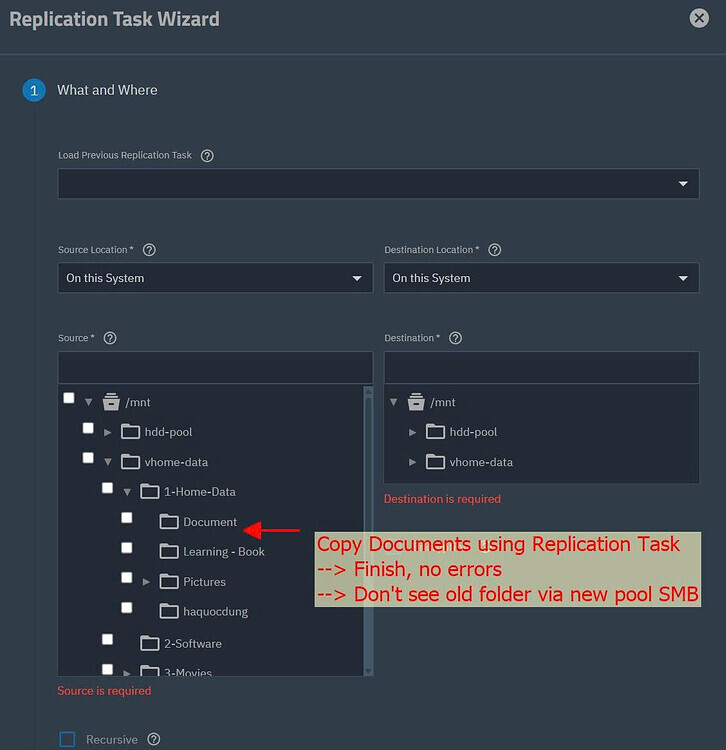
I would like to say thank you for your input in advance and sorry for lack of knowledge and bad English.
I need help with data recovery from a degraded pool: My old pool (vhome-data) that consist raidz2 with 6 disks x10tb, 2 cache in raid1, 3 caches in raid0 → I lost 1 disk due to driver failure (still keeping it), 1 disk with smart error and caches&log disk due to me being stupid pull it out. I manage to port import the pools again (via force import command) and copy the data from these disk to new pool (call hdd-pool consits 6 disks x 14tb) via Truenas Replication Tasks features. The tasks finish without any errors. However:
In the new pools, there are folders in the pool that I dont see it exits.
In the old pools, I can see this folder in the Replication Tasks features.
In the old pools, I can’t create a dataset. When creating dataset, I can tick it all the way to the folder level that I normally see in File Explorer.
Can you please help me to recover these data set?
Thank you
Last login: Thu May 29 20:27:37 +07 2025 on pts/0
root@Apollo[~]# zpool status -v
pool: boot-pool
state: ONLINE
scan: scrub repaired 0B in 00:00:14 with 0 errors on Mon May 26 03:45:15 2025
config:
NAME STATE READ WRITE CKSUM
boot-pool ONLINE 0 0 0
sde3 ONLINE 0 0 0
errors: No known data errors
pool: hdd-pool
state: ONLINE
status: One or more devices has experienced an error resulting in data
corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the
entire pool from backup.
see: Message ID: ZFS-8000-8A — OpenZFS documentation
scan: scrub repaired 92.1M in 14:26:30 with 17 errors on Wed May 28 10:29:37 2025
config:
NAME STATE READ WRITE CKSUM
hdd-pool ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
646c640d-edd6-47d4-bc47-dec0e5f61f09 ONLINE 0 0 0
771f8fd2-1501-428f-9a57-129892983331 ONLINE 0 0 0
ce879271-dc91-4b7b-a0a7-f9b06ade5bb6 ONLINE 0 0 0
raidz1-1 ONLINE 0 0 0
57875ed7-8ad3-432c-a446-59b9d175e9e2 ONLINE 0 0 0
7ec9e4d5-7d35-4614-a2f5-83c362ced35c ONLINE 0 0 0
08782374-3c40-4234-a892-87bd9420010f ONLINE 0 0 0
logs
c4303f3d-fe0a-4b48-ac1c-a984b1813cc8 ONLINE 0 0 0
errors: Permanent errors have been detected in the following files:
[List of error files]
pool: vhome-data
state: DEGRADED
status: One or more devices has experienced an error resulting in data
corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the
entire pool from backup.
see: Message ID: ZFS-8000-8A — OpenZFS documentation
scan: scrub repaired 1.91M in 17:15:40 with 23 errors on Sat Mar 15 22:57:28 2025
config:
NAME STATE READ WRITE CKSUM
vhome-data DEGRADED 0 0 0
raidz2-0 DEGRADED 0 0 0
9776424073413882555 UNAVAIL 0 0 0 was /dev/sdb2
f152ae0b-28db-481f-b173-96ee59978b83 OFFLINE 0 0 0
sdi2 ONLINE 0 0 0
sdg2 ONLINE 0 0 0
sdf2 ONLINE 0 0 0
sdh2 ONLINE 0 0 0
errors: Permanent errors have been detected in the following files:
[List of error files]
You are in an emergency situation…
Can you pull a copy of the missing data onto your client machine for temporary safe keeping?
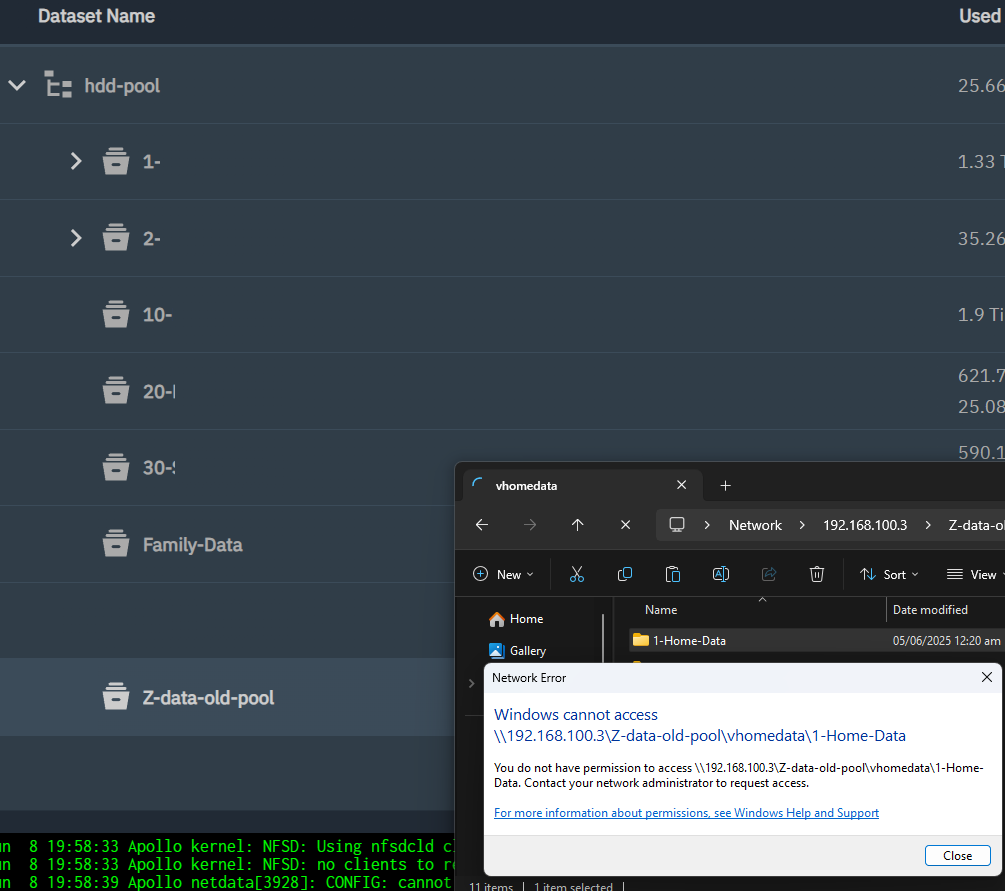
Unfortunately I can’t access these files via share smb.
Even with read-only export?
Can you rync or cloudsync them???
@Captain_Morgan I have also tried rsync and cloud sync, I got this message whenever i tried to move or do anything with old data sets/old folders.
Thanks for your suggestion.
I wonder, is the Sharing interface able to handle that space in, for example, the preceding folder name Family Studio?
I got the same errors message with upper levels folder and also dataset. Thanks for jumping in @neofusion
So it happens even if you choose to share the dataset haquocdung?
Edit:
Can you please post the output of zfs list?
What do you knowledgeable folks think about running this command:
cp -R /mnt/vhome-data /mnt/hdd-pool
It would recursively copy everything from /mnt/vhome-data to /mnt/hdd-pool, including the subdirectories.
- In the GUI, change your System Dataset to
vhome-data pool if not already accomplished.
- Now you have backed up al your data and can safely work on your old pool if you desire. I don’t know what files you need to delete on your original pool to pass a scrub, but this would be the time. Once a scrub passes, you can copy the backups of those files, assuming you have a good copy of them, to the original pool. And if you moved your System Data set, you can move it back again if you want.
- If you want to just use the new pool you created, change your SMB shares to the new pool and do all the other stuff you need to do.
This is what I would do to preserve my files. It is not the same as an Rsync but I don’t use Rsync so I have little actual knowledge about it.
@neofusion and @Captain_Morgan , how does this sound?
1 Like
Does the new “hdd-pool” hav any data?
If it does should we copy to a new dataset called “poolcopy” or something?
Why put the system dataset on the old pool?
Only if the old pool is repaired. The OP has some files to delete in order to hopefully repair the pool. If he can repair the pool then he will not have to reconfigure the SMB, any VMs, etc… At least that was my thinking. To be honest, copying the files to a safe place in my opinion is the safest thing to do, and then recover for that.
@Captain_Morgan this is why I suggest someone else provide either a thumbs up or modify the instructions. I’m just trying to help without the youngster losing data.
I think we are agreeing in principle. I’d phrase it as:
Stabilise one pool
Copy data to that pool
Move system dataset to that pool
Then fix or rebuild the second unstable pool.
2 Likes
That output is a mess… it looks like the mount points are wrong but I am not sure how to best correct them.
The UI thinks there is a pool called vhome-data, and there is but it’s not mounted as such, it’s mounted as /mnt/vhomedata, something the UI doesn’t appear to know. That out-of-sync issue is likely the reason why your attempts are failing.
Maybe exporting that pool and reimporting it to the correct name and mount point will magically fix this? I just don’t feel certain I understand the situation well enough to recommend doing that at this point.
Or maybe updating @joeschmuck’s copy command with the current mount point /mnt/vhomedata is the better call?
I’m not up on changing mount points, that is something I have never had to do. I agree that maybe trying cp -R /mnt/vhomedata /mnt/hdd-pool might work.
I’m thinking your problem is so serious that you need to copy everything and destroy the old pool, if you can. You may need to detach it, then wipe it.
Out of curiosity, did you ever crete your pools from the CLI? That use to be something that some people did, thinking they knew better, and it caused a lot of grief in the long run. That is all I can think of to explain why your pool is so messed up.
Let us know how it goes.
EDIT: If you can access those files on the old pool, you may be better off just manually copying them one directory at a time and running that through your network and connected computer. Just get the files most important to you copied first.
1 Like
@joeschmuck your copy command fix my problem! I got the data back and I check my folder. Some of the data set I can access without trouble, and saw data in my most recent update.
However, there’s a new problem for me? Can you please help? Some folders, I can access with the new pool. These folders are old dataset name.
Thank you
@joeschmuck I reset the system and has this error when try to create share again. Can you please help to check?
>
> Traceback (most recent call last):
> File "/usr/lib/python3/dist-packages/middlewared/main.py", line 211, in call_method
> result = await self.middleware.call_with_audit(message['method'], serviceobj, methodobj, params, self)
> ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
> File "/usr/lib/python3/dist-packages/middlewared/main.py", line 1529, in call_with_audit
> result = await self._call(method, serviceobj, methodobj, params, app=app,
> ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
> File "/usr/lib/python3/dist-packages/middlewared/main.py", line 1460, in _call
> return await methodobj(*prepared_call.args)
> ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
> File "/usr/lib/python3/dist-packages/middlewared/service/crud_service.py", line 230, in create
> return await self.middleware._call(
> ^^^^^^^^^^^^^^^^^^^^^^^^^^^^
> File "/usr/lib/python3/dist-packages/middlewared/main.py", line 1460, in _call
> return await methodobj(*prepared_call.args)
> ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
> File "/usr/lib/python3/dist-packages/middlewared/service/crud_service.py", line 261, in nf
> rv = await func(*args, **kwargs)
> ^^^^^^^^^^^^^^^^^^^^^^^^^^^
> File "/usr/lib/python3/dist-packages/middlewared/schema/processor.py", line 49, in nf
> res = await f(*args, **kwargs)
> ^^^^^^^^^^^^^^^^^^^^^^^^
> File "/usr/lib/python3/dist-packages/middlewared/schema/processor.py", line 179, in nf
> return await func(*args, **kwargs)
> ^^^^^^^^^^^^^^^^^^^^^^^^^^^
> File "/usr/lib/python3/dist-packages/middlewared/plugins/smb.py", line 872, in do_create
> verrors.check()
> File "/usr/lib/python3/dist-packages/middlewared/service_exception.py", line 72, in check
> raise self
> middlewared.service_exception.ValidationErrors: [EINVAL] sharingsmb_create.path_local: ACL type mismatch with child mountpoint at /mnt/hdd-pool/Z-data-old-pool/old-pool-data: hdd-pool/Z-data-old-pool - POSIX, hdd-pool/Z-data-old-pool/old-pool-data - NFSV4
I’m not the expert here, but maybe the last line has the most meaning. Maybe your permissions are incorrect.
You would be best served to rebuild your pool. Copy all your data to other drives, rebuild your pool. It is not fun but you have problems that are way beyond my understanding of ZFS and the middleware.
many thanks for the comment.
I am now able to acccess all my data when apply my ACL permission via command line.