EE RC2 is still a release candidate, however I have not heard of a person having any problems running Multi-Report on EE, and never a report against the boot-pool.
The error message does not list what caused the error, however if you say running Multi-Report caused it, I will not argue that as I can’t prove or disprove anything from my end. I would ask you one question: Did you follow the guide on installing the script correctly? Okay, two questions… Where did you install the script? All I can suspect it that you are trying to write to the boot-pool which is not desired and probably not possible without unlocking the destination, which I will not have the script perform.
However, I am thinking you are wanting to troubleshoot the exported disk issue so I will stay focused on that.
TrueNAS has not fully implemented NVMe support yet, not even in EE RC2 based off of my recent testing and examination of the smartctl.py file to build TrueNAS. However that should not cause the pool issue you are seeing.
Some more questions:
Did you create these pools before you installed EE?
Did you upgrade the feature flags? (I am not suggesting that you do, I certainly do not myself)
Have you rebooted (powered off, wait a few seconds - like 10 seconds, power back on)?
Are you running TrueNAS on bare metal or in a VM?
Add any other details you can think of, such as hardware you are using as it may not be important however it could be the clue needed.
Run a long smart test on your boot pool and then post the result, my guess is that there is something wonky with the drive… but you could also try a fresh install.
Thanks for your detailed answer @joeschmuck Really appreciated.
I don’t remember if I first installed truenas scale dragonfish and then installed EE from there.
So I propose to start with the obvious:
I will try re-install truenas scale with a clean electric eel RC.2 or, since it is just 10 days away, I will wait for the official release of EE. After that I will try to see if boot-pool issue is still present (if it still shows as exported) and if yes, then I’ll give a try again with multi-tool to see if it crashes the system while the script runs.
Read Self-test Log failed: Invalid Field in Command (0x2002)
Therefore for the time being, I’ll probably order a smaller sata SSD drive. Then I’ll do a clean installation of truenas scale when EE is released and let’s hope that everyone solves by itself. Thanks for the help
NOTE: This is ONLY for SCALE (Linux). It will fail on CORE (FreeBSD).
The device commands:
From the command line enter (you can cut/paste if you like) nvme device-self-test /dev/nvme0 -s 2 to run a long test on drive nvme0 (your boot-pool). This will likely take less than 10 minutes to complete. If you are using EE RC2 you can then use the smartctl command to read the result smartctl -a /dev/nvme0 and view the test results.
Some extra info: A Short test command is nvme device-self-test /dev/nvme0 -s 1 to run a Short test on drive nvme0 and that will take 2 minutes or less to complete. Of course you can run this command on the other nvme drives you have all at the same time, just replace nvme0 with nvme1 or nvme2 and send the command.
NOTE: This works on CORE and SCALE.
2. The smartctl commands:
This should work fine from EE RC2, use smartctl -t long /dev/nvme0 and wait 10 minutes, then use smartctl -a /dev/nvme0 to read the results.
To run a short test is almost the exact same command, smartctl -t short /dev/nvme0 and of course you can run all the drives at the same time, just issue the command for each drive individually and wait the appropriate amount of time to check the status of each drive.
If any of these fails to work, please provide a screen capture of the command you sent and the error message. You should not have any problems with these commands. If a drive fails, that is a different issue and post those results as well.
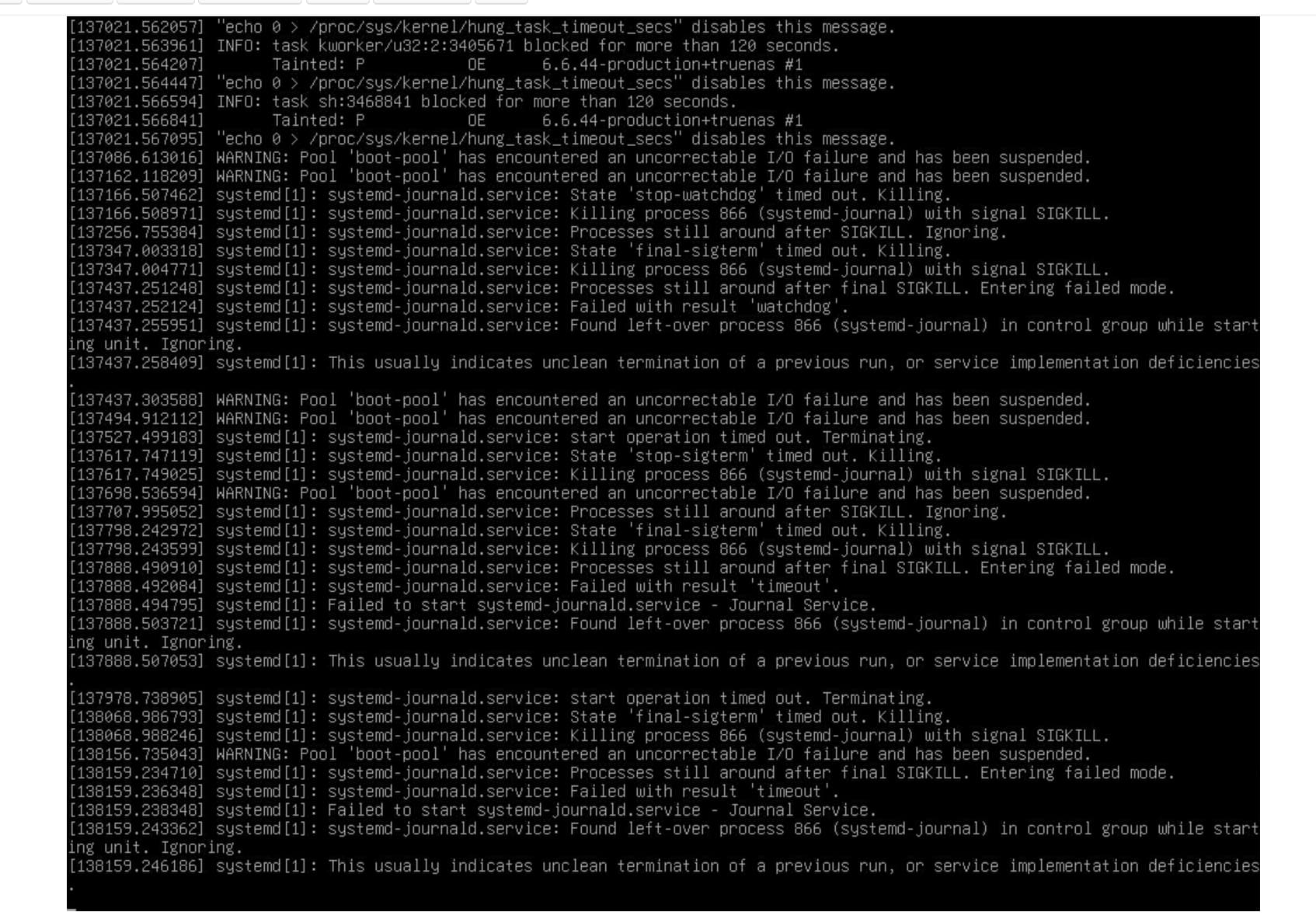
after some minutes it crashed truenas and to run everything again, I had to shutdown my machine completely, otherwise the boot-pool drive is not even recognized and GRUB doesn’t start (Logs from IPMI before restarting):
Stop using the namespace! Not a single place in my posting did I use “nvme0n1” and nvme0n1 is not the same as nvme0. nvme0 is the controller for the drive and that is what you want to communicate with.
This is the problem TrueNAS code has, they are trying to use the namespace as well and it is wrong.
While I understand you thought you were doing it properly, I feel that I must warn you about something… If someone provides you very specific commands to enter, do not deviate without asking first. It is okay to ask and verify before doing something, however just changing the command, you could cause more harm than you realize and none of us here want that. Thankfully this was not an issue in that respect however there are some commands that will wipe your data slick as fast as you can hit the Enter key.
If you are running EE RC2, the smartctl commands I provided should work fine and you should not need to use the nvme commands.
No problem, I mistakenly assumed that nvme2n1 and nvme2 is just the same thing, I did not know that there is a concept as namespace.
Anyway, I can’t test it anymore because it seems like the boot-pool drive is gone for good now
So for the moment I will need to shut-down the server and wait for another SSD as boot-pool to test again.
Any reason you are using a 2TB M.2 drive as the boot-pool? I recommend using something a bit less expensive. Maybe a nice slow 256GB NVMe drive? Gen 3? This will produce a lot less heat and the cost is minimal. A boot drive does not need to be fast, even if you use it as your SWAP space, it is faster than the spinning rust.