I made a mistake when I accidentally ran a replication task on the wrong target.
I have the following configuration:
opendataset0/subset1
opendataset0/subset2
encryptedset0/subset3
Since I wanted to decommission and expand encryptedset0, I created opendataset0/subset3, but during the replication task, I accidentally selected the wrong level.
The task then ran from encryptedset0/subset3 to opendataset0, and it ended up deleting the subsets including the snapshots.
Is there any chance to recover the subsets somehow? I’ve deactivated all scrubbing tasks, etc.
My guess is that he bypassed the GUI and ran destructive CLI commands with out realizing what they could do. The GUI is there for this specific reason.
Unfortunately that data is gone, unless you had pool checkpoint’s, backups or mirrors of that data, I’m assuming you didn’t because you’re here asking if it’s recoverable.
Hi, thanks for the answer. I haven’t executed any shell commands yet; I accidentally clicked something in the target’s tree menu via the GUI. I came across this article serverastra . com/docs/Tutorials/How-to-Recover-files-from-a-stable-and-working-ZFS-pool-when-snapshots-are-unavailable and I’m inclined to try mounting the oldest txg. It was a manual replication task through the GUI.
Actually I don’t remember clicking some checkboxes.
But it allready happened and I know I’am stupid.
The last txg from 2025-10-14 01:13 UTC.
I tried to mount it with
zpool import -N -o readonly=on -f -R /mnt/ro -F -T 12287190 int-hdd-z1
but the system only freezes and dmesg is spammed with middleware timeouts.
I think I have to face the fact, that my data is lost.
I know I’ve done this before luckily in testing just not sure if the behaviour has changed during versions. I would most likely have done this on CORE. Just testing on CE now.
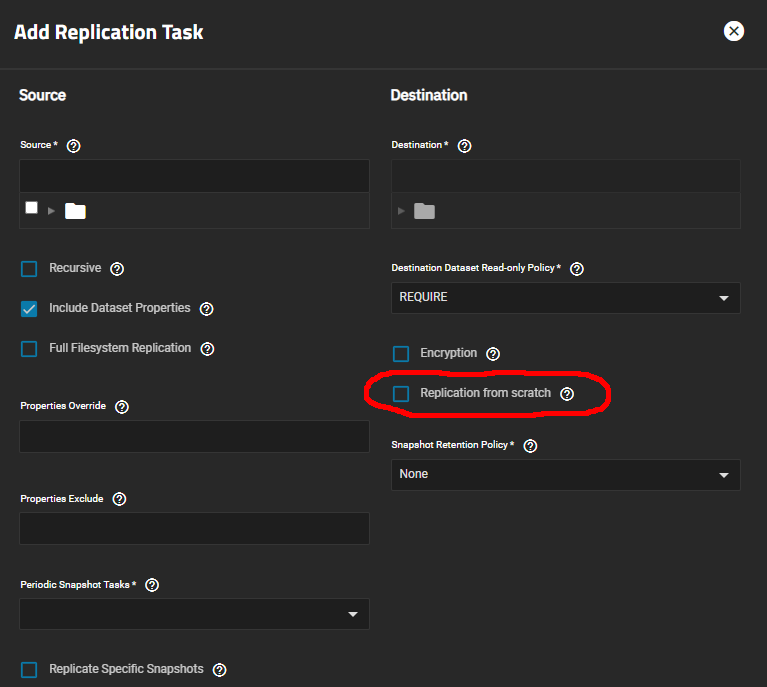
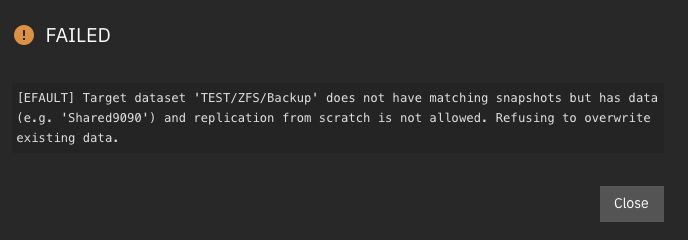
Yep, as you say unless I select ‘Replication from scratch’ it won’t let me.
Be interesting to hear what version @Gumble is running.
Even more interesting is that even if I select ‘Replication from scratch’ it still preserves my child dataset on the receive system assuming you are sending recursively a layer above and not specifically going from one dataset to another.
Worth noting Im doing this with a specific replication user and not root/admin using PULL rep. Other variations may vary.