Thenish17,
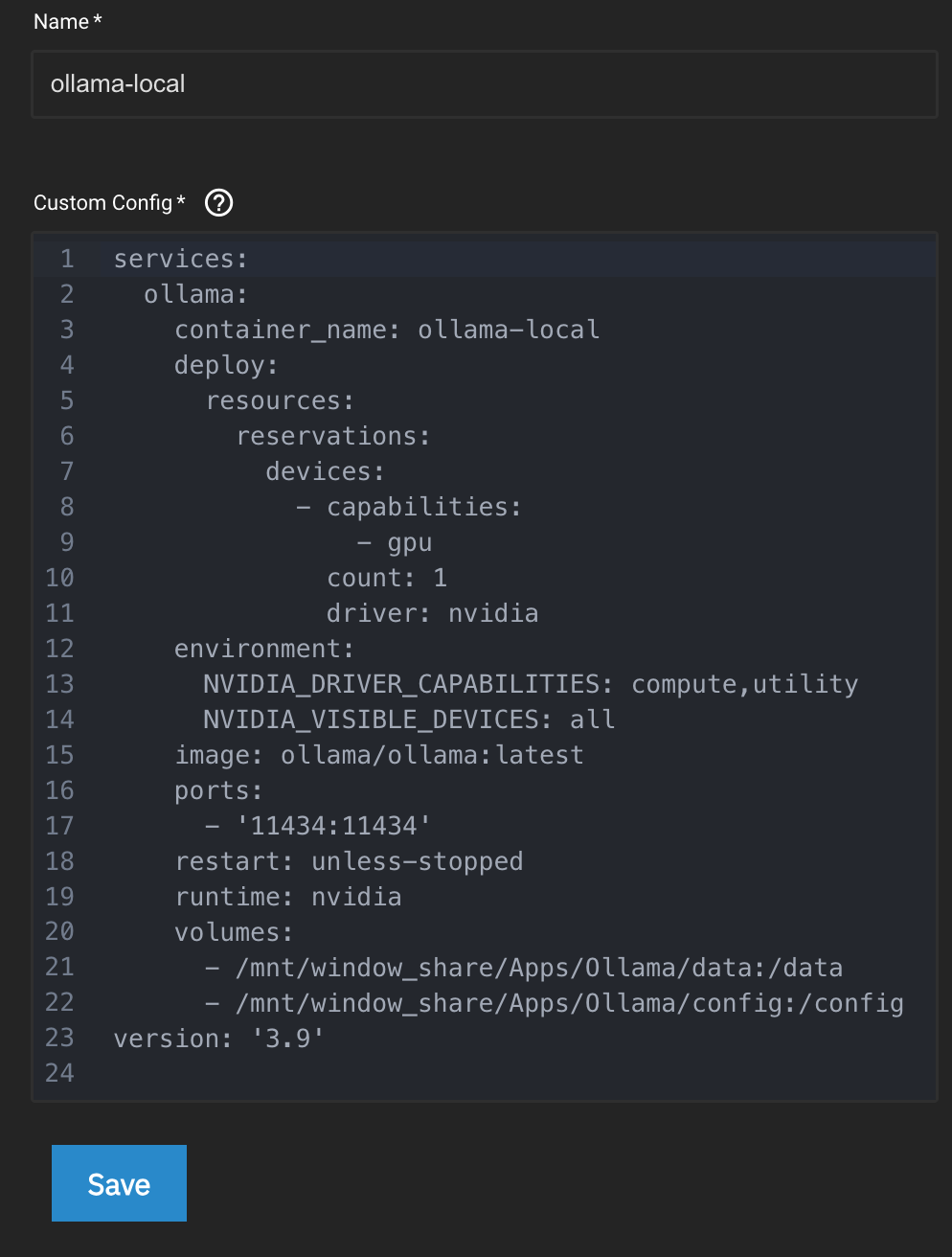
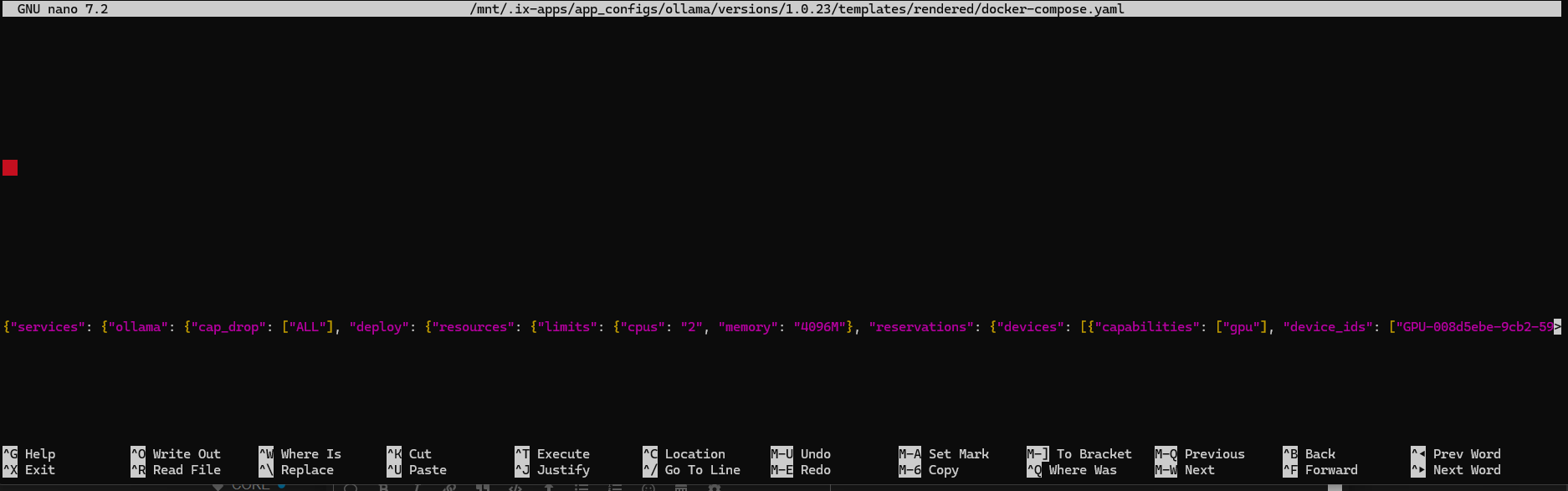
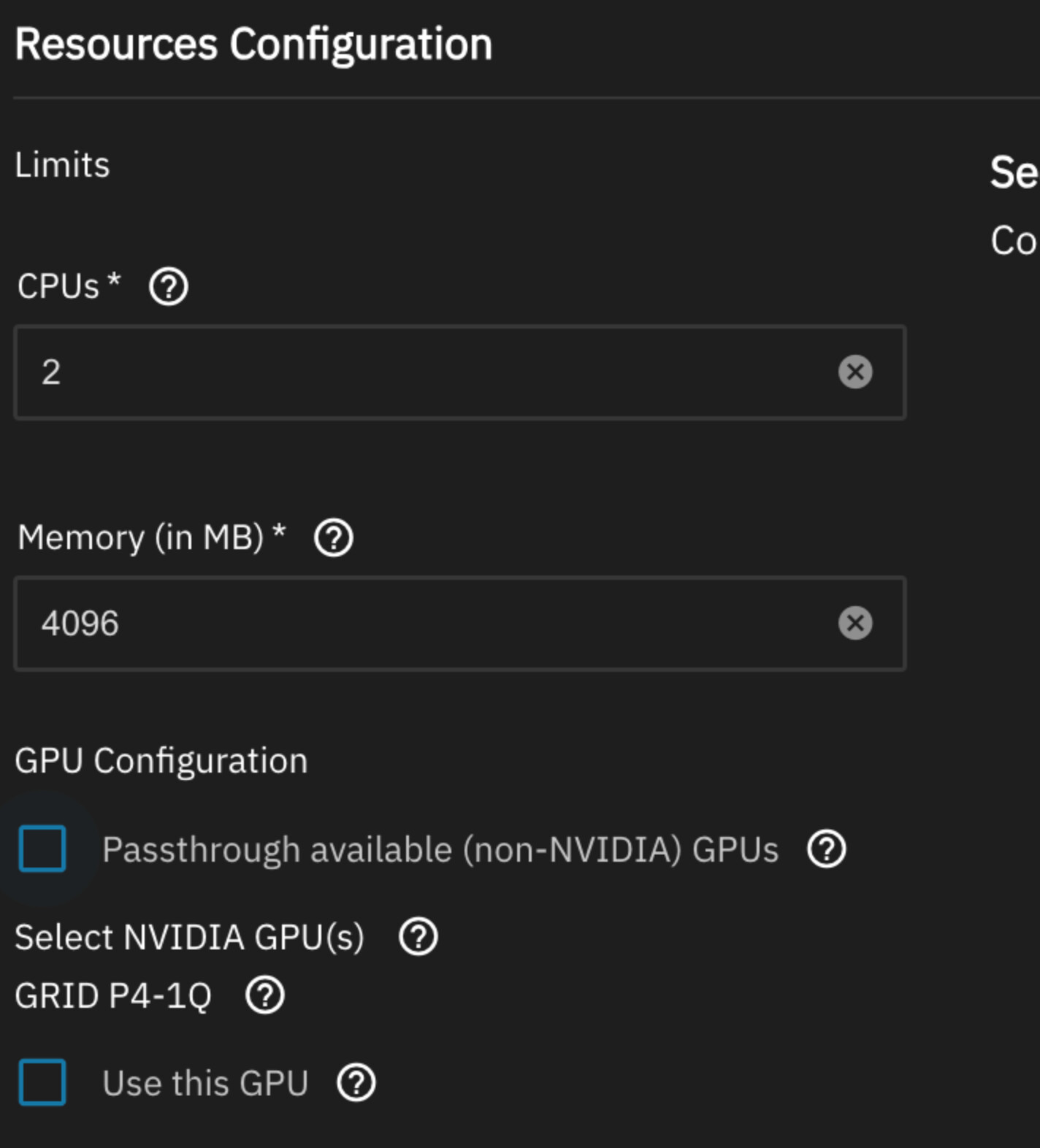
So I was intentional, given your guidance, making sure to put the installed GPU ID in the YAML:
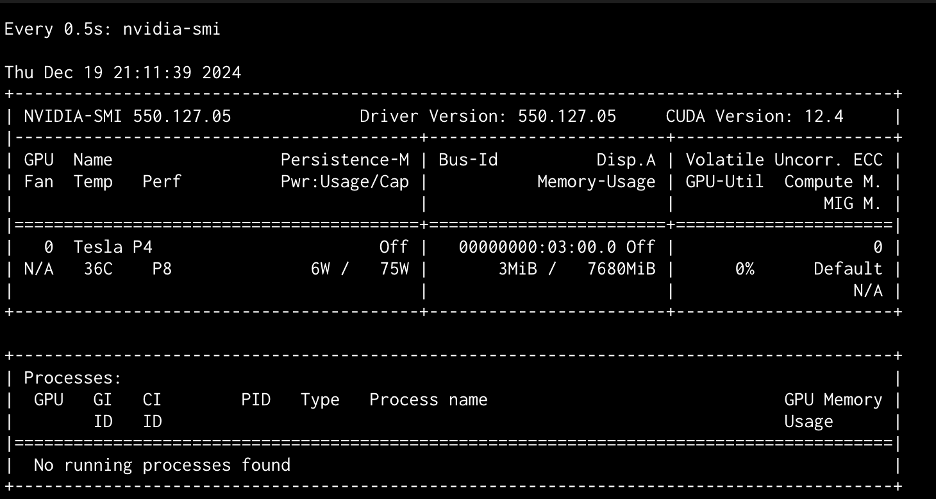
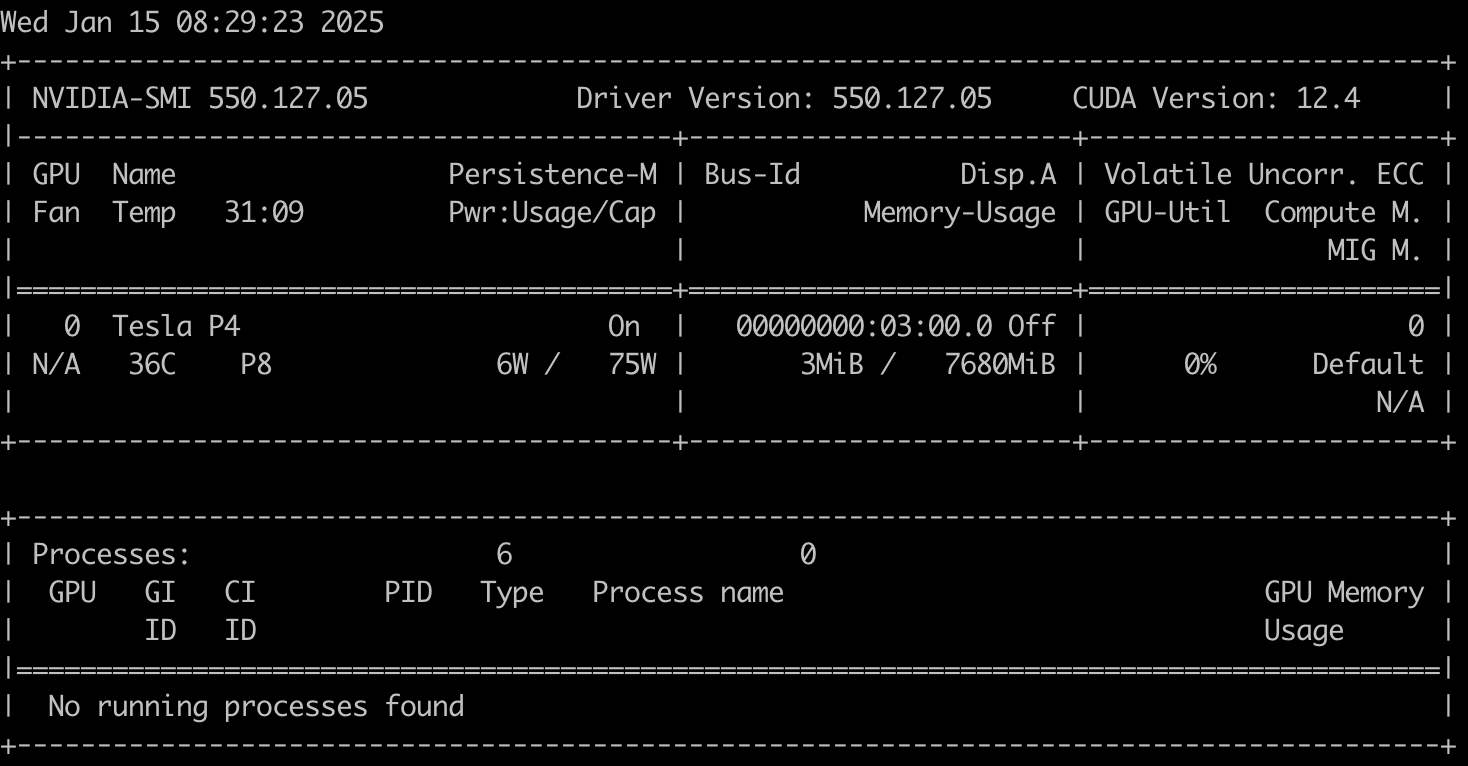
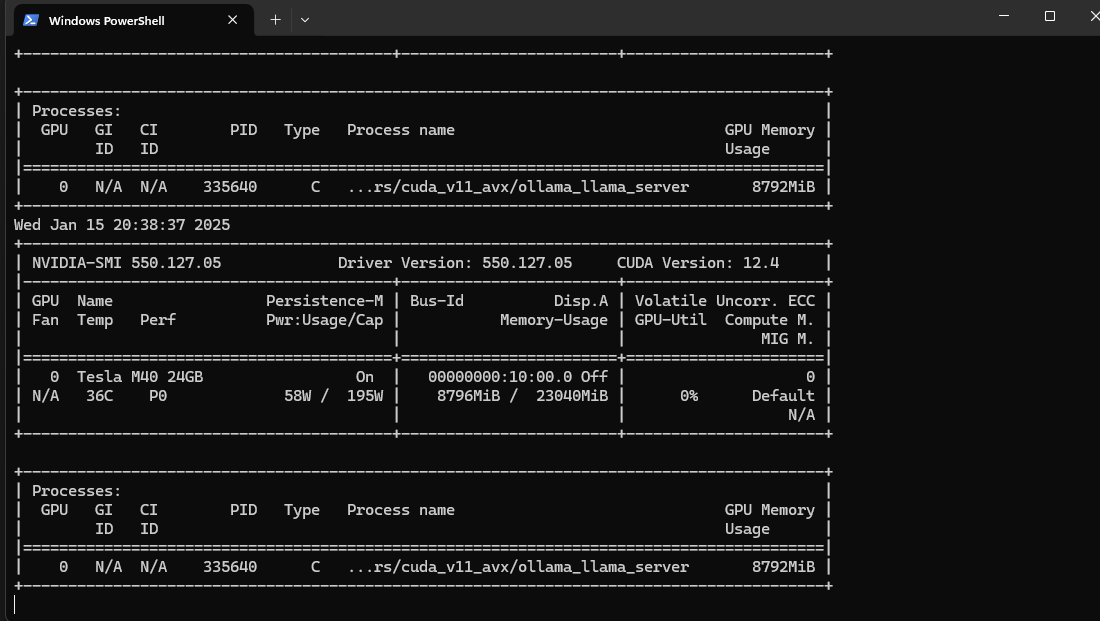
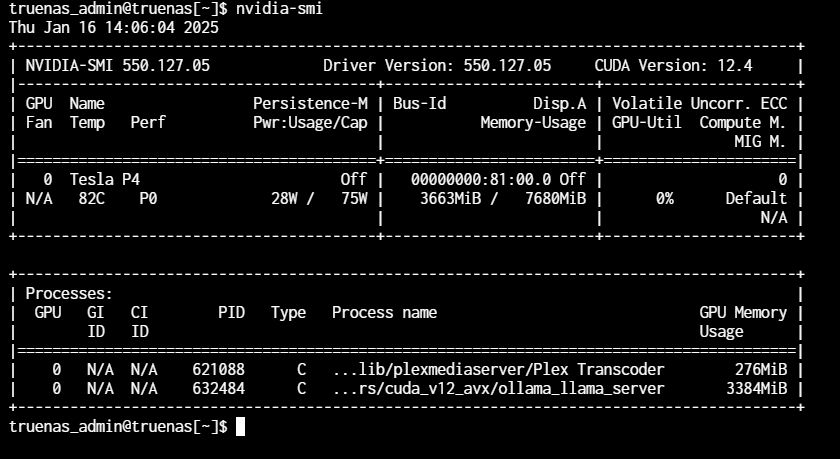
Things still didn’t work, as all 12 system cores throttled to over 100% and the temperature spiked to over 80 degrees C.
The use case I’m running, I’ll note is a little different than what a lot of folks do, perhaps. Typically I see users wanting to accelerate for video transcoding. For that use case requires a different set of installed drivers, as I’ve learned recently.
And Plex doesn’t seem to support use of Nvidia GPU cards, so I’ve installed Jellyfin instead for serving up movies. But it’s also worth noting that if one gets Jellyfin to transcode, using an Nvidia GPU card from a container, that doesn’t mean that acceleration on an Ollama LLM container will work with the same GPU.
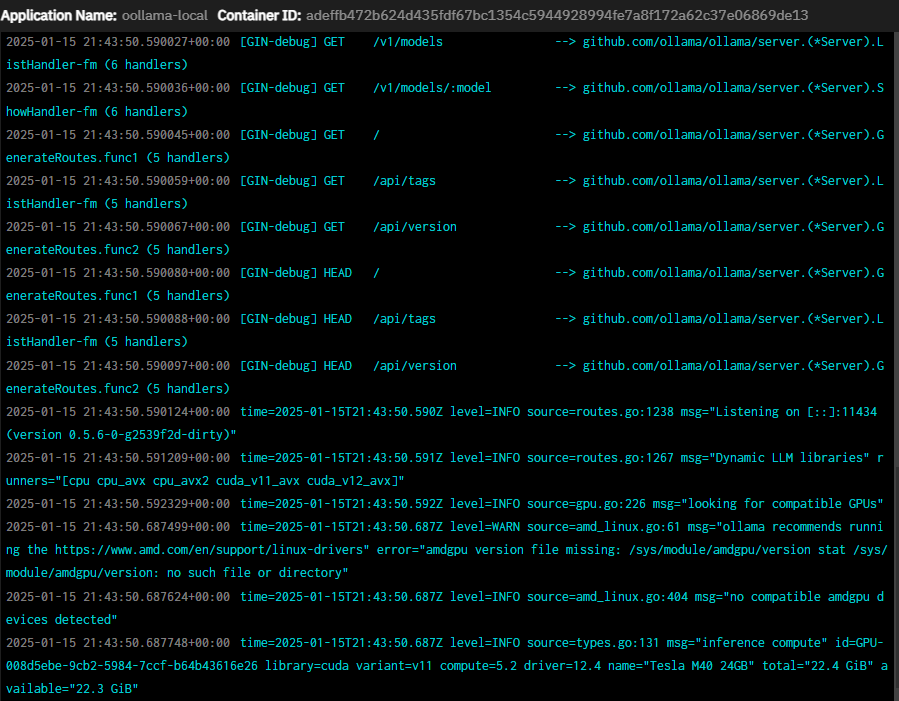
Turns out CUDA drivers (the toolkit) are not required to transcode, while Ollama LLM acceleration is a CUDA workload that requires the CUDA toolkit be installed.
While it’s possible to control the GPU card VIA the installed driver and get transcoding to work, it appears the current installation of TrueNAS EE does not include the Nvidia CUDA toolkit, which is essential to running CUDA workloads like Ollama LLMs. This can be seen by the following command: nvcc --version. Also, base level driver control can be demonstrated by changing persistence mode with the following: sudo nvidia-smi -pm 1.
The first command demonstrates whether the CUDA drivers are installed, while the second command sets or unsets the idle condition.
It seems to the way to fix things is with the following command, however, apt is not supported on TrueNAS Scale:
sudo apt-get install nvidia-cuda-toolkit
Guessing the big question is, can users lobby these drivers be added to a build, or are these drivers already be there and a defect should be logged?
Thanks for your help!
-Rodney