Hello!
I’m seeing this in my syslog:
Aug 26 10:01:05 vectorsigma kernel: TCP: bond0: Driver has suspect GRO implementation, TCP performance may be compromised.
From the research I’ve done, I found this page: Driver has suspect GRO implementation, TCP performance may be compromised – JoeLi's TechLife
If calculated MSS (Maximum Segment Value) is higher than Advertised MSS, then set the new MSS to ‘Advertised MSS’. In earlier kernels, this was not [done] and could have caused performance issues while GRO (Receive Offload) was used. It’s based on these MSS values, TCP window size is determined for data transfer.
RHEL 7.4 introduced a fix for this into its kernel back in 2019, apparently, “and stated this message can be treated as informational only and as a warning one which can be safely ignored.”
However, I’m not sure if that holds true for TrueNAS SCALE.
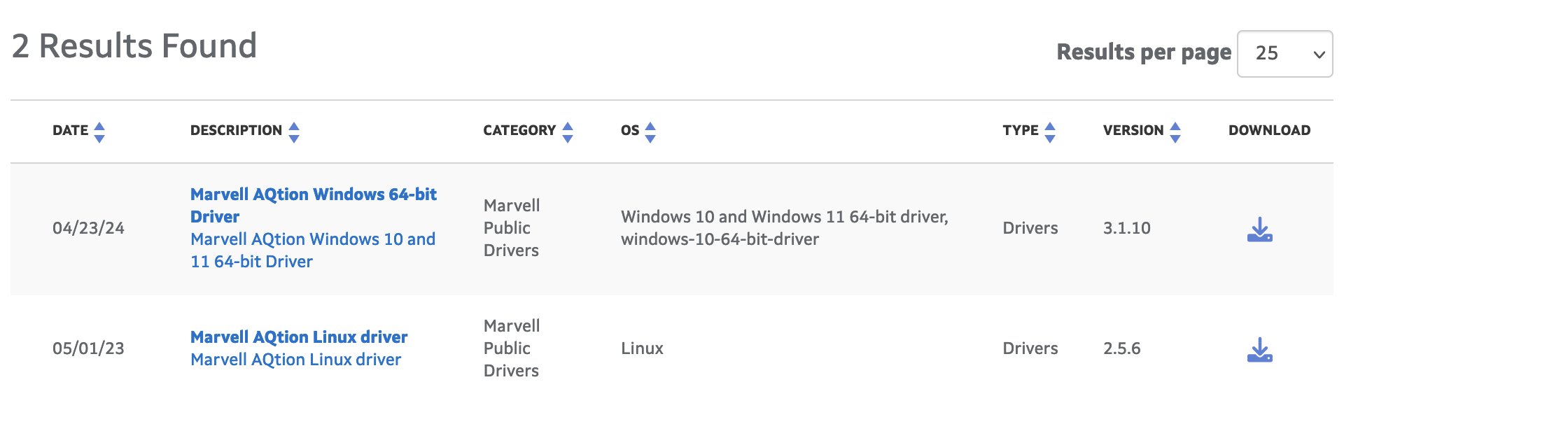
Here’s some additional diagnostic information. Do I need to do anything to address this, or is it a harmless warning?
OS Version:TrueNAS-SCALE-24.04.2
Product:DXP8800 Plus
Model:12th Gen Intel(R) Core(TM) i5-1235U
Memory:31 GiB
admin@vectorsigma[~]$ uname -a
Linux vectorsigma 6.6.32-production+truenas #1 SMP PREEMPT_DYNAMIC Mon Jul 8 16:11:58 UTC 2024 x86_64 GNU/Linux
admin@vectorsigma[~]$ sudo lspci | grep -i ethernet
58:00.0 Ethernet controller: Aquantia Corp. Device 04c0 (rev 03)
59:00.0 Ethernet controller: Aquantia Corp. Device 04c0 (rev 03)
admin@vectorsigma[~]$ sudo lspci -vvvv -n -s 58:00 | grep -i kernel
Kernel driver in use: atlantic
Kernel modules: atlantic
admin@vectorsigma[~]$ ip addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: enp88s0: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 9000 qdisc mq master bond0 state UP group default qlen 1000
link/ether 6c:1f:f7:0c:ce:be brd ff:ff:ff:ff:ff:ff
3: enp89s0: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 9000 qdisc mq master bond0 state UP group default qlen 1000
link/ether 6c:1f:f7:0c:ce:be brd ff:ff:ff:ff:ff:ff permaddr 6c:1f:f7:0c:ce:bd
4: bond0: <BROADCAST,MULTICAST,MASTER,UP,LOWER_UP> mtu 9000 qdisc noqueue state UP group default qlen 1000
link/ether 6c:1f:f7:0c:ce:be brd ff:ff:ff:ff:ff:ff
inet 10.10.10.40/24 brd 10.10.10.255 scope global bond0
valid_lft forever preferred_lft forever
5: vlan200@bond0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9000 qdisc noqueue state UP group default qlen 1000
link/ether 6c:1f:f7:0c:ce:be brd ff:ff:ff:ff:ff:ff
inet 10.10.200.2/24 brd 10.10.200.255 scope global vlan200
valid_lft forever preferred_lft forever