I’ve read hundreds of posts with regarding the types of caches, whether you need them or will benefit you in your setup, and what they can/can not do for you. I’ve read probably 5x as many responses saying “no, you don’t need that” and “my god don’t enable metadata cache and cause a single point of failure”. What I’ve not been able to find is a factual guide that describes what stats/values need to be evaluated to determine if a cache will provide any benefit and what commands and/or tests provide that information. Does such a guide exist, and if so where can one find it?
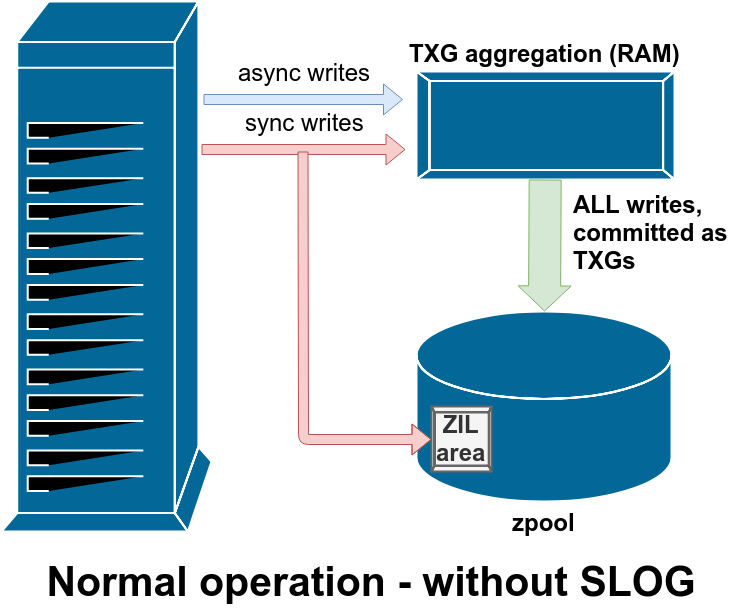
Secondly, in particular using platter drives, my understanding is that one should get [# vdevs]x[individual drive throughput] read and write speed - roughly. Is that statement accurate, and if not how and why? By far the most confusing feature is SLOG - I have read it stated many times that although the SLOG is a write-cache it provides no benefit unless you are using synchronous writes. This is very confusing - with NVMe drives that have >50x write speeds (network limitations of course being a bottleneck) it would seem that a 4TB NVMe would be able to buffer writes up at full network speed up to 4TB before write speeds slow to the maximum speed allowed by the platter drives as the buffer clears. So why does a SLOG provide write speed benefits only when using synchronous writes? Is there a cache type/configuration that allows asynchronous writes to be buffered until the NVMe cache buffer is full? Whereupon data can be transferred after the fact from the NVMe buffer to the lower speed platter drive storage dataset? My personal observations indicate that transferring to an NVMe dataset complete the transfer at the maximum speed of the network (assuming the NVMe is not full). 10Gbps LAN’s having transfer speed of 1.25 GB/s are faster than platter drive write speed.
I don’t mean to ask the same questions that have been asked hundreds of times before, but I’m still missing something. Any info is much appreciated. Thanks!