My current system:
Hardware: Dell PowerEdge T20 - E3-1225 v3 3.2GHz; 12GB ECC RAM
Software: TrueNAS-13.0-U6.2
Issue: My TrueNAS server shows an unscheduled reboot every 65 min.
The reboots are 65 min +/- 2 sec or so.
I first noticed the issue mid last week. At the time, my server was running version 13.0-U6.1. I tried installing the update thinking it might fix the problem, but no change.
I approached it as though it were a hardware problem. I have swapped out the power supply (no change). I have booted into BIOS, running a diagnostics test. The test does not find any issues.
Just for some background, the original install for the server was FreeNAS version 9.10 back in 2017. I have migrated to version 11, then 12, and now 13. The system has been pretty rock-solid until this recent issue.
I only have 2 services enable (SSH and SMB). I have 1 plugin installed (Nextcloud). I have tried stopping the Nextcloud jail, but no change in behavior.
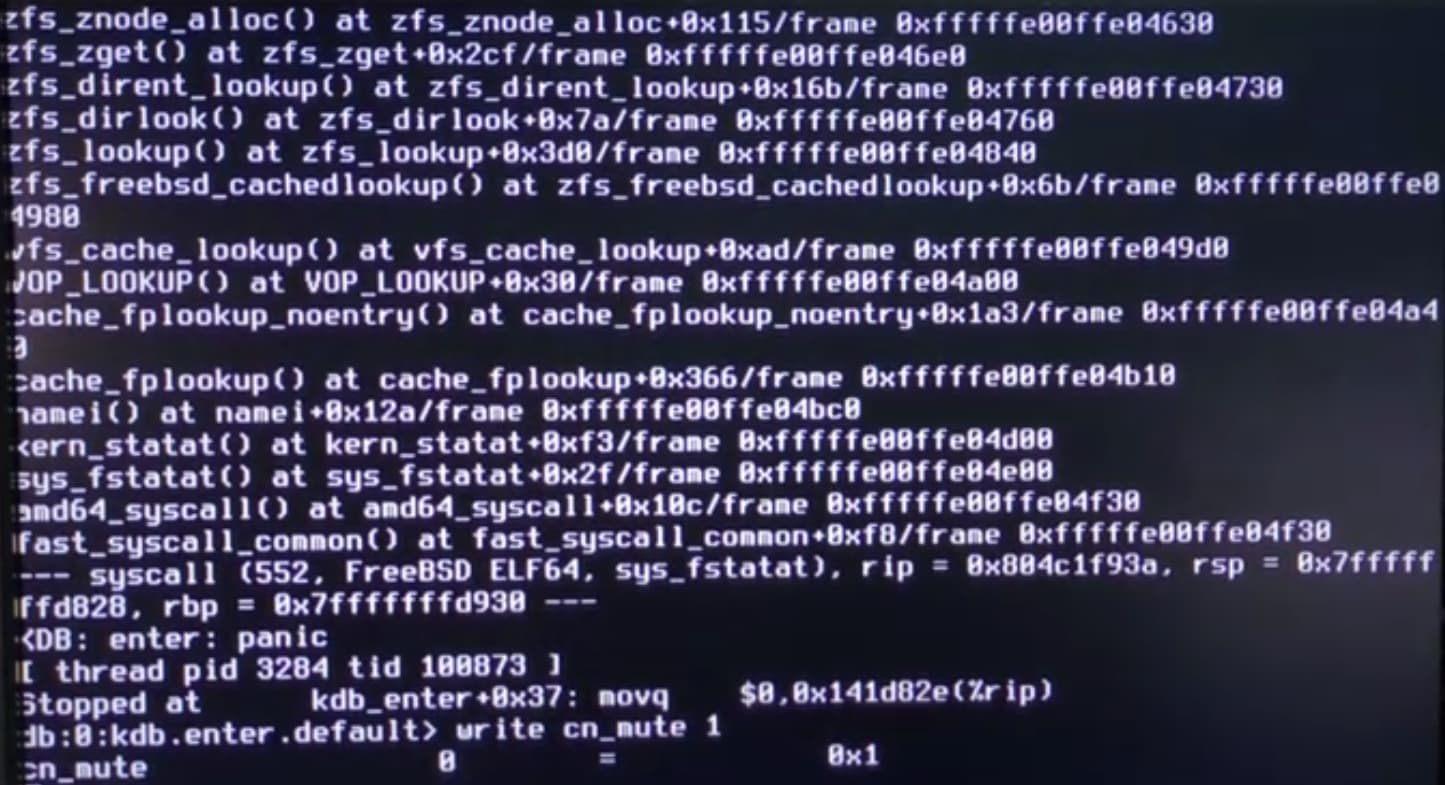
I grabbed a screenshot of the local display on one of the reboots - not sure if this info may be helpful.
The pool is obviously offline. The server has been stable, though and hasn’t rebooted.
Any ideas on narrowing down to determine which drive(s) may be the causing the issue, or if there is some other issue related to the pool?
I can see that there a ZFS update available. I have thought about trying to upgrade the pool, but don’t have much confidence that it will actually solve the problem.
I decided to try unplugging 1 of the 5TB drives at a time and booting the system.
I went through all 4 drives one at a time.
In each case, the system booted and showed the pool as degraded, but still working (all samba shares accessible, etc.)
In each case, the system still rebooted after 65 min.
So - still the same issue, and not able to narrow the problem down to a single drive.
I tried running a manual scrub, but the scrub can’t complete in 65 min. I tried pausing the scrub before the system rebooted, but it does not save the scrub progress. It starts a new scrub after every reboot.
If any set of four drives is fine but the whole five fails it could be an issue with power supply—though it’s hard to conceive why the PSU would wait exactly 65 minutes to show its discontent.
Given that you have eliminated the PSU, the HDDs from the equation, the only thing left is the CPU / motherboard? I presume you have been watching the CPU / motherboard temps and they are fine? Was the system cooler over the three days that it did operate w/o rebooting? T
o me, this looks like a “thermal” issue, at the same time I see nothing wrong with trying out a 13.3 upgrade and see what happens. Your pool data should be safe as long as you have a backup of the config file.
I have completed enough testing that I’m fairly positive it is a problem specific to the 4x 5TB pool and/or one of the drives in the pool.
I have done both of the following to help confirm:
I have disconnected the 4x 5TB drives in the pool and rebooted the server. When I do this, the pool is obviously offline, but the server is then stable and does not reboot.
I have boot the served to a ‘live’ Linux distro on USB drive. Again, the server is stable and does not reboot.
CPU temps all look good (avg temps 26C, hottest core 29C). No difference noted during the 3 days of uptime.
I would be glad to grab/share debug file(s) info. I’m not sure what all files I need to provide. If you can tell me what files/info are valuable, I will capture and share.