I did a little side-jump from CORE to SCALE on my two systems to see what the grass was like on the other side. After all, this process is supposed to be simple and reversible, as long as the pool isn’t upgraded, etc. My main impetus was the restart-able SCALE replication service, which CORE lacks.
Basically, if CORE is interrupted while going through a replication, it has to start transferring the interrupted snapshot from scratch. SCALE keeps track of the replication, if it is interrupted, it can pick up from where the last transfer was interrupted - a huge improvement over CORE that sadly will not be back-ported.
Now, the side-grade process was relatively painless EXCEPT for SMB auxiliary parameters in CORE borking the SMB service once they got applied in SCALE. Hence a suggestion to the SCALE team: - as part of a side-grade, start with fresh SCALE SMB auxiliary parameters while informing the CORE user that they have to start over in SCALE. That way, settings that worked in CORE can be preserved if the user decides to return to CORE. Meanwhile, settings that are incompatible with SCALE won’t prevent SMB from launching.
Another quibble: it is not useful to discuss the ability to modify SMB auxiliary parameters in the SCALE GUI documentation when there is no access to the parameters via the GUI (see here). Could the team at iXsystems (@awalkerix, @Captain_Morgan , etc.) please consider correcting the documentation, perhaps drop some hints re: using CLI and service smb update smb_options="" in the shell to nuke all auxiliary parameters and then restart the SMB service?
That editorial / suggestion aside, I decided to have a little fun and see what happens re: regular file transfers. I thought I had already entered the millenium falcon with my SVDEV / record size upgrade, but SCALE takes file transfers from my laptop to the NAS to a new level. Instead of ~400 MB/s sustained transfers, Dragonfish SCALE allows large file transfers at between 600-1,000MB/s (there is some downtime between large files, see below).
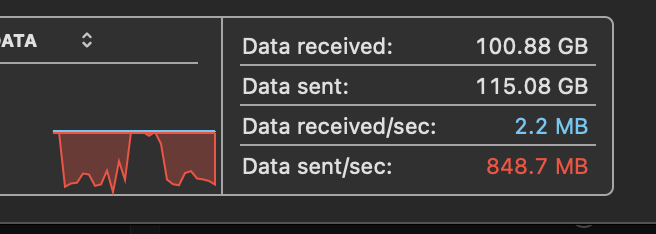
I have a feeling that I’m hitting the limits of the activity monitor on the Mac since 1080MB/s is unlikely to be possible.
BTW, the shell in SCALE is simply beautiful. Being able to cut and paste reliably is so nice. Another huge improvement: Being able to apply for SSL certificates using cloudflare and a bunch of other certificate authorities via the GUI. I thought this was coming to CORE 13.3 also? Between the faster transfers, better SSL certificate support, and the restartable replication tasks, I may stay with SCALE even if I consider the GUI menu a bit less intuitive than the CORE one…
