… so after like ±20 fresh, full, reinstalls over 1 month, after i bought 2 new intel’s NIC’s, finally this piece of art started to work. And it worked whole full one day !!
Today i’ve got this very strange “error” and got confused. Would be very nice to see dev’s comment, but probably they are not using this forum.
There is no explanation, there is no output, there is no link, there is nothing, just a stupid error. I mean why do you make “notification”, that does not contain any useful information.
What the f… i suppose to do with it? Come here and write a post? This is how the product designed? If there is error in GUI, you come to forum and write a post?
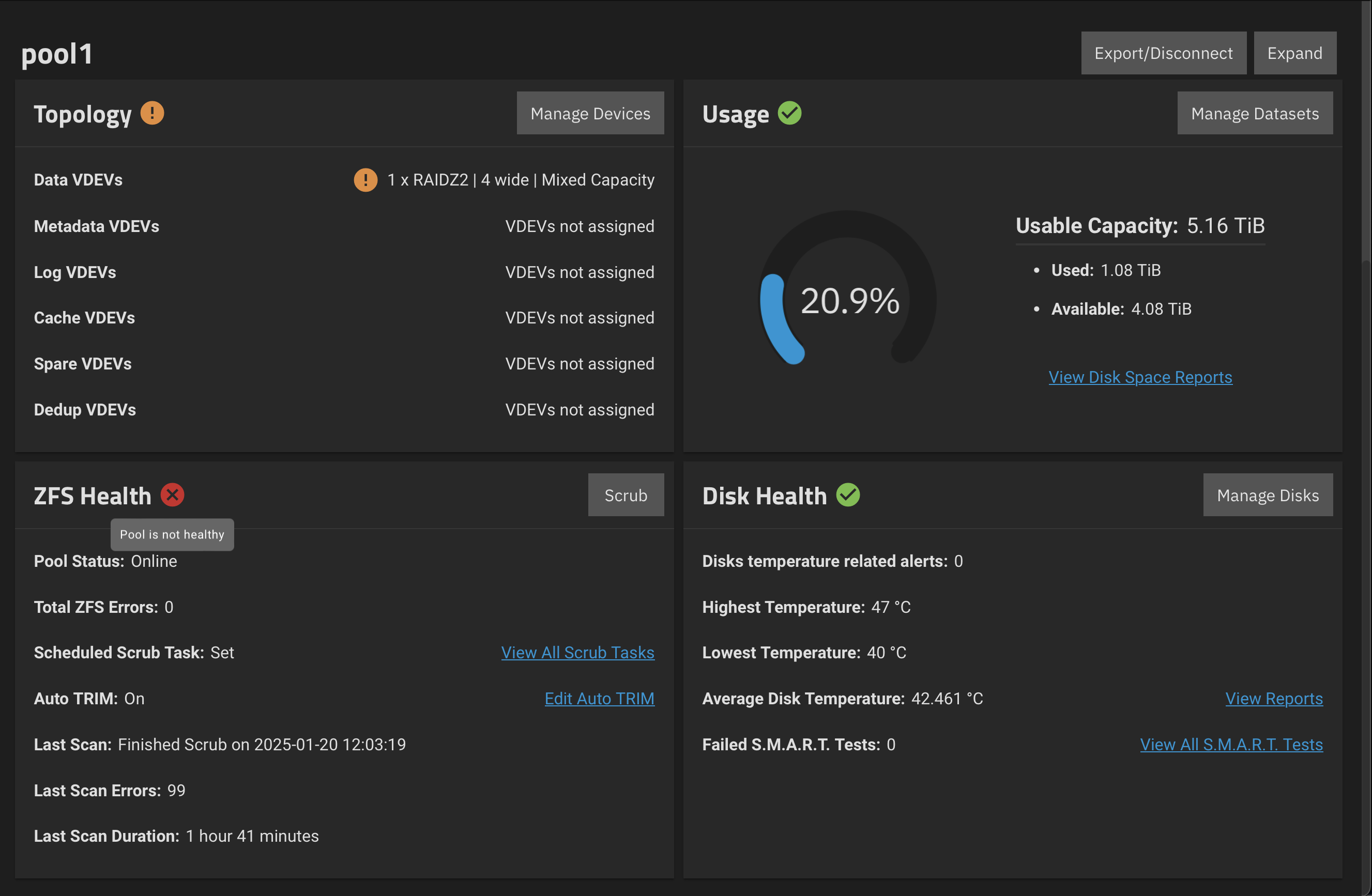
…it would be 1000 times easier and more clever just to show the error’s output. Or show the link. I mean If you want to tell something, you can do it. Just pass the f… output somewhere!! Pool is not healthy, so …? Do i have to press nearest button “scrub” ? i did it, but it does not fixed.
Links and hyperlinks are in our everyday life since 1980-1990. Try them and use them.
Do you want to rant, or do you want to figure out the problem? If the former, well, carry on, I guess.
If the latter, the Manage Devices button will take you to the pool status page, which will show you which drive(s) are having problems. But for more involved troubleshooting, you’ll need to use the shell. A good resource for this process is:
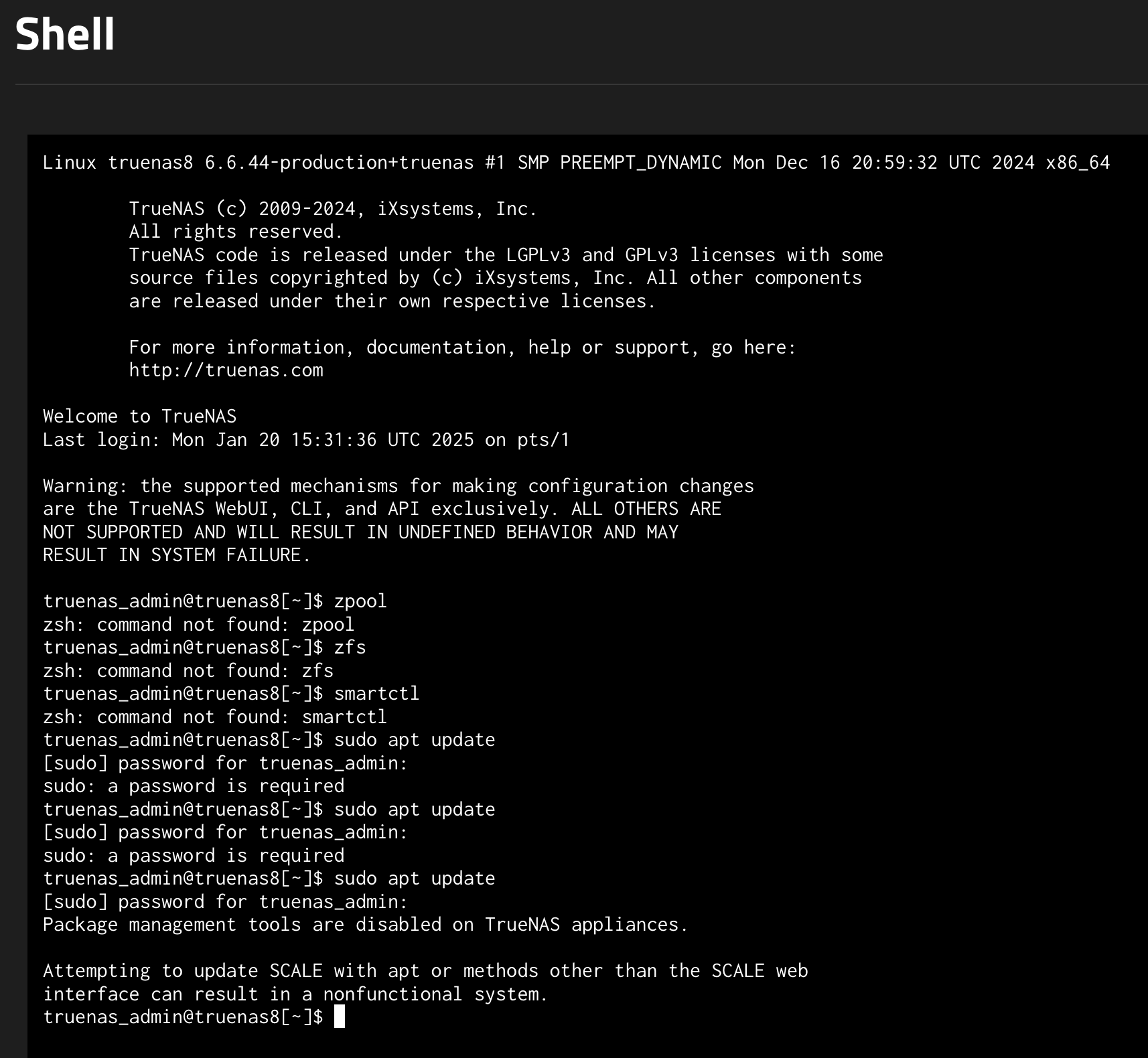
@etorix thank you. I went to the link you provided. I see there a standard commands, like zpool, smartctl, zfs. It is extremely strange, why distribution that is oriented work as NAS, missing these standard commands:
I would agree, but the error per your screen shot is that a bunch of files failed check-sum validation during a scrub. The screenshot does indeed show this.
Though I guess the followup could be “why not tell me which files failed” or better yet “tell me why they failed”. For the first, because it likely isn’t an issue with the files. For the second, because it would take investigation to proper address; if it tells you an hdd died, when really it was a bad data wire; you’d likely be angry when you waste money on a replacement drive, trusting the error blindly.
I’d argue that this is more like a check engine light on your car - it is advising something isn’t right. Now you or a mechanic can use an obd scanner to get more info, then start diagnosing what has cause this to trip. Anyone who has worked on cars can likely share how the light, code, and sensor may not directly point to the issue in question & that without some investigation things can quickly get expensive & not addresss the issue that caused the code to trip in the first place.
Could there be documentation on step by step troubleshooting hyperlinked onto the error? Maybe, but I’d argue that is a bit much to expect for a free os.
IMO, the issue is less the free OS and more that there’s only so much you can stuff into the GUI, and lots of users have been saying for a long time that the GUI’s overloaded. RTFM, folks–and “TFM” includes not only the manual itself, but also the wealth of user-generated documentation on the forums and other sources like my wiki. Yes, some of it is a little out of date–Joe’s guide doesn’t account for iX’, um, curious design decision to not include system admin tools in the system admin user’s path, for example. But the information is out there.
Yeah, that’s just a nonsensical design decision on iX’ part.
The [Accepted] tag in the title suggests iX has (finally) decided to implement it. Of course, the lag between “accepted” and “implemented” could be several years, given past history (think about the GUI file manager that’s been pending for, I think, eight years).
In regards to the PATH of ZFS commands, it does appear that they will be added to SCALE for normal users. One reason given is to allow Core users to migrate to SCALE easier. FreeBSD / Core already has normal user access to /usr/sbin & /sbin.
As for SCALE being completely user friendly, I think some people need understand the original, (and in some ways the primary), focus of TrueNAS: Enterprise customers with Data Centers.
Such users, (and I am one, though not with NAS products, different team), know the underlying OS and command line trouble shooting. While the Enterprise customers may have both junior and senior staff members, with the juniors unable to trouble shoot further, the senior staff should be able to continue without GUI help.
Now does that excuse simple help when encountering an error?
Not really.
But, no product is perfect. All software is a “work in progress”. So, yes rant, yet on the other hand make clear and useful Feature Requests in the that section of the forum.
TrueNAS SCALE seems to have brought in thousands of new SOHO users, (aka Non-Enterprise users), with many different expectations or skill sets. So, make Feature Requests when it seems appropriate.
Hyperlinks, etc, would be nice little shortcuts but there are a few things you can do to get to the bottom of what’s going on. Take my recent example. Now, my ZFS checksum errors came to light when I replaced one bad (7200RPM) drive with a new (5400RPM) drive. I did this intentionally to see what the effects would be and since its replacement three weeks ago, I have been getting the very occasional ZFS checksum error for it.
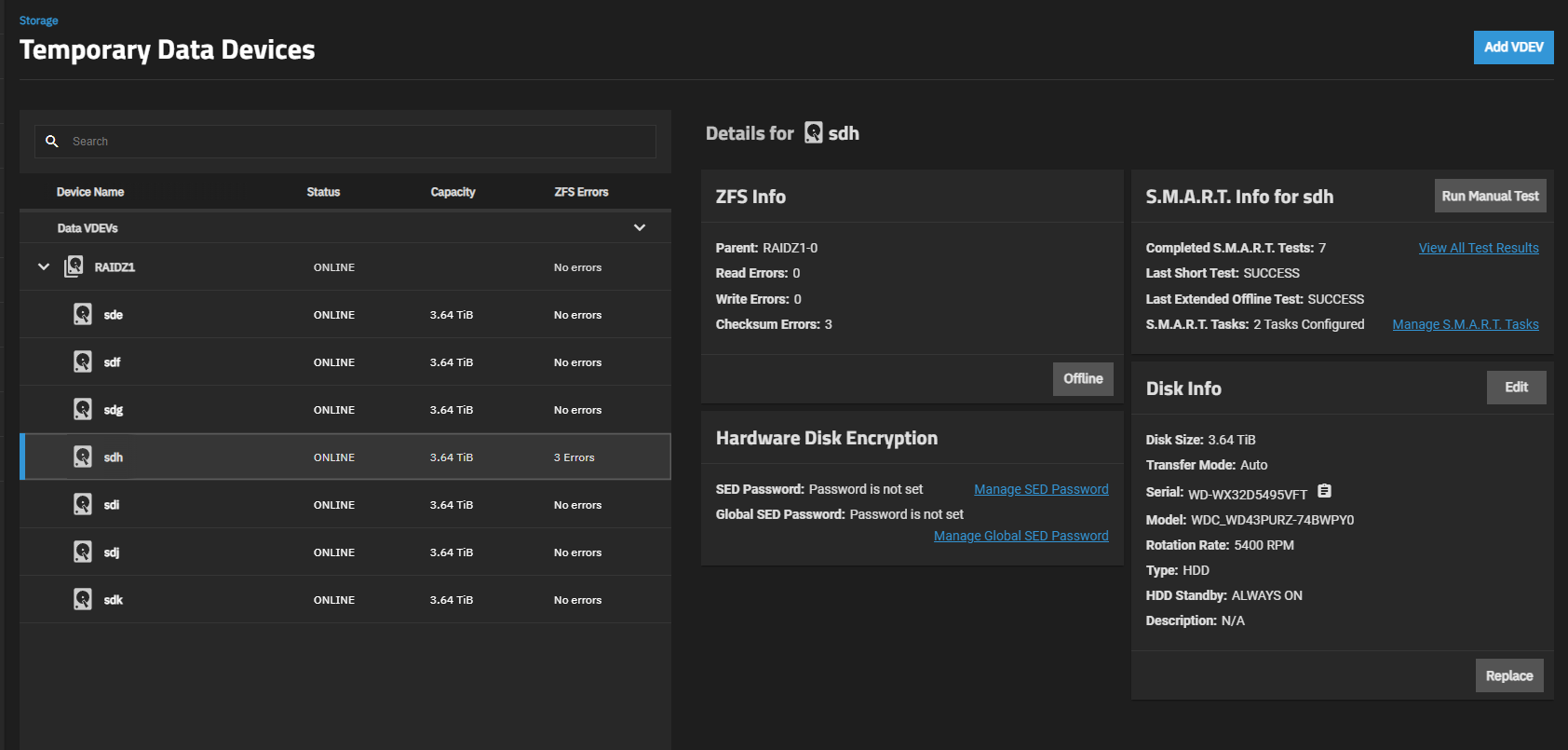
I have alerts for it, which go into detail which drive is affected (the 5400RPM) and by simply clicking my way in from where the error is being reported, as it is for you as well (“Manage Devices”) then expand the affected pool to reveal the affected drive, then click on that drive, I get the following:
I’m not concerned because this is a product of my own making and the data is just surveillance camera recordings, whereby the effect is only milliseconds of recordings lost, once in a blue moon but the point of this is that the diagnostics are there. It would be nice to know which file was affected by this but at least I have an understanding of what is going on by the drive detail itself.
I can appreciate your month-long journey may have been frustrating but you’re in good hands within both this forum community and the developers. Just chill out a little and expect to be pleasantly surprised by the support you’ll receive. Hang out in the Discord forum too.
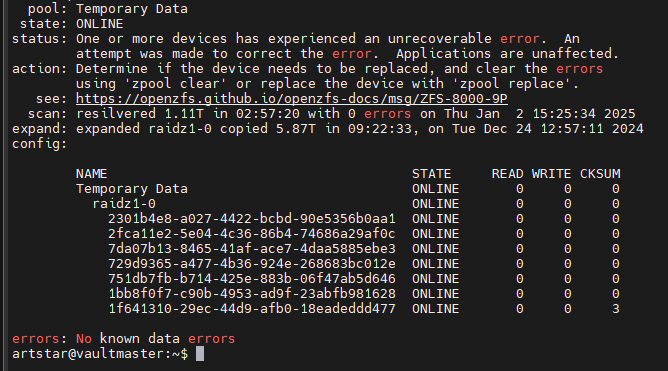
The output of the following command would list any affected files or metadata: sudo zpool status -v pool1
Checksum errors tend to be recoverable. Either by re-trying the request or by redundancy, RAID-Z1 in your case.
Note that by default, ZFS considers standard metadata, (aka directory information), more important that data, so 2 copies are available. Regardless of redundancy. This is because loss of a directory entry could mean the loss of the data it points to. That feature is controlled by these 2 dataset parameters:
copies
redundant_metadata
If “copies=1” and “redundant_metadata=all”, you get 2 copies of metadata.
I mention this because it is less likely to loose metadata, even on a single disk pool. Thus, if you do have data loss, it is more likely file data.
You have three chksum errors on one of the disks.
This is often (but not always) due to a cabling issue.
What you can do is do a sudo zpool clear “Temporary Data” which will remove the errors - then scrub the pool. if errors then come back you know you have an issue somewhere.
To help further we will need to know how the disks are connected to the motherboard as well as a complete hardware list
BTW - it is a classic mistake to use Pool Names / Dataset Names / Folder Names with spaces in them - it just makes things harder. This has no bearing on your chksum issue - its just a general mistake
Agreed but this only surfaced after I replaced a dying ten year old 7200RPM HDD with a brand new WD Purple (5400RPM) drive.
Did that (sudo zpool clear Temporary\ Data) after the first time I got that error. It survived two scrubs before I got one per five days which were just through regular use, given they all occurred after the last scrub.
Supermicro A2SDi-8C-HLN4F, 64GB registered ECC RAM, Supermicro CSE-933T-R760B chassis. Drive backplane connected via two Mini SAS-HD breakout cables and four individual SATA cables for the remaining ports on the motherboard. Swapped around SATA connectors to determine if the problem stays or follows the cable. It stays with the drive.
I’m surviving fine, thus far. I wouldn’t call it a mistake though, just bad practice. Being my homelab, I do a lot of things which are against good practice to observe the results. Makes it easier to understand in a real-world situation what might be the root cause of a problem with similar symptoms out in the field.
Same way that I wouldn’t mix RPMs in an enterprise solution at work but I still need to observe what happens when rules are broken. The theory of the vdev working to the lowest common denominator may not always be the case, it seems.
In regards to the problem coming back. If you truly don’t have a cable problem, then it is likely the WD Purple disk does not like ZFS.
While those WD Purples are supposedly CMR, (Conventional Magnetic Recording), Western Digital has pulled fast ones before and substituted in SMR, (Shingled Magnetic Recording). Or perhaps these WD Purples have a firmware bug, (WD Red SMRs have one, or at least did have one).
Not sure what you mean by that. If there was a checksum error (and fixed it), it would still be nice to know which file was affected, even if it was momentarily.
Interesting. I would be amazed if they used SMR for a 4TB drive and I did check their datasheet because I’m never one to work on an assumption. Given the age of the remaining drives in the vdev being between nine and ten years old (hand-me-down WD Golds from my workplace), I’m sure the remaining six will be replaced within the next two years, so I’ll know by then if my theory of the 5400RPM lamb among the 7200RPM wolves is true or if your theory about the WD Purples is true.