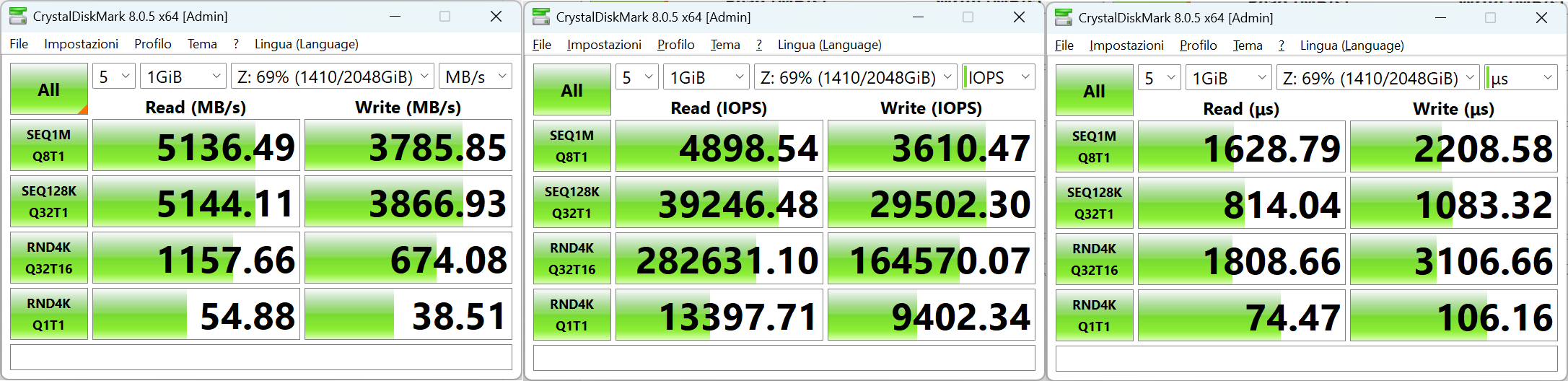
Issue: ~1.8GB/s throughput from NVMe over TCP device on linux client
Here is the setup and my testing so far:
NVMe device is a 4-wide stripe of gen3 NVMe drives. It was tested locally on an ubuntu testbench (xfs) to do around 8GB/s seq. read, 5GB/s seq. write.
Then testing locally as a ZFS stripe in my truenas system, i saw similar numbers.
When testing with fio and kdiskmark on the linux client, I seem to be limited to around 1.8GB/s. volblocksize 128k , recordsize 128k . zvol was set to inherit these values. the barryallen nvme device is using XFS on the client, and blocksize seems to have been set at 16k as I couldnt set it any higher with the mkfs.xfs tool. Though i assumed that wouldnt be the cause of such extreme performance issues?
All networking points of contact are set to 9000 MTU, and are 40Gbe links.
CPU thread usage does not seem to be the bottleneck on server or client either.
iperf3 test shows ~28Gb/s bandwidth, perhaps indicating that transferring over TCP itself is not the issue, but my implementation of NVMe over TCP?