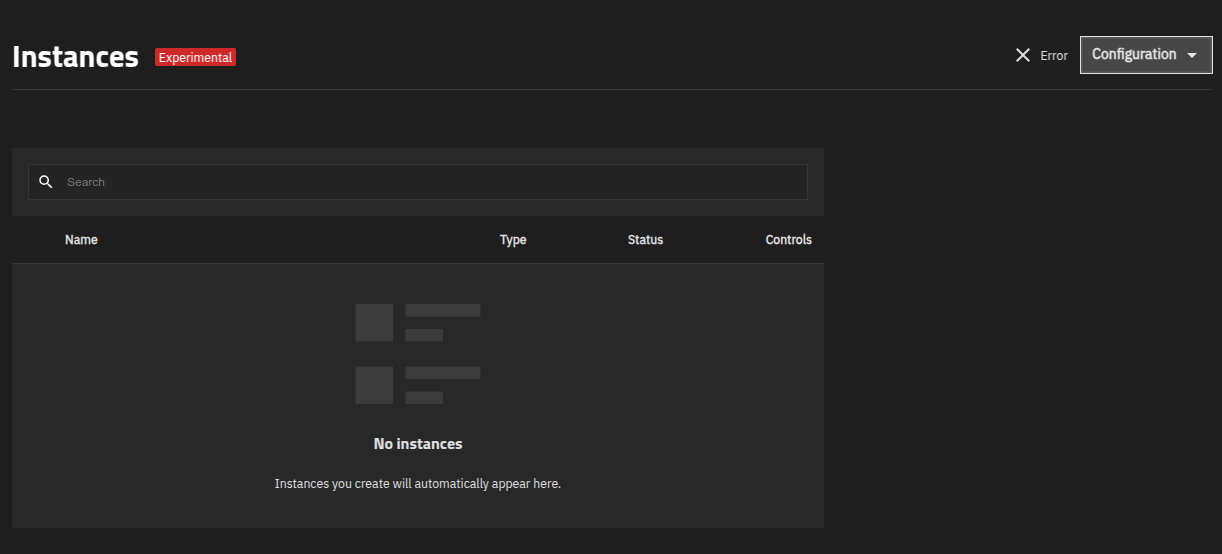
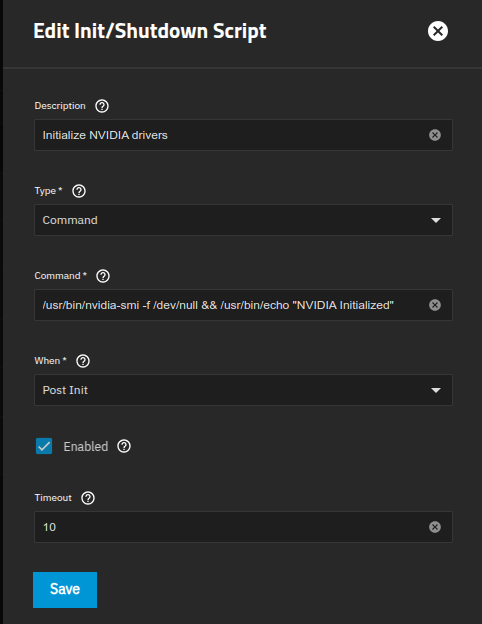
Decided to try and reboot TNCE to kick out all the cobwebs and got this from two of my instances. They just happen to be the one’s that nvidia.runtime enabled on them.
Traceback (most recent call last):
File "/usr/lib/python3/dist-packages/middlewared/job.py", line 515, in run
await self.future
File "/usr/lib/python3/dist-packages/middlewared/job.py", line 560, in __run_body
rv = await self.method(*args)
^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/plugins/virt/global.py", line 218, in setup
await self._setup_impl()
File "/usr/lib/python3/dist-packages/middlewared/plugins/virt/global.py", line 390, in _setup_impl
raise CallError(result.get('error'))
middlewared.service_exception.CallError: [EFAULT] The following instances failed to update (profile change still saved):
- Project: default, Instance: apps1: Failed to create instance update operation: Instance is busy running a "stop" operation
- Project: default, Instance: apps2: Failed to create instance update operation: Instance is busy running a "stop" operation
All other instances started without issue.
incus ls
+-------+---------+------------------------------+------+-----------+-----------+
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
+-------+---------+------------------------------+------+-----------+-----------+
| apps1 | STOPPED | | | CONTAINER | 0 |
+-------+---------+------------------------------+------+-----------+-----------+
| apps2 | STOPPED | | | CONTAINER | 0 |
+-------+---------+------------------------------+------+-----------+-----------+
| some | RUNNING | 192.168.5.4 (eth0) | | CONTAINER | 0 |
| | | 172.19.0.1 (br-17a59effbcd4) | | | |
| | | 172.18.0.1 (br-2a52f4d7eccb) | | | |
| | | 172.17.0.1 (docker0) | | | |
+-------+---------+------------------------------+------+-----------+-----------+
| dns | RUNNING | 192.168.0.8 (eth0) | | CONTAINER | 0 |
| | | 172.20.0.1 (br-5ad964b36f2a) | | | |
| | | 172.19.0.1 (br-b973de70b0e7) | | | |
| | | 172.18.0.1 (br-e3edf144ee96) | | | |
| | | 172.17.0.1 (docker0) | | | |
+-------+---------+------------------------------+------+-----------+-----------+
| mgmt | RUNNING | 192.168.0.20 (eth0) | | CONTAINER | 0 |
| | | 172.19.0.1 (br-75f5880b647f) | | | |
| | | 172.18.0.1 (br-f8e25a1bda4e) | | | |
| | | 172.17.0.1 (docker0) | | | |
+-------+---------+------------------------------+------+-----------+-----------+
| proxy | RUNNING | 192.168.0.10 (eth0) | | CONTAINER | 0 |
| | | 172.20.0.1 (br-5b3b983430b9) | | | |
| | | 172.19.0.1 (br-528a9380741f) | | | |
| | | 172.18.0.1 (br-eccb1c2fe7b9) | | | |
| | | 172.17.0.1 (docker0) | | | |
+-------+---------+------------------------------+------+-----------+-----------+
UI is borked too:
Attempting to start the instances fails…
incus start apps1
Error: Failed to run: /usr/libexec/incus/incusd forkstart apps1 /var/lib/incus/containers /run/incus/apps1/lxc.conf: exit status 1
Try `incus info --show-log apps1` for more info
and logs don’t work…
incus info --show-log apps1
Error: stat /proc/-1: no such file or directory
Restarting middlewared brings the UI back, machines still won’t start.
systemctl restart middlewared
Bug report submitted…
Workaround is a missing module which I’ll add to the docker-init-nvidia.yaml config and starting a jailmaker nvidia enabled VM.
nvidia_uvm
Need to see about running an modprobe script on boot I guess.
What’s weird is that even after boot, I can’t get those to run even with the updated kernel modules:
linux.kernel_modules: br_netfilter,drm,drm_kms_helper,nvidia,video,drm_ttm_helper,nvidia_modeset,nvidia_drm,nvidia_uvm
As soon as I start my old jailmaker jail with nvidia enabled, I can then start those jails. I need to figure out what jailmaker is doing to the system to allow them to run…