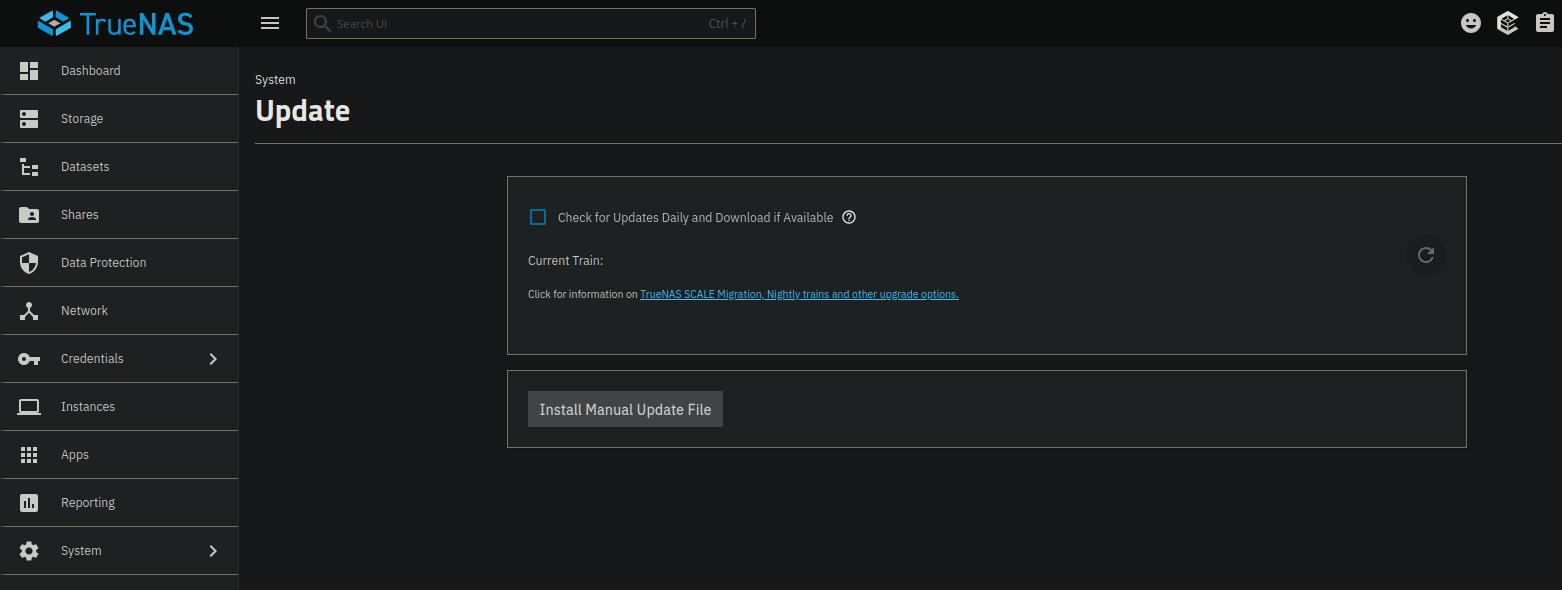
Well, now, this is weird… when I go to my home screen, it shows this:
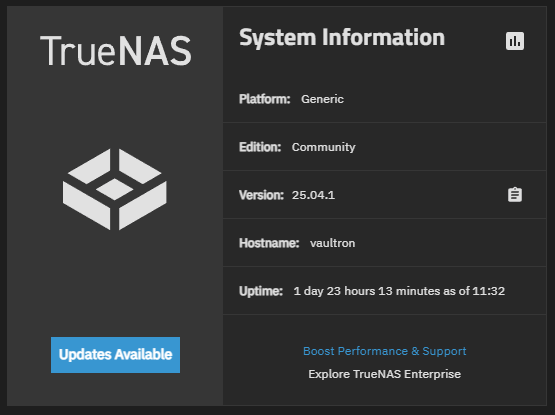
Wait, I’m on the current version already. But, when I go to the Updates Available…
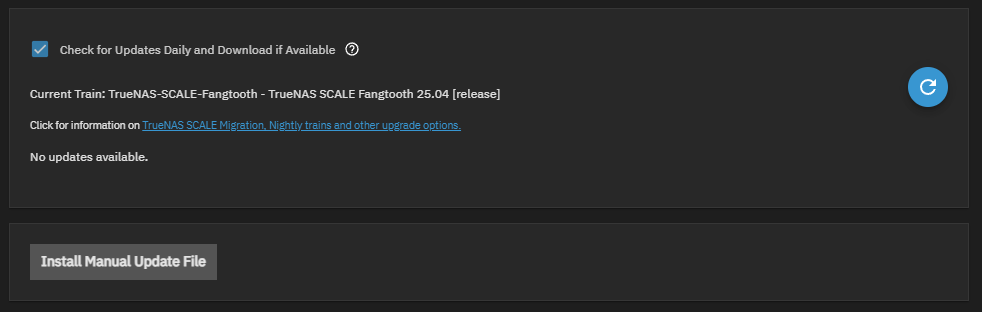
Anyone else?
Well, now, this is weird… when I go to my home screen, it shows this:
Wait, I’m on the current version already. But, when I go to the Updates Available…
Anyone else?
It’s a bug mentioned in the release notes, there’s also a fix mentioned there
It must have been added after I performed my update yesterday. But, removing the file worked!
You broke the loop. You’re safe… for now.
Would NginX+AdGuard Home be an example? What I want to do is move my NginX proxy from the shared IP address of 192.168.1.2 to it’s own dedicated IP address within the static range of 192.168.1.1-49 (probably 192.168.1.49 ![]() ) and use standard ports of 80 and 443. Once I have reconfigured and verified the port forwarding at the router level, I want to set up DNS rewrites on my Adguard Home DNS instance for my hosted apps to point to the NginX instance so that, in case I lose access to my Internet, I can still access those apps via FQDN on my network.
) and use standard ports of 80 and 443. Once I have reconfigured and verified the port forwarding at the router level, I want to set up DNS rewrites on my Adguard Home DNS instance for my hosted apps to point to the NginX instance so that, in case I lose access to my Internet, I can still access those apps via FQDN on my network.
The nice part of my setup… anything with a DHCP-assigned (50-254) address goes through my AdGuard DNS server, while those with a static address goes though unfiltered DNS servers.
Shouldn’t the logic be that the app’s running/stopped state post-update is the same as pre-update?
As was mentioned, TrueNAS doesn’t know why an app is stopped, but why should it care? It shouldn’t be trying to start the app in the first place. The user only asked to update, not update and start.
Another example of where TrueNAS tries to automatically start apps that have been manually stopped is when automatic migration happens as you install 24.10. It migrates and then proceeds to start every app, even though some used to be stopped.
To me it seems that the logic fails due to the insistence to start the app post-update no matter what the previous state was and this security issue can be solved by stopping that behaviour.
The only issue I had — it still showing “Update Available” — was resolved with the command in the release notes. Thanks!
Agreed… that was not ideal. However, there were two reasons for that:
That migration was very complex and we did not want to make it more complex. It was code that was going to get used once only.
Making a big upgrade decision should require more thought than a simple software update. Users had time to prepare and remove Apps if needed.
I suspect there are the same reasons that prevent you from just updating (images of) the services in docker compose without starting them.
Out of interest, should there by a current train identified? I had to do a manual update to get to 25.04.1, and I observed this issue on 25.04.0 (I went Beta>RC1>.0)
One maybe interest bit of errata for 25.04.1 is that who output now shows authenticated UI / API sessions.
root@test9IV3SORLEN[~/middleware/src/middlewared]# who
root pts/0 2025-04-18 05:47 (10.150.16.251)
root pts/1 2025-04-18 06:50 (10.150.16.251)
awalker ws/3 2025-04-18 12:43 (tn-mw.848020c3-1c17-4a14-bb13-27a3c2010d28.IP10.150.16.251)
awalker wss/4 2025-04-18 12:45 (tn-mw.958781e9-3b85-40ed-9a56-863f8a04a6e8.IP10.150.16.251)
root wsu/5 2025-04-18 12:46 (tn-mw.43619e10-6c96-4c8f-bd7e-d565ed0205d6.PID32983)
In this case ws == insecure. wss == websocket secure. wsu means unix socket connection. 958781e9-3b85-40ed-9a56-863f8a04a6e8 above is the middleware session ID.
There is a train identified in the standard deployment.
This looks like an artifact of you having gone through BETA/RC.1. The manual update doesn’t seem to fix, if no-one else knows how to fix, you can report this as a bug.
Edit: There is a process to fix… roll back to previous version. Then update to a formal release version.
Upgraded from 24.10 today, wasn’t entirely smooth. Fairly vanilla install, no virtualisation, only NFS, SMB, iSCSI and some snapshot/replication stuff.
On first boot I got a bunch of kernel errors in the log:
[...]
Jun 1 12:40:48 xxx kernel: INFO: task dp_sync_taskq:1522 blocked for more than 120 seconds.
Jun 1 12:40:48 xxx kernel: Tainted: P OE 6.12.15-production+truenas #1
Jun 1 12:40:48 xxx kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
Jun 1 12:40:48 xxx kernel: task:dp_sync_taskq state:D stack:0 pid:1522 tgid:1522 ppid:2 flags:0x00004000
Jun 1 12:40:48 xxx kernel: Call Trace:
Jun 1 12:40:48 xxx kernel: <TASK>
Jun 1 12:40:48 xxx kernel: __schedule+0x461/0xa10
Jun 1 12:40:48 xxx kernel: schedule+0x27/0xd0
Jun 1 12:40:48 xxx kernel: cv_wait_common+0xef/0x130 [spl]
Jun 1 12:40:48 xxx kernel: ? __pfx_autoremove_wake_function+0x10/0x10
Jun 1 12:40:48 xxx kernel: dsl_scan_prefetch_thread+0xa6/0x2b0 [zfs]
Jun 1 12:40:48 xxx kernel: taskq_thread+0x253/0x4f0 [spl]
Jun 1 12:40:48 xxx kernel: ? __pfx_default_wake_function+0x10/0x10
Jun 1 12:40:48 xxx kernel: ? __pfx_sync_meta_dnode_task+0x10/0x10 [zfs]
Jun 1 12:40:48 xxx kernel: ? __pfx_taskq_thread+0x10/0x10 [spl]
Jun 1 12:40:48 xxx kernel: kthread+0xcf/0x100
Jun 1 12:40:48 xxx kernel: ? __pfx_kthread+0x10/0x10
Jun 1 12:40:48 xxx kernel: ret_from_fork+0x31/0x50
Jun 1 12:40:48 xxx kernel: ? __pfx_kthread+0x10/0x10
Jun 1 12:40:48 xxx kernel: ret_from_fork_asm+0x1a/0x30
Jun 1 12:40:48 xxx kernel: </TASK>
Jun 1 12:40:48 xxx kernel: INFO: task winbindd:6837 blocked for more than 120 seconds.
Jun 1 12:40:48 xxx kernel: Tainted: P OE 6.12.15-production+truenas #1
Jun 1 12:40:48 xxx kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
Jun 1 12:40:48 xxx kernel: task:winbindd state:D stack:0 pid:6837 tgid:6837 ppid:1 flags:0x00000006
Jun 1 12:40:48 xxx kernel: Call Trace:
Jun 1 12:40:48 xxx kernel: <TASK>
Jun 1 12:40:48 xxx kernel: __schedule+0x461/0xa10
Jun 1 12:40:48 xxx kernel: schedule+0x27/0xd0
Jun 1 12:40:48 xxx kernel: io_schedule+0x46/0x70
Jun 1 12:40:48 xxx kernel: folio_wait_bit_common+0x13e/0x340
Jun 1 12:40:48 xxx kernel: ? __pfx_wake_page_function+0x10/0x10
Jun 1 12:40:48 xxx kernel: folio_wait_writeback+0x2b/0x80
Jun 1 12:40:48 xxx kernel: truncate_inode_partial_folio+0x5e/0x1b0
Jun 1 12:40:48 xxx kernel: truncate_inode_pages_range+0x1e3/0x410
Jun 1 12:40:48 xxx kernel: truncate_pagecache+0x47/0x60
Jun 1 12:40:48 xxx kernel: zfs_freesp+0x215/0x2c0 [zfs]
Jun 1 12:40:48 xxx kernel: zfs_setattr+0xe10/0x2180 [zfs]
Jun 1 12:40:48 xxx kernel: ? _raw_spin_unlock+0xe/0x30
Jun 1 12:40:48 xxx kernel: zpl_setattr+0xfe/0x1d0 [zfs]
Jun 1 12:40:48 xxx kernel: notify_change+0x1f1/0x510
Jun 1 12:40:48 xxx kernel: ? __vfs_getxattr+0x7f/0xb0
Jun 1 12:40:48 xxx kernel: ? do_truncate+0x98/0xf0
Jun 1 12:40:48 xxx kernel: do_truncate+0x98/0xf0
Jun 1 12:40:48 xxx kernel: do_ftruncate+0xf5/0x150
Jun 1 12:40:48 xxx kernel: do_sys_ftruncate+0x3d/0x80
[...]
I let it settle down and rebooted, next time without apparent errors.
Later noticed that the SMB service wasn’t running and using
systemctl list-units --state=failed
could see that the winbindd service had failed. I restarted the SMB service in the GUI and it came up. Will have to see if the same thing happens again on next reboot or not. I don’t understand why TrueNAS didn’t alert me that there is a problem nor could I see anything in the logs.
Also have the same erroneous “Update Available” message stuck in the GUI as noted above. NB I did not come from a beta or RC. 24.10.2.2 → 25.04.01.
This system has been upgraded in steps from FreeNAS 9 and previous upgrades prior to this one have been smooth.
I think you’ll have better results if you install 24.10.2 brand new, not from an upgrade. Then just import your pools and redo your configuration.
It might sound tedious, but it lessens the likelihood of artifacts from such an old configuration.
Actually I should have been more precise. The config originates back then - however I have done “export config → clean install → re-import config” a few times, most recently when I moved to virtualise TrueNAS in a VM a few versions back.
It would be interesting to see if anyone else experiences a similar issue… was it within a VM or on baremetal?
Virtualised in a VM, Proxmox 8.4.1, q35 v9.0.
Electric Eel?
All updated without any of the concerns here. My system is uber simple though.
are there plans to auto fix this?
I don’t mind waiting for an automatic fix via update.
and would rather not have to manually repair this.