Good evening community. I have finally decided to post as I am ready to make one one of my Truenas Core systems healthy. I will admit that I am a little nervous as I am not comfortable with ZFS and replacing failed drives but I am going to start by framing the situation and hopefully this request for support and suggestions will also be a guide for other newbies.
I will start by disclosing that I have a NAS4Free system that I have to replace a failed drive which has been on the sidelines and I will work on it later but some of the data in there “should” be in the missing pool on this box. I also have a healthy TrueNAS system that is healthy but has nothing related to my main systems.
The Pool that is missing is missing in POOL-2 which is part 2 of this saga.
POOL-1 is the pool that has a sick disk. I suspect that there is only 1 disk that is truly failing but I I am now getting errors on both disk. The disk are 1 TB drives.
The drives are on the lower rack. I have an internal lower rack that has 6 drives in the bat 2x3 and I have a rack of 4 drives on the top bay with lockable doors . I have some spare drive in the top bay but I don’t want to use any of them in POOL-1. This pool is available had healthy but hda7 has been complaining about bad sectors for a while and hda8 is starting to complain a little bit also.
I have mapped all of the connections to the Asus z77 mb with an intel Core i7 3770 cpu @ 3.40 GHz. I have 16 Meg on the MB. I have a matching pair or Ram but the MB did not recognize all 4 sticks with I may use for a matching system in a shorter tower later.
Tomorry I should receive my PCIE or my PCI controller ( I ordered both ) and 2 1TB m.2 Sata stick to migrate POOL-1 to so that I can remove the 1TB drives from the machine. One disk is a WD and the other is a Toshiba.
The plan tomorrow is to install and configure the two drives and add them to POOL-1.
First of all: a complete (like which Z77 MB, which disks and other hw) and more…systematic description of the system would be great. I found this post quite hard to read tbh.
Also: please attach the output of zpool status in your next post and format it as a code block using the </> button.
The output of smartctl -x for all the disks in the unhealthy system would also be great - but probably rather as attached files, if you already have the permission to do so on these forums.
Just to be sure: you are actually still running NAS4Free? Like pre-2018 XIgmaNAS? In that case people here may still be able to help but this wouldn’t really be the right forum for it.
What kind of controller? an HBA? You ordered a PCIe and PCI variant?
I don’t even know if there are PCI HBAs
SATA M.2 SSDs are relatively rare and I don’t see how/why you would want to use them in a system that most probably has no SATA-M.2 ports.
Why would you buy an M.2 for m factor SSD and then not go for NVMe if you have PCIe lanes available?
I honestly think your post creates much more questions than it gives answers.
I’m not certain what you mean here but if your goal was to say that drive sda is connected to the SATA1 port of the motherboard, that will not work. TrueNAS and Linux names them as they become available. This means that sda could be the drive on SATA4 the next time you reboot. Always track the drives by the serial number, that is the only sure way to do things.
I have to agree with @TheColin21 that your posting was very difficult to read and it is all over the place. In my links below is something called Joes Rules. Please read this. It is basic guidance on how to communicate with the folks here, what data you should provide at a minimum, and to never allow us to make assumptions. It is a quick read, please read it as we all will benefit and your problems should be solved faster.
For the problem system, please do not install the PCIe controller for the M.2 cards. This will just add a little bit of confusion into the problem.
As @TheColin21 requested, the output of zpool status is very important for the single system we are troubleshooting. If you have another system that needs fixing, do that later, only work on one system in this thread.
And NAS4Free (formerly called FreeNAS), I remember the last version of it I ran was 0.7. It worked fine, and then iXsystems (now called TrueNAS) somehow swooped in and took over FreeNAS and called it version 8.0. I’ve been here ever since.
Firstly , Let me apologize if I sounded a little scattered. I had been working since 2:30 am and it was a long exhasting day. The one nas box that is running qietly is an old Xigmanas box and the one that has a bad drive that I have to repair is also a Xigmanas box.is a box that I built for a friend years ago for his office. I replace it with a Truenas scale box and he has a second custom in his other office running Scale. The old system (called The Beast ) will be upgraded and repurposed but is staying on the same version of Xigmanas for now until I have the time to work on it which will be after I fixed the issues that I am working through on this box.
Zpool status output
root@freenas[~]# zpool status
pool: NEWNASPOOL1
state: ONLINE
scan: scrub repaired 0B in 01:52:15 with 0 errors on Sun Aug 31 01:52:15 2025
config:
NAME STATE READ WRITE CKSUM
NEWNASPOOL1 ONLINE 0 0 0
ada2 ONLINE 0 0 0
ada3 ONLINE 0 0 0
errors: No known data errors
pool: POOL-1
state: ONLINE
scan: scrub repaired 0B in 00:29:16 with 0 errors on Sun Aug 31 00:29:16 2025
config:
NAME STATE READ WRITE CKSUM
POOL-1 ONLINE 0 0 0
gptid/29b7ab98-f0b0-11ea-9298-3085a99ba8ae ONLINE 0 0 0
gptid/b87ce3cb-61dc-11ee-8e75-3085a99ba8ae ONLINE 0 0 0
errors: No known data errors
pool: POOL-3
state: ONLINE
scan: scrub repaired 0B in 00:00:01 with 0 errors on Sun Aug 31 00:00:01 2025
config:
NAME STATE READ WRITE CKSUM
POOL-3 ONLINE 0 0 0
gptid/9a691e6a-7907-11eb-97b7-3085a99ba8ae ONLINE 0 0 0
errors: No known data errors
pool: boot-pool
state: ONLINE
scan: scrub repaired 0B in 00:00:22 with 0 errors on Tue Sep 23 03:45:22 2025
config:
NAME STATE READ WRITE CKSUM
boot-pool ONLINE 0 0 0
ada4p2 ONLINE 0 0 0
I have every disk mapped by the serial number and labeled and I know how with port they are plugged into the 4 port extender card is is color coded to the upper quick release bays…
The lower connectors are P0 - P9 on both ends of the cable and I have the mapping in an excel spread sheet.
I am working on a diagram for the bottom rack that only has 3 disk that will map to disk in the pools
I am not sure how it will show up on this platform but here is a sample (png) format.
You have built multiple NASes over the years and one of them has an unhealthy pool (POOL-2) now.
That system is built on an ASUS Sabertooth Z77 with an i7 3770 and 16GB RAM.
You also mention a 4 port extender card, probably the same one you mean with “Riser Card to 4 connections to the top bay 4xDrives” in PCIe 1 - it would be very important to know what card is in there.
If I interpret the colors in your SAMPLE correctly then the POOL-1 disks are currently connected to SATA P0/P1 of the mb and you want to use PCIe 2 for the NVMe adapter (probably won’t work, sorry) which will also limit PCIe 1 to x8.
SATA P2-P5 then probably belong together in some way and the boot disk is atttached to SATA E1 or E2.
You want to repair the broken POOL-2 but also migrate POOL-1 to two 1TB M.2 SSDs (you first said SATA but then sent a link to NVMe ones).
To mount the SSDs you ordered two PCIe (not PCI as stated above) to 2xM.2 adapters.
one that has one SATA only M.2 slot and one NVMe only M.2 slot (so you could only put one of the Crucial P3 Pluses in there) and one that splits
another one that works with two NVMe SSDs (like the Crucial P3 Plus) but requires PCIe bifurcation on the motherboard which as far as I could see in the manual is not supported by your motherboard (only one SSD will work).
Is that correct hardware-wise?
We still have no idea about the chassis, PSU or HDDs/SSDs in use (if I haven’t overlooked such information in the previous messages).
The system with the unhealthy POOL-2 and soon-to-be-migrated POOL-1 is running XigmaNAS although it’s hostname is “freenas” which is a system similar to TrueNAS CORE and SCALE but probably not what most forum users here will have any previous experience with. You might get lucky with @joeschmuck there but I personally have no idea about XigmaNAS (I started with FreeNAS 12 I think…).
According to your zpool status output POOL-2 is currently not even connected. Should this be the case, are the drives plugged in, is the pool exported…?
As @joeschmuck said: please don’t make further hardware changes before POOL-2 is restored.
Looking at the output I also cannot see the word “mirror” anywhere. POOL-3 is a single disk anyway but POOL-1 and NEWNASPOOL1 seem to be 2-wide stripes?
This is good, always use the drive serial number, never trust the Drive ID.
This is a great observation. There is no redundancy for if a drive fails. All data is pretty much lost when a single drive fails.
The NEWNASPOOL1 is also a two drive stripe. Only recommended if you don’t care about your data being lost. And I’m being serious, not making fun of someone who unfortunately created pools without any redundancy.
My current advice: Backup any data you can access and desire to retain. I hope I’m wrong but I don’t think you are going to like the final outcome.
First, let me thank you all for your patience with me and helping me to straighten out my naming of the various components.
When I get to the end of my day, I don’t have much energy left and I will be able to refine the sample document with exact naming and mapping to the exact disk.the “riser card” is color coded with red and disk since there are only 4 disk in the top bays and the Px/py designations are the port top port and port bottom dock designateion which is how I know what disk is plugged into what.
Tonight the second PCIe card came in and it has two of the connectors for the M.2 cards and the other one has connectors for on of each ( one has 1 sort notch and the the other has 2 notches ( left and righ) [M.2 MVE vs M.2 Sata]
I remove the card that had the MVE + Sata and laded the card that has the 2 MVE cards but it would only see 1 of the media. (8) I am note sure why I can only see one of the drives. but over the weekend I will be able to provide you all with detailed and correctly notaded components.
Thank you for you patience.
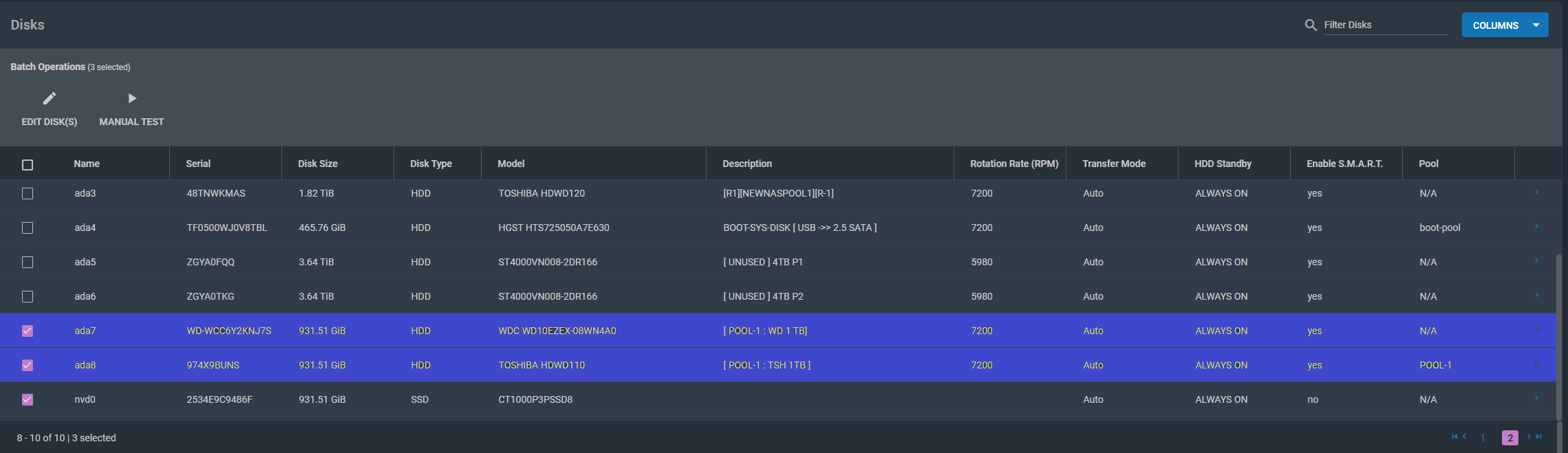
It looks like ADA7 has dropped out of the pool with ADA8. If I am only able to use the M.2 disk to replace 1 disk at a time, then that will be a learning experience for me.
Thanks for your patience as I learn how to navigate this community forum.
@gryphongfxSTOP
If it is not too late, do not replace the disks from POOL-1.
Read out previous answers and do so thoroughly.
I can very much understand that but you are dealing with a system with no redundancy whatsoever where one pool already failed. You probably already have lost one pool worth of data.
Thank you very meach for this information. I am learning something every day, especially when I am having a bout with insomnia today ( I will probably log in to work shortly and I am having my first cup of coffee while it is quiet)
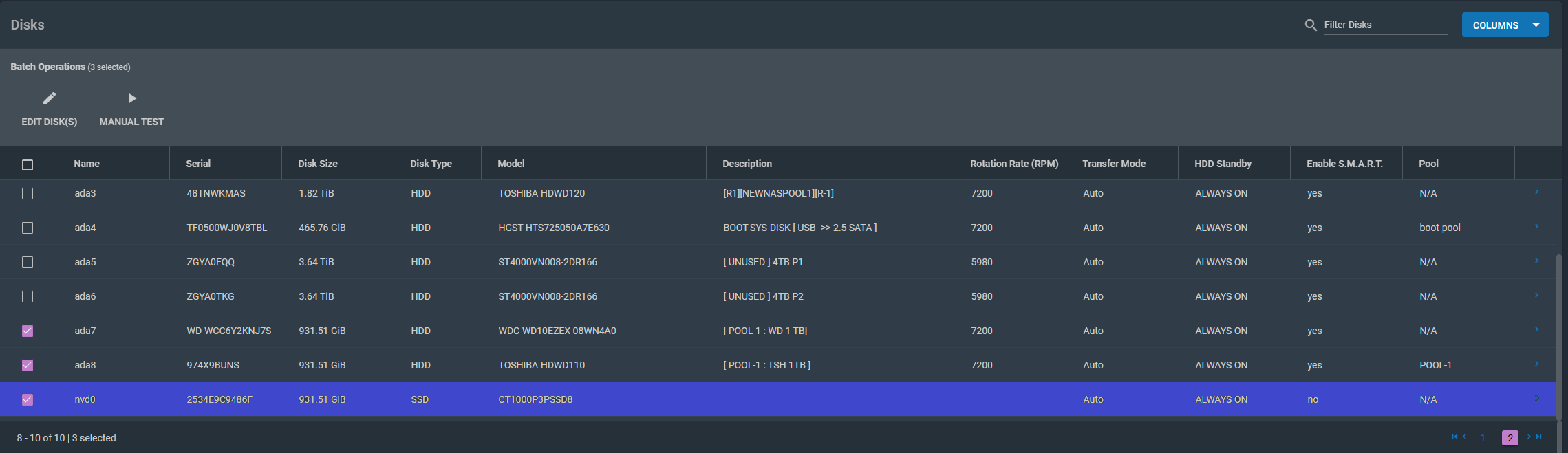
I am sure I know which interface is showing up as nvd0…
The first part of this project will be to heal POOL1 which contains the failing ada7. ada7 seems to be dropped from the pool and there are some bad sectors on ada8. The plan will be to add the nvd0 disk to POOL-1 and remove ada7 Re-balance POOL-1 and then replace ada8. (please see the uploaded png screen shots.) I will not be working on this project over the weekend but will be validating my worksheet and serial numbers to the devices. I do have some spare drives in the unit and and some drive drives on the shelf (2 and 10 TB) but I think I will pick up 2x 1tb drives to replace the POOL-1 disk.
Sorry I didn’t have the failing POOL-1 in mind anymore.
What is the current zpool status of it? As this was a stripe it should currently be completely faulted if one disk is missing.
POOL-1 is actually mirrored and not striped. it is on-line an healthy but I think I can explan that. Some time ago when one of the drives started getting sector errors , I thew a spare drive in the the pool with the intention of binding it to the failing disk so that I could reduce it out. I actually fogot about that because I went on vacation . and now I am trying to clean up the mess properly . what I will be considering it replacing the spingles is Flash media and making it 2x1TB mirrored drives. I will post the details later once I have made a mapping.
I will power off the system tonight as I have thinkg to do this weekend and will pick this project backup next week.
Hello everyone,
I know that it has been a couple of weeks since my last update but after my weekend off from my NAS problem, I had to focus on actual work so I had powered down this NAS (core) box and I decided to validate my workbook with the the serial number and WWNs so that I could have valid and confirmed data to continue with this request.
In the process of doing this I found 2 HDD that did not have good connections on the power connections, so I cataloged them and reseated the connections and my missing pool returned. I also pulled my 2 x 4TB drives (unused) and replaced them with 2 x 2TB SSD. ( will reuse them in another NAS system that I plan to rebuild and ) , I will remove one of the M.2 SSDs which I cannot see but the one that is connected to the SATA connection on the MB , I can see and use it to to replace a HDD.
I will clean up my spreadsheet and and post it this evening.
I am up (temporarily) battling Mr. Sleep Insomnia to get a couple of hours in before I have to start my workday but I wanted check in to update this thread.
New update is on the way!
Let me thank you all in advance with your assistance as I think through this situation.
After a heavy work week , I managed to get in some significant changes to this NAS box. first of all I went back and validated the serial and WWN to all of the disk plugged in and I found a couple of power cables that were not connected well and I was able to see disk ada10.
This shifted bad sector reporting and what was ada7 and ada8 is now ada8 and ada9 .
I also replace the 2x4TB drives with 2xTB SATA drive to replace the pool that was reporting the error on one of the drive. The drive that is ada9 only reported 1 block error but is not assigned to a pool so I am currently running S.M.A.R.T. diagnostics on the drive. [ badblocks -wvs /dev/ada9 ].
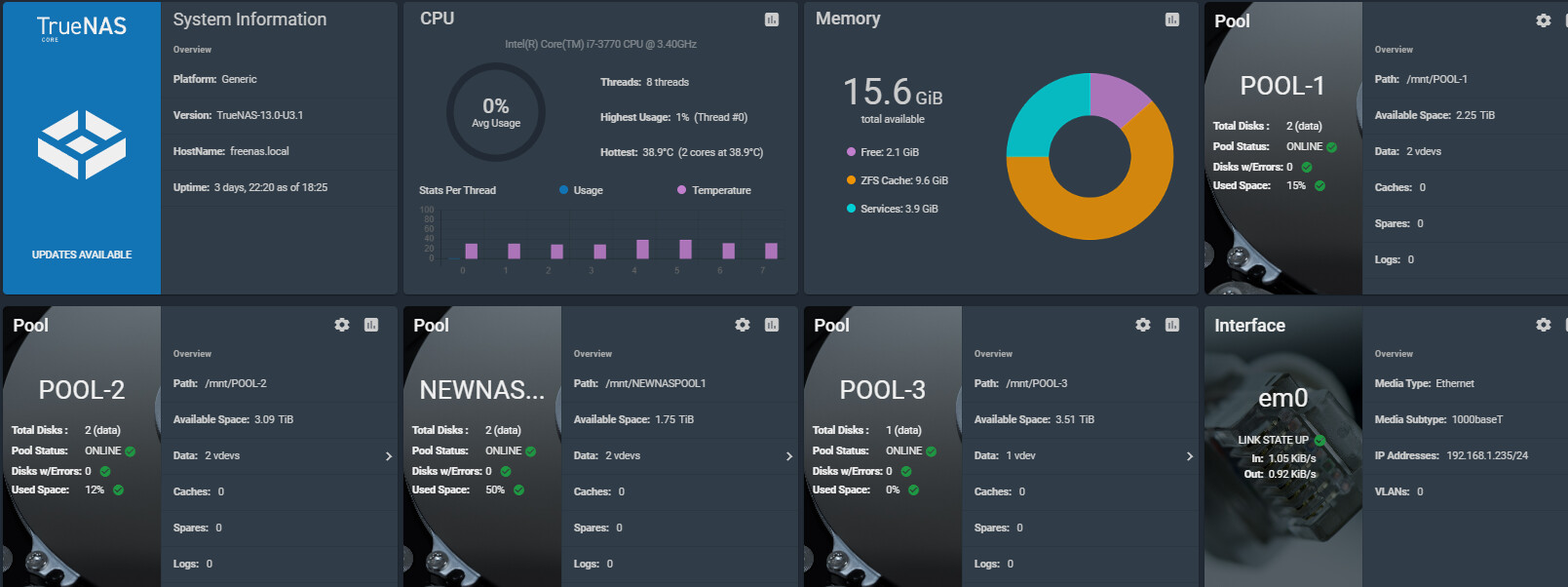
I cleared my alerts so that I will be able to quickly see any new critical alert. My missing pool recovered and in is healthy
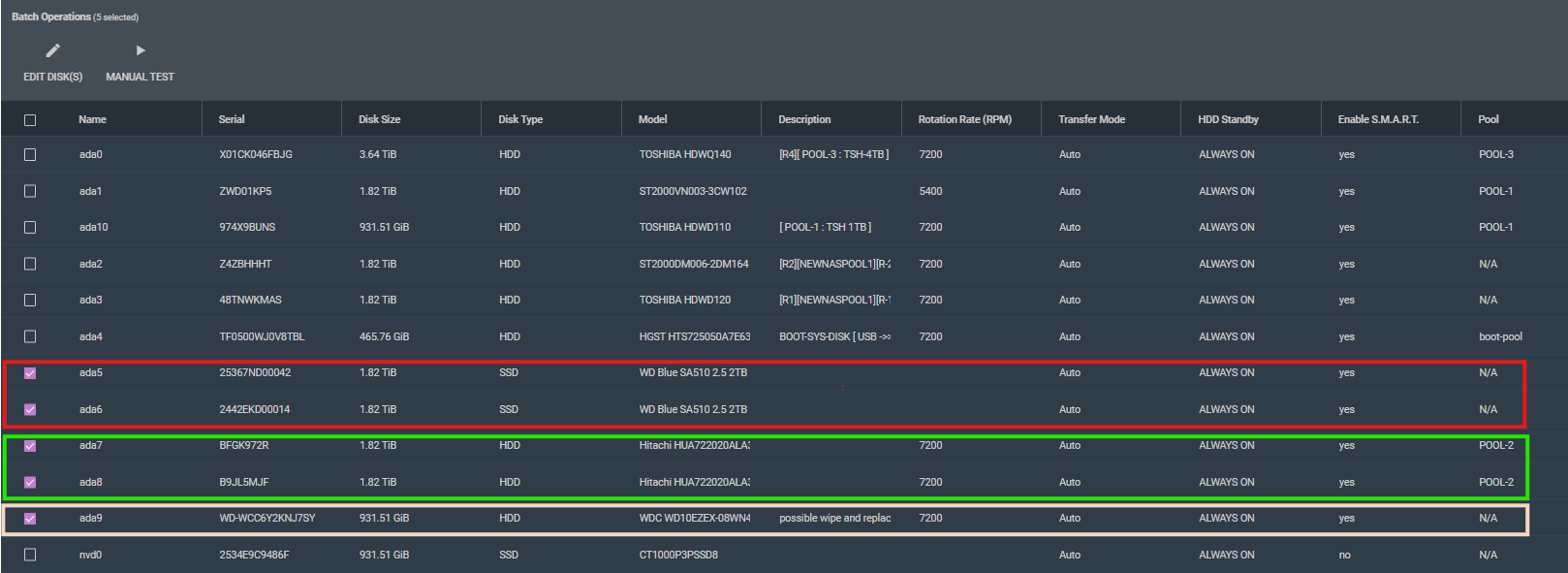
I am going to replace disk in POOL-2 with the two SSDs that I added to replace the 2x4TB disk but I am to make 2 Vdevs and mirror the drives in the pool.
Below is the Dashboard of the system showing the status of the system.
The drive in red are to replace the drives in green and the last drive is have the badblocks -wvs /dev/ada9 run to test it for potential reuse or spare.
It is the end of a long week. I am doing some cleanup. Drive ada9 has been leveled as not used in POOL2, but I was getting some block errors hanging out, so I cleared the alerts, rebooted a couple of times to see if the alerts were increasing or if it was a repeat of the previous errors.
I ran some SMART MON test on the drive, and I have wiped the drive twice and let the drive sit as a potential spare.
I am now looking to figure out how to integrate the two SSD drives into POOL2, and I know that I want them to be vdev this time around. The two disks that make up POOL2 are not separate vdevs.
Note: once I have moved POOL2 to the SSDs with the vdev structure, I will upgrade from Core to SCALE or Community.