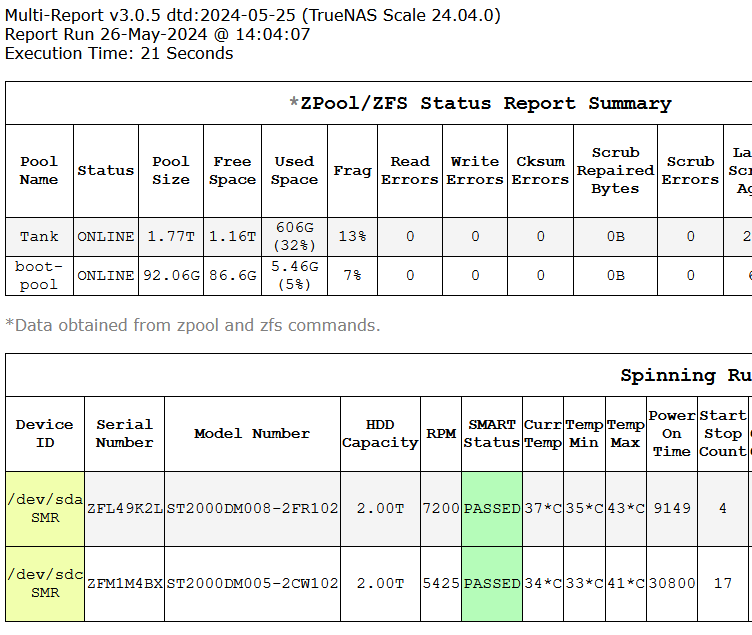
The big bug: Zpool Status alarms would not report the alarm in the email Subject Line nor in the Text Section. I induced this to test if anyone was paying attention, Ha Ha, not really. When I made a change to address a pool name which may have a space character in it, I added a set of parenthesis that I didn’t think anything about and all looked good on a system without any Zpool Status errors. The fix was a little more difficult than I expected but it is done and I appreciate @Cellobita for bringing that to my attention.
And a fix for the SMR notification. Now the Drive ID field will become a yellow background and the word “SMR” is appended to the Drive ID. Also for anyone who may have an SMR drive and accept the risk, two new command line switches to disable/enable SMR alarms. This will keep reporting in the Drive ID section if there is an SMR alarm, however no other alarm indication will be generated. This is done so a person doesn’t see the same error all the time in the email Subject line and start to become complacent reading the alarm messages.
Just received the usual batch of noon reports, all my servers have auto-updated to 3.0.5, and the subject line bug is gone. Thank you very much for your work!
FYI, after running the script with -enable_smr -disable_smr_alarm I still get a warning subject line, along with the expected yellow background for the SMR drives.
Also, the docs have a typo, the option there is spelled “-disable_smr_amarm”
P.S.: it seems the issue is with the -disable_smr_alarm command line switch - manually setting
SMR_Ignore_Alarm=“true”
inside the config file makes the script work as expected.
Yes, that is true. The command line -enable_smr_alarm (default) should set the config file to recognize the alarm, and -disable_smr_alarm should make the Subject line look normal (no alarms) again when you have SMR drives present. If you do have alarms, scroll to the Text Section and read the alarm messages, odds are (I hope) you have something else going on. If that is not the case, please let me know.
If you run the script using -help then the list of commands should be correct. I will update the user guide, you can download a fresh copy just by running -update manually, or going to the github site. The updated user guide is already done.
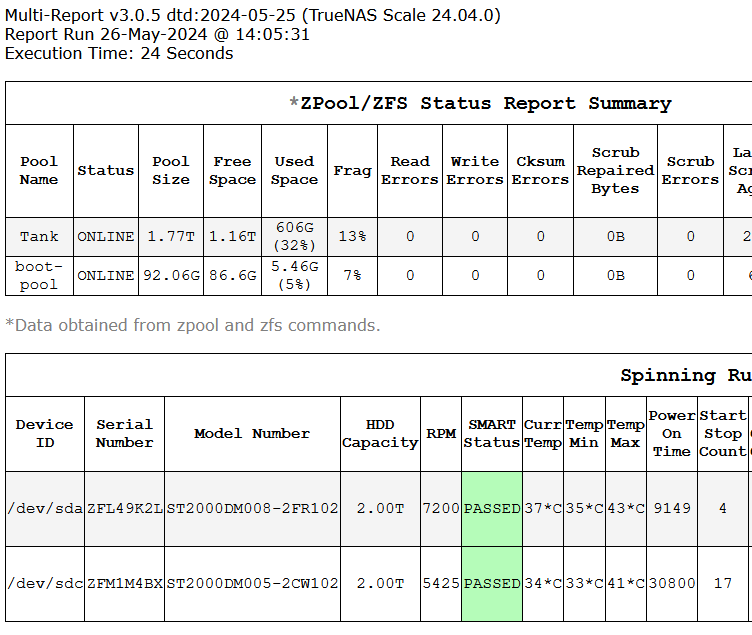
Strange. None of my (several, scattered) SMR drives were flagged in today’s server reports, either with the SMR tag or the yellow background. I have double-checked my config files, and their relevant section is the same:
Below are my settings. (which should have been the defaults (or were when I tested the beta script from cron a few days ago.)
Ensure you understand these options.
CheckForUpdates=“true” # Will check GitHub for updates and include message in next email.
AutomaticUpdate=“true”
SMR_Enable=“true” # Will enable SMR operations if set to “true”.
SMR_Update=“true” # Will automatically download Basil Hendroff smr-check.sh file from Github. SMR_Ingore_Alarm=“false” # When “true” will not generate an alarm condition, however the Drive ID will still change the background color.
I can’t actually check at this point because I have no SMR drives, but have you tried setting the SMR_Ignore to NO?
@Cellobita
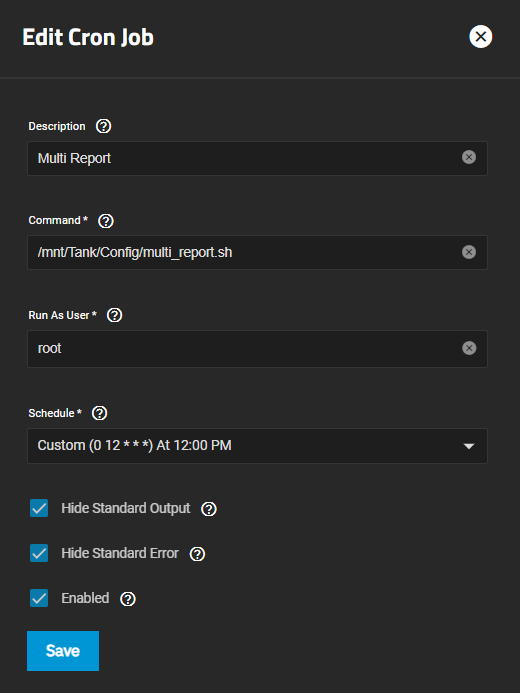
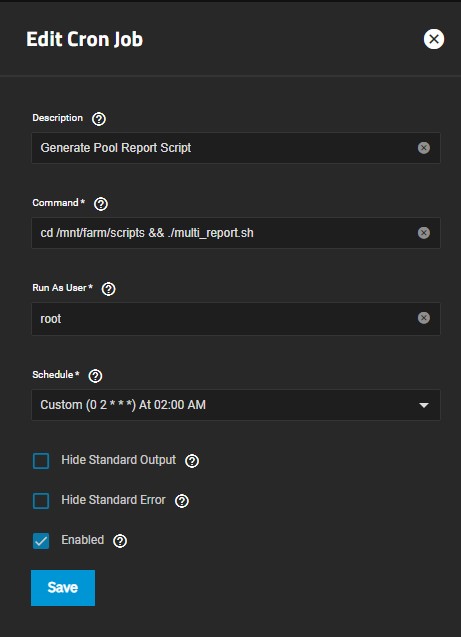
I noticed that you are using Dragonfish. I’m bootstrapping my Dragonfish server now and will verify your results. I did verify the results using TrueNAS CORE 13.3 Beta1 with no issues. I created a fake entry into the SMR script to think one of my drives is an SMR and last night at 2AM when the CRON Job executes, I received the correct indications. Give me a few minutes.
Okay, you are lucky, Dragonfish is trying to just piss us all off. The script is fine however the way you run it has changed for Dragonfish.
You need to do the same thing I had to do to get Spencer to run…
You need to: cd /mnt/your_pool/your_dataset && ./multi_report.sh
This should make it work. Dragonfish, Arg! Maybe there is another work around within the script but the next few versions of SCALE are going to be more restrictive, no ‘root’ account. Really? I can understand that for the Enterprise version. Okay, off my soapbox (for those who can remember the reference that far back), yes, I’m old.
Thanks, everyone - FWIW, I agree that a better solution would be for the script to figure things out.
Anyway, the workaround… is working, for now!
Re: beers , the offer still stands, @joeschmuck - and it is hereby extended to @Stux(whose videos have done wonders for my usage of jailmaker), if and when you guys find yourselves in my neck of the woods (Santos, Brazil)
Yes, it does write a few files to the /tmp/ directory. I have changed the majority of those from writing to a file now to writing to a variable, however there are still a few files. The next draft will be no files at all and only variables. It should be fairly simple but of course as I say that, I know in really will not be. What should take me a few hours to do will likely take me a few days. Once I have made those changes and they run from an SSH window, then I will give CRON a try. I will also try to make it run without administrative privileges, if that is even possible. I don’t think any of the commands require a privileged account, however I will find out.
EDIT: Can’t do that, I still need to create the statistical data file and the configuration file. These two are required and off the top of my head, I don’t see a way around those. So, I may be stuck writing a few files. Maybe I could include the “&&” for those uses vice the entire script. Eh, I will be working on the new script that isn’t such a mess. I will try to have that done in a few months. longer if I can do it in Python.
Please send me a -dump email so I can have all the relevant data. Out of curiosity, was it fine before you updated to 24.04.1? Once I have the data I will examine and see what is going on.
I’ve just looked back, and no it was a problem in the previous release of the script as well. I’ve already forwarded the email to you, I’ll run the -dump one when I get home tonight.
Got the email earlier but definitely need the dump. With that I should be able to reconstruct the issue. I did just update to 24.04.1.1 so i will be able to test using that version. Of course I will test on CORE as well to make sure the errors are resolved.
What struck me as odd was sdi is on partition 4. Is that real or is the script reporting false information, we will see.
The good thing is if you have a drive or pool issue, you will still get an error message and the correct drive.