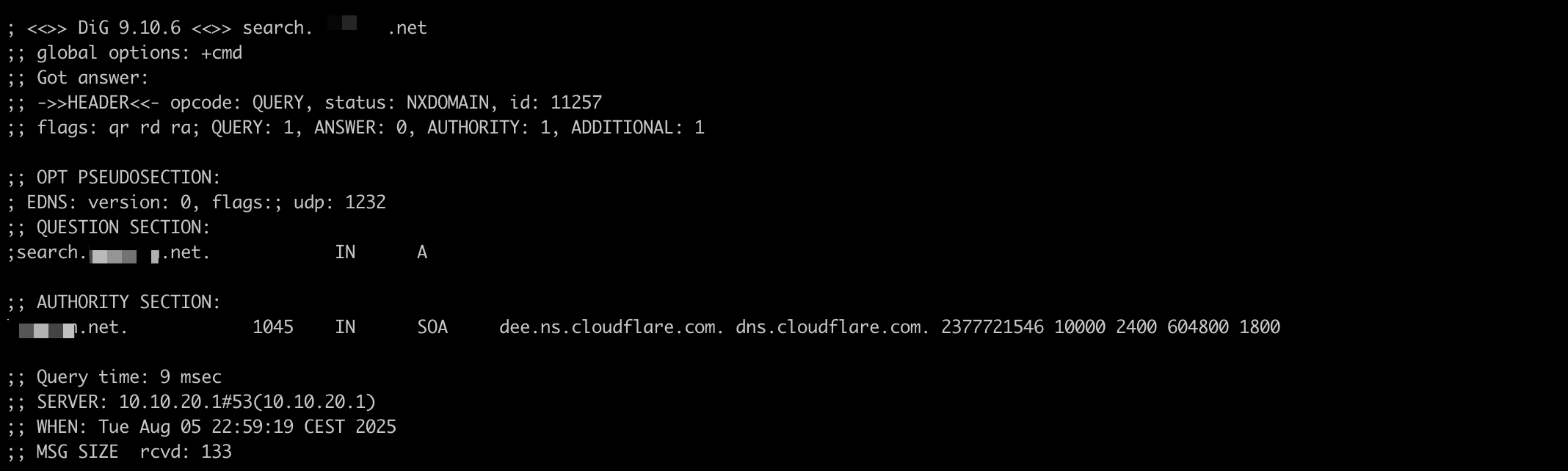
I’ve configured a wildcard entry for *..net in Adguard for 10.10.20.2, where I’ve Nginx Proxy Manager configured so that I can access my local services using a real domain name.
It works as expected 99 percent of the time, but occasionally Adguard temporarily fails to resolve a query. When I run a dig in my Mac’s terminal this is what I get.
This seems to be a persistent issue with recent versions of adguard docker image, i have issue on my generic container instance i run in my custom docker VM.
I have a non-respoding adguard node that needs to be bumped regulalry, i moved away from pihole a few years ago as it did this, shame it now happens on adguard.
All i know to do is bump the container, one of my todo’s this week is add a docker health check to do this for me each time it fails.
It has produced some interrestig failures in scripts i have and forced me to make some of mt scripts more robust in waiting for DNS to get to the working dsn.
and yes it manifests as one address especially on a my mac
so for example while it seems to happily resolve some names, others it has permanent block on one new one
so for example my mac will continue to resolve certain domains but not others, i have yet to figure out why and only for certain apps
so today my browser resolved names fine, but my termius ssh client didn’t resolve a more recent name
and it isn’t just a matter of TTL on the record, i just tested my health check (it worked yay) so now my two synced instances of adguard are working fine… and so is name resolution on the mac
its the oddest scenario - one would expect all to fail, or 1 in N to fail - but not just one new record in the upstream…
i haven’t figured out if this is the sync betweren the broken node and the good node that is causing the issue
–edit–
i think it might be realted to timeout on failed lookups and how each app chooses to handle that (wait till the OS resolver finds the good DNS server or stop trying)