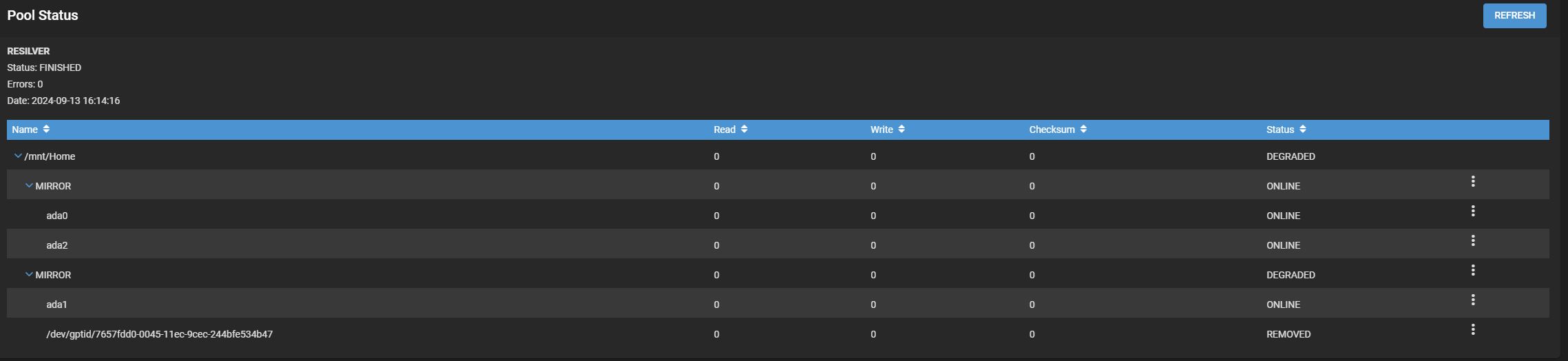
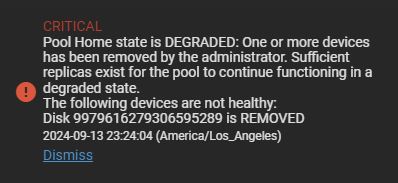
I’m kind of a noobie when it comes to TrueNas, and I need some help understanding how to fix my degraded home NAS. My PC is in the basement, and we had a big water leak down there. Fortunately, only one of the drives failed, and I was able to keep the rest of my data.
I recently replaced that drive with a new 4tb HDD and the old broken disk in the pool status. However, it seems that after resilvering (which took about a day), my NAS is still in degraded mode. Also, there is a disk not in the pool status for mirrors. If someone could explain what steps I should take to fix this problem, that would be really helpful. I also was wondering why I have 2 mirrors in the pool status.
[EDIT: I also tried replacing the /dev/gptid/7657fdd0-0045-11ec-9cec-244bfe534b47 with my ada3, but I get this error: Disk is not clean, partitions were found. I’m confused about whether it is safe for me to wipe this disk and add it back to the pool, and I’m also confused about why it is not a part of the pool in the first place if it has partitions.]
So it looks like ada3 is the drive that has failed so you would most likely need to replace that drive with another. Could you run smartctl -a /dev/ada3 and share the output?
Warning: the supported mechanisms for making configuration changes
are the TrueNAS WebUI and API exclusively. ALL OTHERS ARE
NOT SUPPORTED AND WILL RESULT IN UNDEFINED BEHAVIOR AND MAY
RESULT IN SYSTEM FAILURE.
root@truenas[~]# smartctl -a /dev/ada3
smartctl 7.2 2021-09-14 r5236 [FreeBSD 13.1-RELEASE-p9 amd64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate BarraCuda 3.5 (SMR)
Device Model: ST4000DM004-2CV104
Serial Number: ZTT1L3W3
LU WWN Device Id: 5 000c50 0db460fb3
Firmware Version: 0001
User Capacity: 4,000,787,030,016 bytes [4.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5425 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Sun Sep 15 21:20:08 2024 PDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x00) Offline data collection activity
was never started.
Auto Offline Data Collection: Disabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: ( 0) seconds.
Offline data collection
capabilities: (0x73) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
No Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 1) minutes.
Extended self-test routine
recommended polling time: ( 490) minutes.
Conveyance self-test routine
recommended polling time: ( 2) minutes.
SCT capabilities: (0x30a5) SCT Status supported.
SCT Data Table supported.
If you have any other drives in the pool which are SMR drives, you need to replace them with CMR drives.
SMR drives do not work properly with ZFS and if you need to resilver a pool with SMR drives, the chances are high that the resilver will never finish. Your data is at great risk if you use SMR drives!
Furthermore, the Barracuda is a desktop drive and is not suitable for a NAS server. If you don’t have full backups of the data in your pool, then you are likely to lose everything.
These may be non-ZFS partitions. If you are confident that the drive holds no valuable data you may wipe it. BUT…
This is not good for ZFS with any kind of pool, and you have iocage in there, so potentially lots of small writes. Replace all SMR drives by CMR as soon as possible.
I think only that drive is a SMR drive. I bought another Iron Wolf Pro NAS drive (4 TB), so I will pop that in the machine. If I remove that barracuda (ada3) will my pool of data disappear, or is it not even relying on ada3 right now for my ZFS pool.
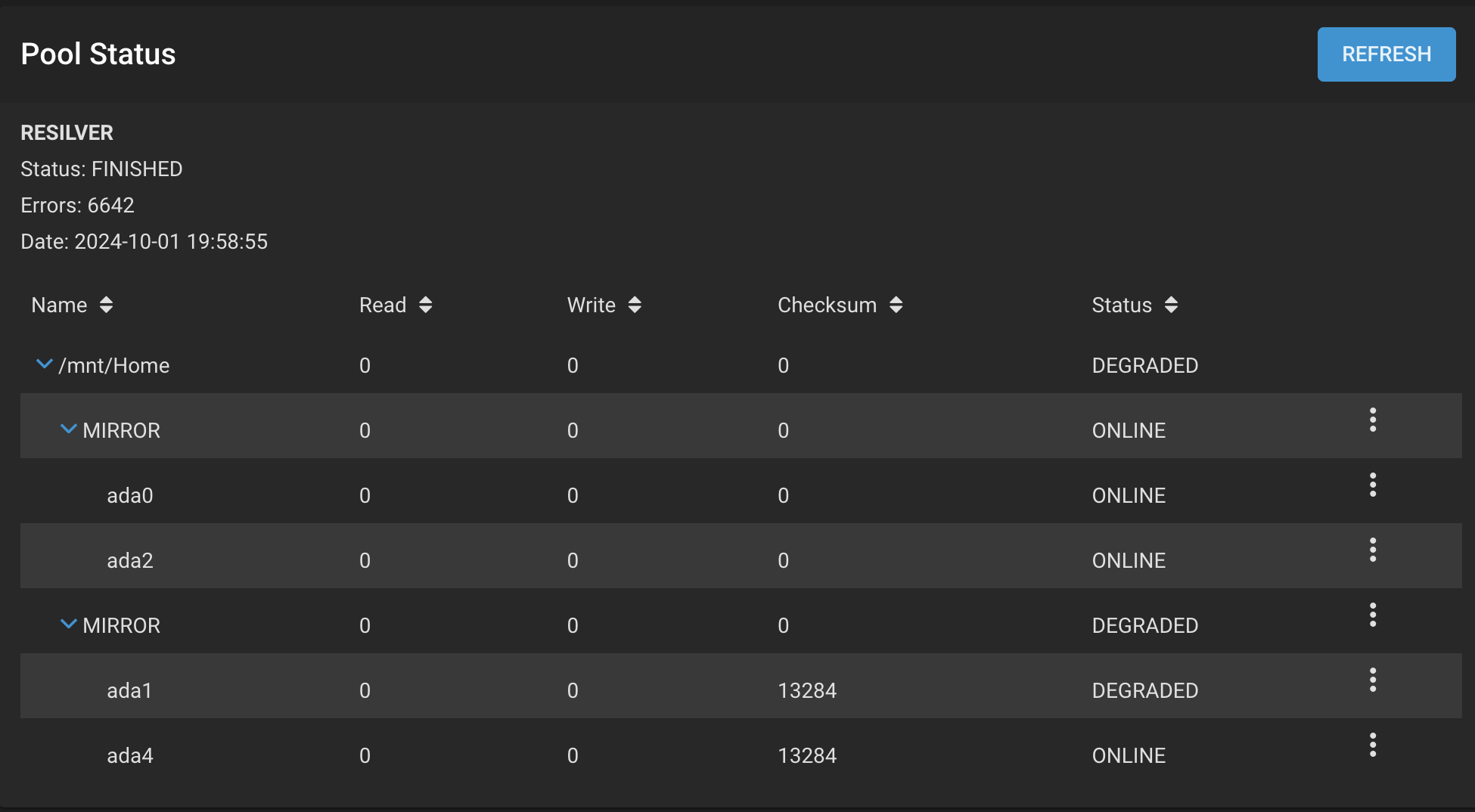
Hey. I installed that new drive into my system, so now i have 5 drives in there. However, after resilvering i got the same error. I really don’t know what I’m doing wrong. What else should i do to fix this:
It’s not uncommon for drives purchased around the same time to fail at approx the same time. Also that rebuild would have put extra strain on that drive. Assuming all your cabling is sound then you probably just want to replace the other drive now. Can you share the output of zpool status -v
are the TrueNAS WebUI and API exclusively. ALL OTHERS ARE
NOT SUPPORTED AND WILL RESULT IN UNDEFINED BEHAVIOR AND MAY
RESULT IN SYSTEM FAILURE.
root@truenas[~]# zpool status -v
pool: Home
state: DEGRADED
status: One or more devices has experienced an error resulting in data
corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the
entire pool from backup.
see: Message ID: ZFS-8000-8A — OpenZFS documentation
scan: resilvered 625G in 03:24:32 with 6642 errors on Tue Oct 1 23:23:27 2024
config:
NAME STATE READ WRITE CKSUM
Home DEGRADED 0 0 0
mirror-0 ONLINE 0 0 0
gptid/4b677cd7-bb43-11ea-8fca-244bfe534b47 ONLINE 0 0 0
gptid/4b7629ed-bb43-11ea-8fca-244bfe534b47 ONLINE 0 0 0
mirror-1 DEGRADED 0 0 0
gptid/bf709f3a-720c-11ef-993c-244bfe534b47 DEGRADED 0 0 13.0K too many errors
gptid/41ef3029-806a-11ef-88d9-244bfe534b47 ONLINE 0 0 13.0K
errors: Permanent errors have been detected in the following files:
<metadata>:<0x0>
pool: boot-pool
state: ONLINE
scan: scrub repaired 0B in 00:00:01 with 0 errors on Wed Oct 2 03:45:01 2024
config:
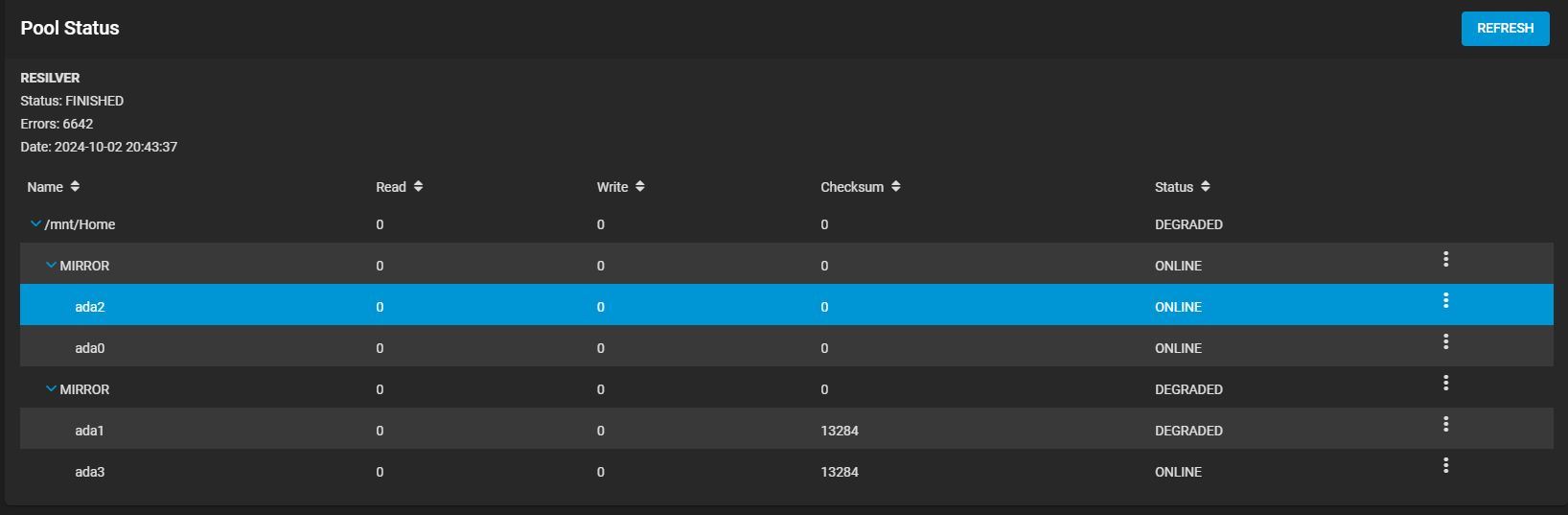
No, I removed the SMR drive. I have basically all new drives in there now. However, when it goes to resilver it always seems to fail I have no idea why.
root@truenas[~]# smartctl -a /dev/ada1
smartctl 7.2 2021-09-14 r5236 [FreeBSD 13.1-RELEASE-p9 amd64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate IronWolf
Device Model: ST4000VN008-2DR166
Serial Number: ZGY75HQW
LU WWN Device Id: 5 000c50 0c5cc743f
Firmware Version: SC60
User Capacity: 4,000,787,030,016 bytes [4.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5980 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Thu Oct 3 12:33:08 2024 PDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x82) Offline data collection activity
was completed without error.
Auto Offline Data Collection: Enabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: ( 581) seconds.
Offline data collection
capabilities: (0x7b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 1) minutes.
Extended self-test routine
recommended polling time: ( 600) minutes.
Conveyance self-test routine
recommended polling time: ( 2) minutes.
SCT capabilities: (0x50bd) SCT Status supported.
SCT Error Recovery Control supported.
SCT Feature Control supported.
SCT Data Table supported.