I’m a first time user of TrueNAS, using a device for the first time. From the get go the system has been randomly failing every few days or so, needing me to power it off and on again with the hardware power button. How can I figure out what the issue is?
I have:
- ASUSTOR Flashstore 12 Pro FS6712X (Intel Celeron N5105 CPU)
- 12 * Kingston NV2 4TB M.2 2280 NVMe Solid State Drive (SNV2S/4000G)
- 10 GbE
$ lspci | grep -i Ethernet 01:00.0 Ethernet controller: Aquantia Corp. Device 04c0 (rev 03) $ sudo dmesg | grep eth0 [ 1.808985] atlantic 0000:01:00.0 enp1s0: renamed from eth0 - 32GB RAM (CT2K16G4SFRA32A)
- Running TrueNAS Scale 24.04.2.3 (“Dragonfish”) on a Kingston NV2 1TB M.2 2280 NVMe Solid State Drive (SNV2S/1000G) in a UGREEN M.2 NVMe SSD Enclosure (USB 3.2 Gen 2 10Gbps)
Things I’ve looked at:
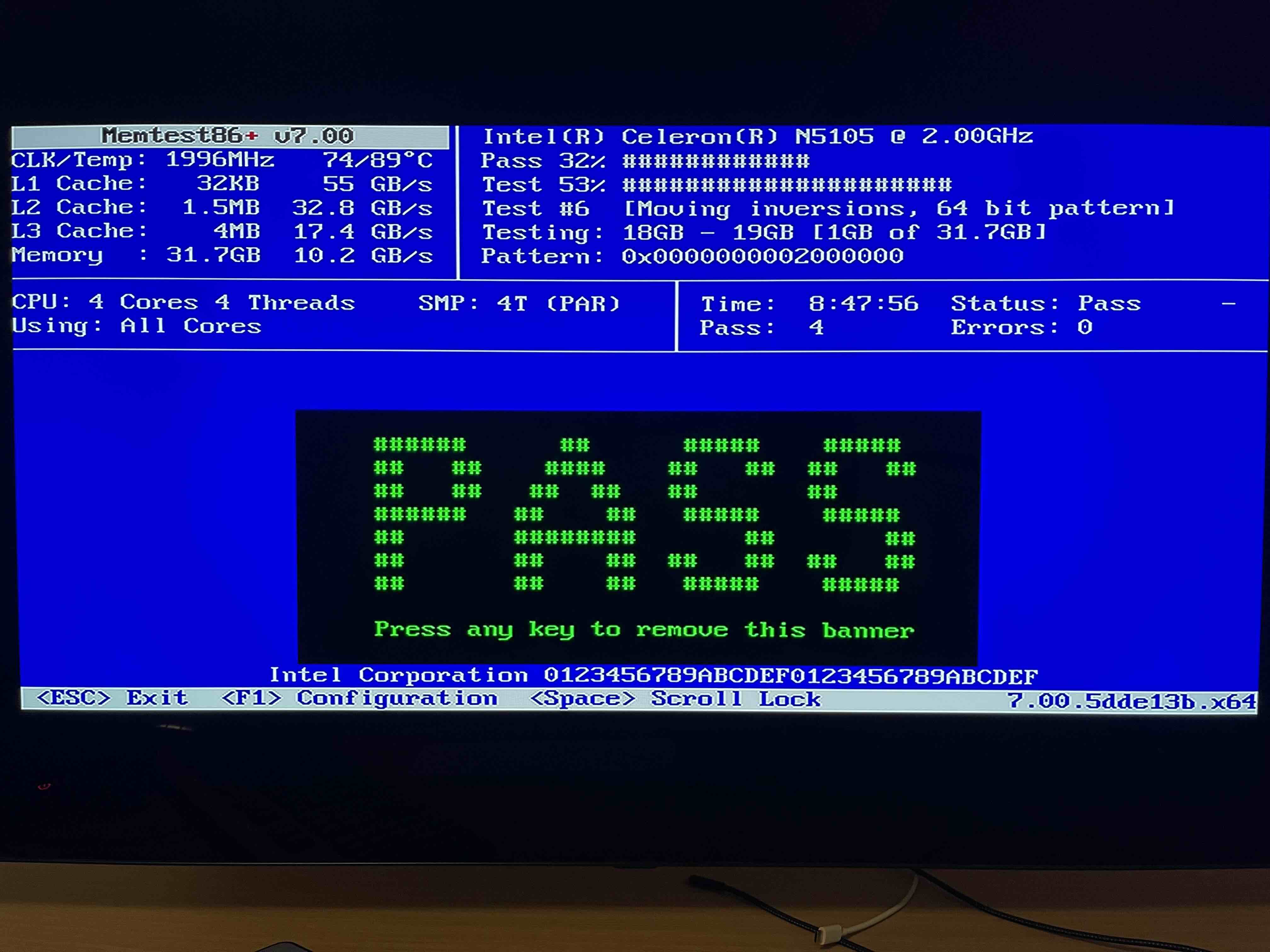
- It passes Memtest86+ fine (the high CPU temp is because the fan is on a default low setting the whole time during this):
- It passes
stress -c 4fine, with a fan control script running in TrueNAS:
- All my drive temps are always fine.
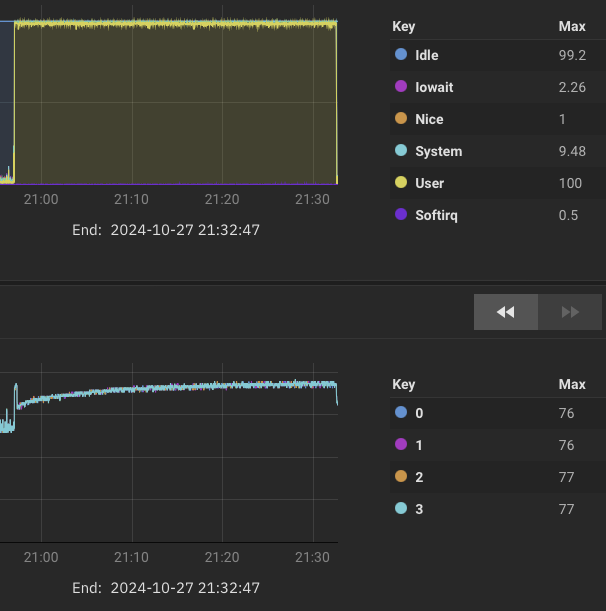
- Looking at CPU usage reporting in TrueNAS UI, I can see roughly when the system must have failed, and I’ve tried looking at the logs at those times:
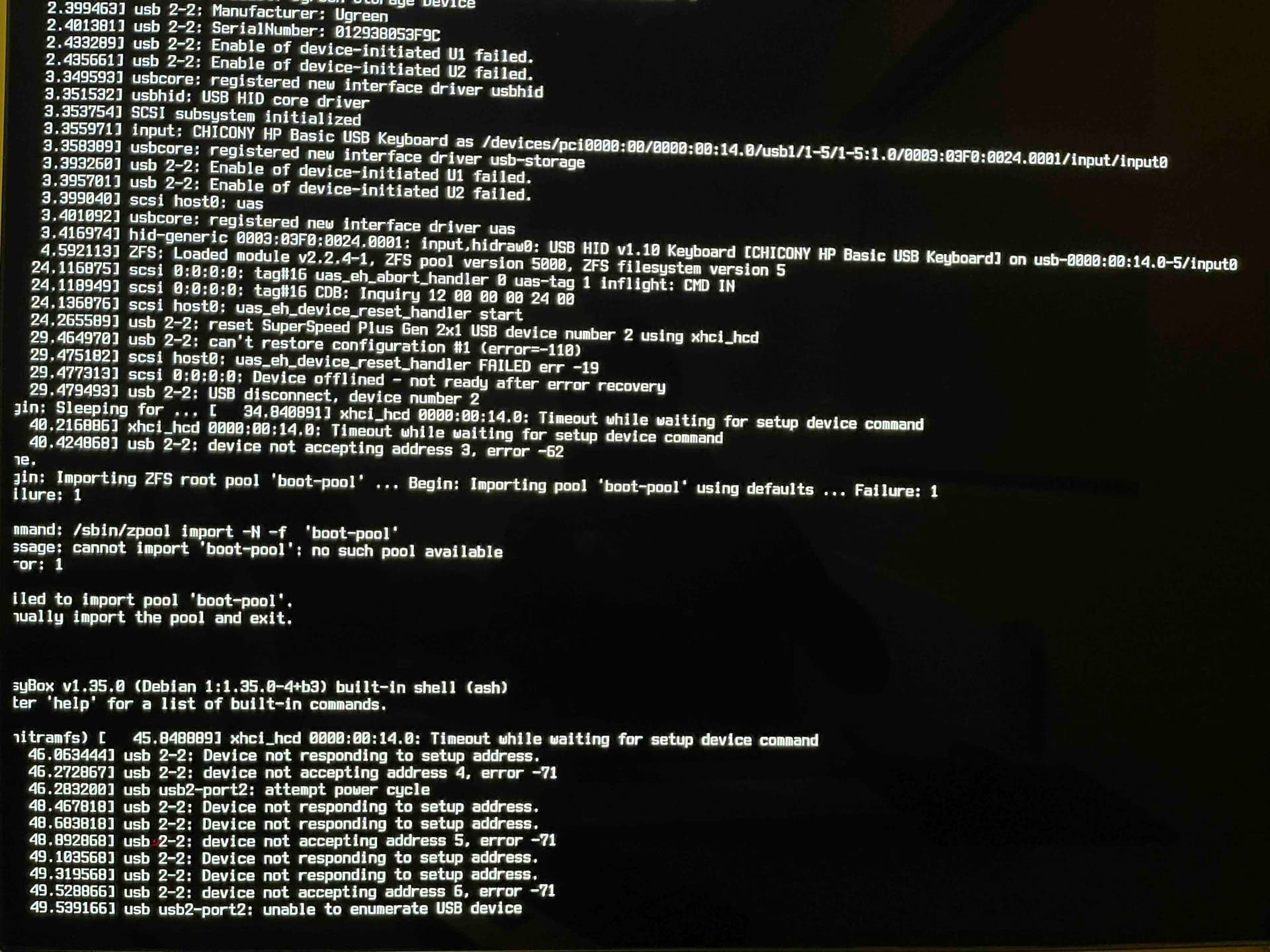
[first crash sometime Oct 18th:]
cd /var/log
sudo find . -type f | xargs sudo grep "Oct 18" | tac | sort -u -t: -k1,1
grep: ./journal/56993206fd474e34837b80dbdd2b3737/system.journal: binary file matches
grep: ./journal/56993206fd474e34837b80dbdd2b3737/system@000624d0750df85d-5ec3f7a345d87caa.journal~: binary file matches
grep: ./journal/56993206fd474e34837b80dbdd2b3737/system@3ff6f22ecd8c4d67af42c7100a83d694-0000000000004fa9-000624895da58294.journal: binary file matches
./auth.log:Oct 18 15:17:01 truenas CRON[538076]: pam_unix(cron:session): session closed for user root
./cron.log:Oct 18 15:17:01 truenas CRON[538077]: (root) CMD (cd / && run-parts --report /etc/cron.hourly)
./daemon.log:Oct 18 16:10:39 truenas systemd[1]: Finished sysstat-collect.service - system activity accounting tool.
./error:Oct 18 00:00:39 truenas systemd[1]: Failed to start logrotate.service - Rotate log files.
./messages:Oct 18 12:00:39 truenas systemd-journald[609]: /var/log/journal/56993206fd474e34837b80dbdd2b3737/system.journal: Journal header limits reached or header out-of-date, rotating.
./syslog:Oct 18 16:10:39 truenas systemd[1]: Finished sysstat-collect.service - system activity accounting tool.
[crashed again 19th night:]
./auth.log:Oct 19 22:47:01 truenas CRON[159369]: pam_unix(cron:session): session closed for user root
./cron.log:Oct 19 22:47:01 truenas CRON[159370]: (root) CMD (test -x /usr/sbin/anacron || { cd / && run-parts --report /etc/cron.weekly; })
./daemon.log:Oct 19 23:10:13 truenas systemd[1]: Finished sysstat-collect.service - system activity accounting tool.
./debug:Oct 19 01:46:35 truenas kernel: sd 0:0:0:0: [sda] Mode Sense: 37 00 00 08
./error:Oct 19 20:48:42 truenas kernel: snd_hda_intel 0000:00:1f.3: spurious response 0x0:0x0, last cmd=0x1470900
./kern.log:Oct 19 21:57:02 truenas kernel: perf: interrupt took too long (3924 > 3922), lowering kernel.perf_event_max_sample_rate to 50750
./messages:Oct 19 21:57:02 truenas kernel: perf: interrupt took too long (3924 > 3922), lowering kernel.perf_event_max_sample_rate to 50750
./syslog:Oct 19 23:10:13 truenas systemd[1]: Finished sysstat-collect.service - system activity accounting tool.
./user.log:Oct 19 08:49:34 truenas TNAUDIT_MIDDLEWARE[924]: @cee:{"TNAUDIT": {"aid": "4833b09c-3eaa-40d9-812b-b38e1c656d5b", "vers": {"major": 0, "minor": 1}, "addr": "127.0.0.1", "user": "root", "sess": "22a8c372-2e8a-4dbf-83a1-5ffef8642851", "time": "2024-10-19 15:49:34.083113", "svc": "MIDDLEWARE", "svc_data": "{\"vers\": {\"major\": 0, \"minor\": 1}, \"origin\": \"pid:66740\", \"protocol\": \"WEBSOCKET\", \"credentials\": {\"credentials\": \"UNIX_SOCKET\", \"credentials_data\": {\"username\": \"admin\"}}}", "event": "AUTHENTICATION", "event_data": "{\"credentials\": {\"credentials\": \"UNIX_SOCKET\", \"credentials_data\": {\"username\": \"admin\"}}, \"error\": null}", "success": true}}
[crashed again during an internal rsync sometime between 18:20 and 18:50 on 21st Oct]
[in reporting UI, max disk temp was 46 until metrics lost at 18:21; cpu temp was 75 shortly before, and came back at 82 before stabalising around 70 during 2nd rsync attempt]
admin@truenas[/var/log]$ sudo find . -type f | xargs sudo grep "Oct 21 18:2" | tac | sort -u -t: -k1,1
grep: ./journal/56993206fd474e34837b80dbdd2b3737/system@00062500352c263e-e991ce3dc559543c.journal~: binary file matches
grep: ./journal/56993206fd474e34837b80dbdd2b3737/system@3ff6f22ecd8c4d67af42c7100a83d694-0000000000008e56-00062500352a6315.journal: binary file matches
./auth.log:Oct 21 18:27:33 truenas sudo[889985]: pam_unix(sudo:session): session opened for user root(uid=0) by admin(uid=950)
./daemon.log:Oct 21 18:20:08 truenas systemd[1]: Finished sysstat-collect.service - system activity accounting tool.
./error:Oct 21 18:21:57 truenas sudo[887801]: admin : user not allowed to change root directory to chown ; TTY=pts/80 ; PWD=/mnt/NVMes/ix-applications/releases/plex/volumes/ix_volumes/config/Library/Application Support ; USER=root ; COMMAND=apps:apps 'Plex Media Server'
./syslog:Oct 21 18:29:58 truenas systemd[1]: run-containerd-runc-k8s.io-7698dafe5332c65a05429b531bdadde02e5eb8442b681c20e1a79fe481c00534-runc.DeJCyT.mount: Deactivated successfully.
admin@truenas[/var/log]$ sudo find . -type f | xargs sudo grep "Oct 21 18:3" | tac | sort -u -t: -k1,1
./daemon.log:Oct 21 18:30:08 truenas systemd[1]: Finished sysstat-collect.service - system activity accounting tool.
./syslog:Oct 21 18:30:18 truenas systemd[1]: run-containerd-runc-k8s.io-15b9261149aba98371554f90d4e1fe921b64f35664a3cd35608b58be3bf488c6-runc.VeUsYt.mount: Deactivated successfully.
[and again at 3:45 on the 23rd while it should have been idling, though there was a raise in CPU activity and temp shortly before]
sudo find . -type f | xargs sudo grep "Oct 23 03:" | tac | sort -u -t: -k1,1
grep: ./journal/56993206fd474e34837b80dbdd2b3737/system@0006252c94ec4d43-807848c4bdb0ea02.journal~: binary file matches
./auth.log:Oct 23 03:45:01 truenas CRON[1048347]: pam_unix(cron:session): session closed for user root
./cron.log:Oct 23 03:45:01 truenas CRON[1048350]: (root) CMD (midclt call pool.scrub.run boot-pool 7 > /dev/null 2>&1)
./daemon.log:Oct 23 03:50:00 truenas systemd[1]: Finished sysstat-collect.service - system activity accounting tool.
./syslog:Oct 23 03:51:20 truenas systemd[1]: run-containerd-runc-k8s.io-779be4f11b6a7b446d454749cb23ddf3eca4278ef3c0117f947bba8a76afde80-runc.LqjR4w.mount: Deactivated successfully.
I don’t really know what to make of the above. Do some of the log outputs suggest it’s not a sudden hardware failure, but something triggering a deliberate shutdown?
Are there other places I should be looking? What commands should I run?
Here are some other obvious issues I have, but I don’t know if they’re the cause of the actual random failures I’m concerned about, nor what to do about them:
- Due to some kind of BIOS issue I imagine, it doesn’t boot in to my USB-attached boot drive with TrueNAS on it following a software requested reboot. I have to hardware-button power cycle.
- TrueNAS alerts
'boot-pool' is consuming USB devices 'sda' which is not recommended.following every boot. (But this hardware gives me no other options; I need all 12 NVMe slots for data.) - Rarely, it gets stuck during boot apparently with some boot drive issue (just powering off and on again will make it work):