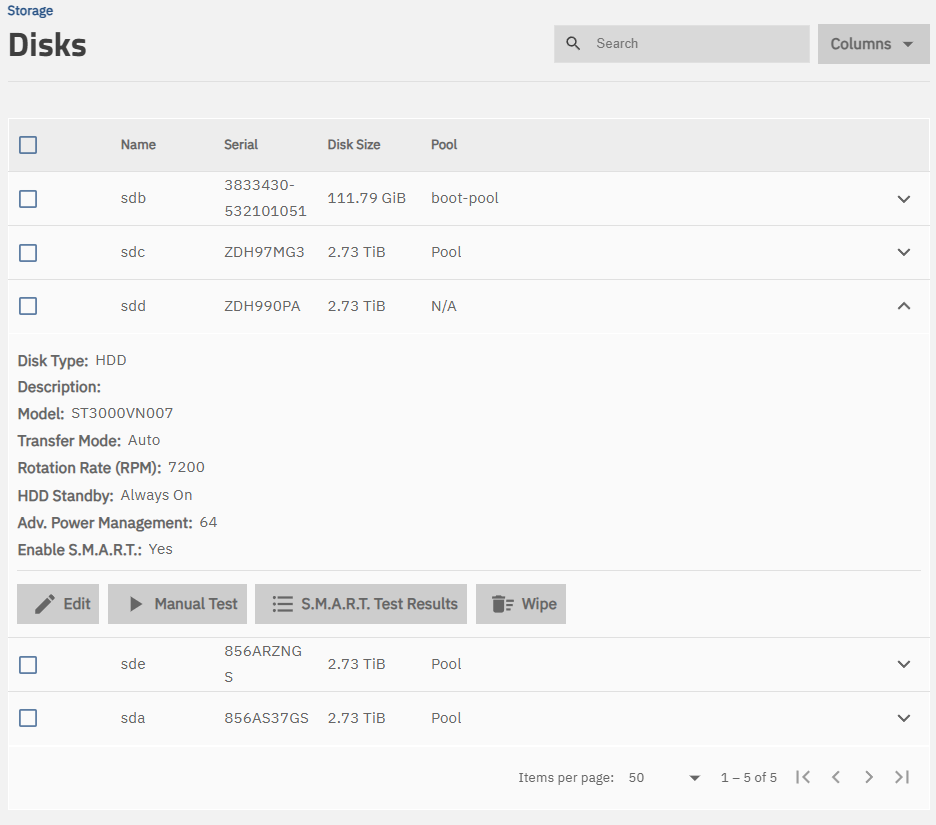
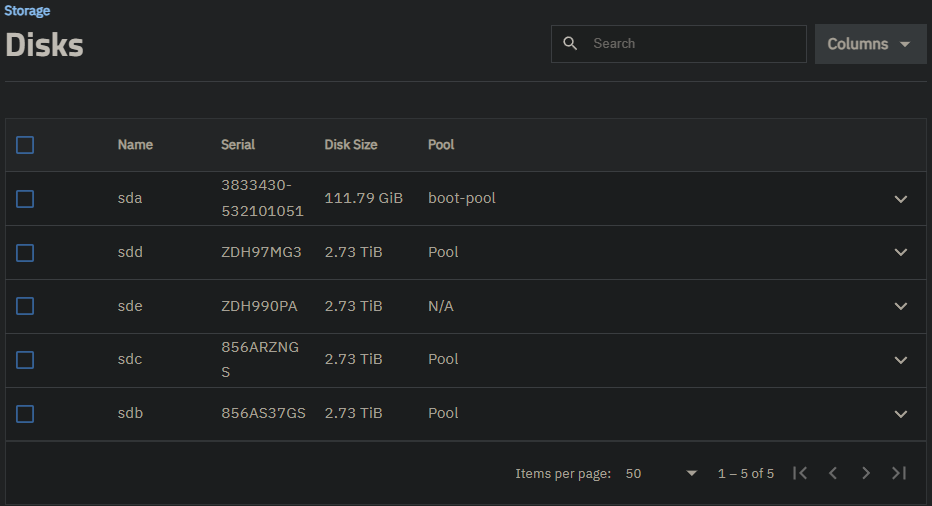
After the update I discovered that the pool has degraded because one of four disk is marked FAULTED under Storage>Pool Devices It has no ZFS errors and SMART scan returns no errors.
When trying to set disk Online or add the disk to the pool I get:

More info reveals this:
Traceback (most recent call last):
File “/usr/lib/python3/dist-packages/middlewared/job.py”, line 515, in run
await self.future
File “/usr/lib/python3/dist-packages/middlewared/job.py”, line 560, in run_body
rv = await self.method(*args)
^^^^^^^^^^^^^^^^^^^^^^^^
File “/usr/lib/python3/dist-packages/middlewared/service/crud_service.py”, line 287, in nf
rv = await func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/usr/lib/python3/dist-packages/middlewared/schema/processor.py”, line 48, in nf
res = await f(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^
File “/usr/lib/python3/dist-packages/middlewared/schema/processor.py”, line 174, in nf
return await func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/plugins/pool/pool.py", line 762, in do_update
await self.middleware.call(‘pool.format_disks’, job, disks, 0, 80)
File “/usr/lib/python3/dist-packages/middlewared/main.py”, line 977, in call
return await self.call(
^^^^^^^^^^^^^^^^^
File “/usr/lib/python3/dist-packages/middlewared/main.py”, line 692, in call
return await methodobj(*prepared_call.args)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/plugins/pool/format_disks.py", line 27, in format_disks
await asyncio_map(format_disk, disks.items(), limit=16)
File "/usr/lib/python3/dist-packages/middlewared/utils/asyncio.py", line 19, in asyncio_map
return await asyncio.gather(*futures)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/utils/asyncio.py", line 16, in func
return await real_func(arg)
^^^^^^^^^^^^^^^^^^^^
File “/usr/lib/python3/dist-packages/middlewared/plugins/pool_/format_disks.py”, line 22, in format_disk
await self.middleware.call(‘disk.format’, disk, config.get(‘size’))
File “/usr/lib/python3/dist-packages/middlewared/main.py”, line 977, in call
return await self._call(
^^^^^^^^^^^^^^^^^
File “/usr/lib/python3/dist-packages/middlewared/main.py”, line 703, in call
return await self.run_in_executor(prepared_call.executor, methodobj, *prepared_call.args)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/usr/lib/python3/dist-packages/middlewared/main.py”, line 596, in run_in_executor
return await loop.run_in_executor(pool, functools.partial(method, *args, **kwargs))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/usr/lib/python3.11/concurrent/futures/thread.py”, line 58, in run
result = self.fn(*self.args, **self.kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/plugins/disk/format.py", line 33, in format
self.middleware.call_sync(‘disk.wipe’, disk, ‘QUICK’, False).wait_sync(raise_error=True)
File “/usr/lib/python3/dist-packages/middlewared/job.py”, line 487, in wait_sync
raise CallError(self.error)
middlewared.service_exception.CallError: [EFAULT] [Errno 5] Input/output error
Any ideas what has gone wrong?