I’m on Scale 24.04.1 and it seems like my logs are being filled every few hours by the SMB audits, even with all shares disabled:
Jun 7 14:26:27 nas systemd-journald[1002]: /var/log/journal/0c00f0351aa14c7cb1f6180b6acf107b/system.journal: Journal header limits reached or header out-of-date, rotating.
Jun 7 17:09:48 nas systemd-journald[1002]: Data hash table of /var/log/journal/0c00f0351aa14c7cb1f6180b6acf107b/system.journal has a fill level at 75.0 (8535 of 11377 items, 6553600 file size, 767 bytes per hash table item), suggesting rotation.
Jun 7 17:09:48 nas systemd-journald[1002]: /var/log/journal/0c00f0351aa14c7cb1f6180b6acf107b/system.journal: Journal header limits reached or header out-of-date, rotating.
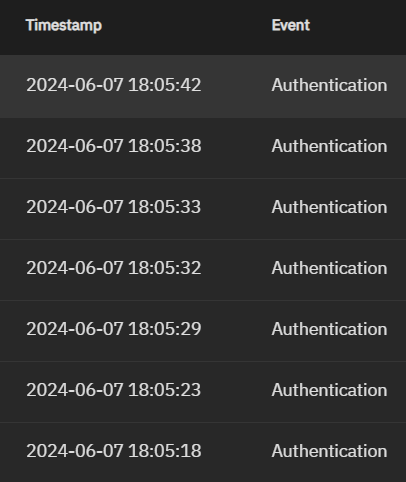
There is a new event every few seconds:
Log level on the SMB service is set to “none.” How do I stop all of these entries? I assume they are telling me when a client authenticates to the SMB service?
I figured out that this was being caused by Proxmox, and found a workaround for the constant reconnects on the Proxmox side. I would still like to know how to fix this on the TrueNAS side though.
It’s part of the auditing feature. We always log authentication events. Generally we are using syslog-ng to parse logs and insert into /var/log if you need something in particular you can look there. You are welcome to file a feature request for ability to disable auditing.
While tidiness of the audit page is a concern, the bigger worry is actually the amount of writing done to the boot pool. I thought perhaps the high rate of log turnover was being caused by this, which in turn was causing a higher than expected amount of write to the boot pool.
Even after reducing the audit traffic, it seems I’m still writing about 135KBps, which should be about 4TB per year.
I’m using 32GB Supermicro SATADOMs for my boot drives, which while not USB thumb drives, are also not more mainstream SSDs. They are rated for an endurance of 34TB. Under Core, they receive virtually no writes at all, so this behavior seems much different under scale.
I know they won’t necessarily die the moment they hit 34TB, but this amount of writing also doesn’t seem appropriate for these devices. It’s not the end of the world to replace them every few years if they die, and certainly I could buy cheap SSDs with an endurance over 300-600TBW, but I’ve purchased systems from IX that came with these exact drives. One of the systems I manage is a 4 drive 1u that uses these boot devices. There is no space for installing m.2 or 2.5" drives (if I want to keep using the 4x 3.5" bays for data drives), and the SATADOMs only have 500GB of writes on them after 6 years of use. At the level of writing I’m seeing on THIS system (that I just installed Scale on) it seems that other system should not be moved over to Scale just for this reason.
I guess in summary my question is this: Is this behavior normal, Scale is more chatty on the boot drives, and I should adjust my expectations/planning for boot devices? Or is this abnormal and worth looking into?
Can you share what was the issue and how did you work around it?
I seem to have similar symptoms, where my Proxmox is authenticating every couple of seconds to my TrueNAS when using “SMB/CIFS” storage from the Proxmox > Datacenter view. However, when I mount directly from Proxmox > Datacenter > node > shell then the connection works properly (one authentication log for the first connection and then it’s it).
What I want is for Proxmox to export it’s backup dump to TrueNAS over SMB, but if it keeps reconnecting (never noticed any connectivity issue, just the thousand log entries saying Authentication, which worries me). Any help would be welcome, thanks!
Yeah, after further Googling I found confirmation that this is the default Proxmox behaviour (to re-authenticate every 10 seconds to check the state of the attached SMB folder). My workaround was to mount SMB on the Proxmox host via console (not UI) in /etc/fstab. It keeps the connection open and doesn’t spam every 10 seconds.
Instead of connecting to SMB via Proxmox’s native Datacenter > Storage > SMB/CIFS, I have ssh-ed into the Proxmox host (or Datacenter > your-node > shell) and edited /etc/fstab to use cifs to connect to said SMB. Then I have added a new entry in Datacenter > Storage as Directory, pointing to the mounted directory on the host. Hope this helps.
Netdata log spam crashed my trueNAS scale. Im in the process of troubleshooting this. IT is indeed after I enabled snapshots and access logging for audting purposes. Id now like to disable this and clean up the logs so the middleware can start properly. Any suggestions from anyone?
I don’t see how logging can break booting unless your boot device actually failed or is otherwise inadequate for task of being an OS drive. The databases are stored in /audit and so in theory you can just delete them.