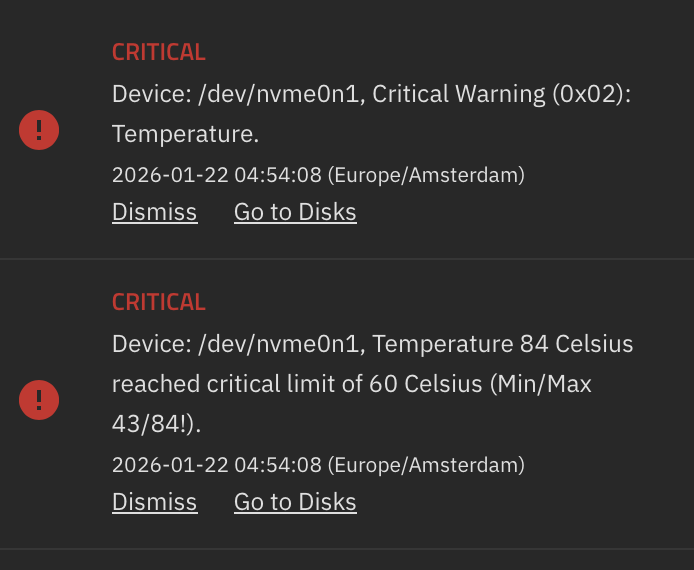
This is true. This means you are running at Power State 0.
This means that your NVMe drive does not pull much power at all.
Let me explain what you are looking at in the first line:
0 = The Power State Number
+ = This is a running power state, not a Sleep state. A- is a Sleep State.
5.24W = The maximum power consumption the drive is expected to use in this power state.
The rest of the values are how fast the drive can take to come out of this power state, into a lower power state.
I have a few things you can try and I will provide you one at a time. If I give you too much then I feel I could be setting you up for failure. Notice that I tell you to write down the time, this is only to aid in knowing when you issued a command. It helps.
First, lets run TMUX:
- Type
tmux new -s watch_temp and press enter.
- Since I really like the command @winnielinnie gave you, we will use something like it to make a few files to read later.
- Cut & Paste since this is a single command entry:
echo "Time Temperature" > /tmp/watch_temp.txt
while true; do
echo -n "$(date +%H:%M:%S) - " >> /tmp/watch_temp.txt
nvme smart-log /dev/nvme0 | grep -i temperature >> /tmp/watch_temp.txt
sleep 1
done
and press enter, it will look like it stopped working, but it is working. This will start to create a file that we can reference later.
5. Press CRTL+b then d and you should be returned to your original SSH window.
6. Type tmux new -s watch_power_state and press enter.
7. Cut & Paste since this is a single command entry:
echo "Time Power State" > /tmp/watch_power_state.txt
while true; do
echo -n "$(date +%H:%M:%S) - " >> /tmp/watch_power_state.txt
nvme get-feature /dev/nvme0 -f 2 | rev | cut -c1 >> /tmp/watch_power_state.txt
sleep 1
done
and press enter, it will look like it stopped working, but it is working. This will start to create a file that we can reference later.
8. Press CTRL+b then d to exit tmux.
Second, establish a baseline:
- Write down the time. Let your system rest for 1 minute, at least 60 full seconds. This will hopefully let you know what power state the drive is normally in.
- Write down the time. Run a scrub on your boot-pool. Type
zpool scrub boot-pool
- Wait until the scrub completes, then Type
zpool status boot-pool to verify the scrub has completed. It should take very little time as you are aware.
Third, try to set a maximum power state. This will only last until a reboot so it is not permanent. If this works, we can discuss a permanent solution. I don’t want to get ahead of ourselves.
- Write down the time. Run
nvme set-feature /dev/nvme0 -f 2 -v 2 and it should say something like this set-feature:0x02 (Power Management), value:0x00000002, cdw12:00000000, save:0
Fourth, Final test time:
- Wait about 60 seconds. Only for the heck of it.
- Run a scrub on the boot-pool
zpool scrub boot-pool and press enter.
- Wait until the scrub has completed, just as we did before.
Terminate Tmux Sessions:
- Type
tmux ls and you will show you the names of the two tmux sessions.
- Type
tmux attach -t watch_temp and you should be returned to the tmux session.
- Press
CTRL+C several times to exit the script loop.
- Once you are at a prompt Press
CTRL+b and then d to exit.
- Type
tmux kill session -t watch_temp.
- Type
tmux attach -t watch_power_state
- Press
CTRL+C several times to exit the script loop.
- Once you are at a prompt Press
CTRL+b and then d to exit.
- Type
tmux kill session -t watch_power_state.
(NOTE: You could just issue the kill commands but I prefer a controlled exit)
Collect the Data:
All your data resides in two files located in /tmp/.
- You should
cd to a directory where you want to copy the files to.
- Next
cp /tmp/watch*.* . and press enter.
Examine the data:
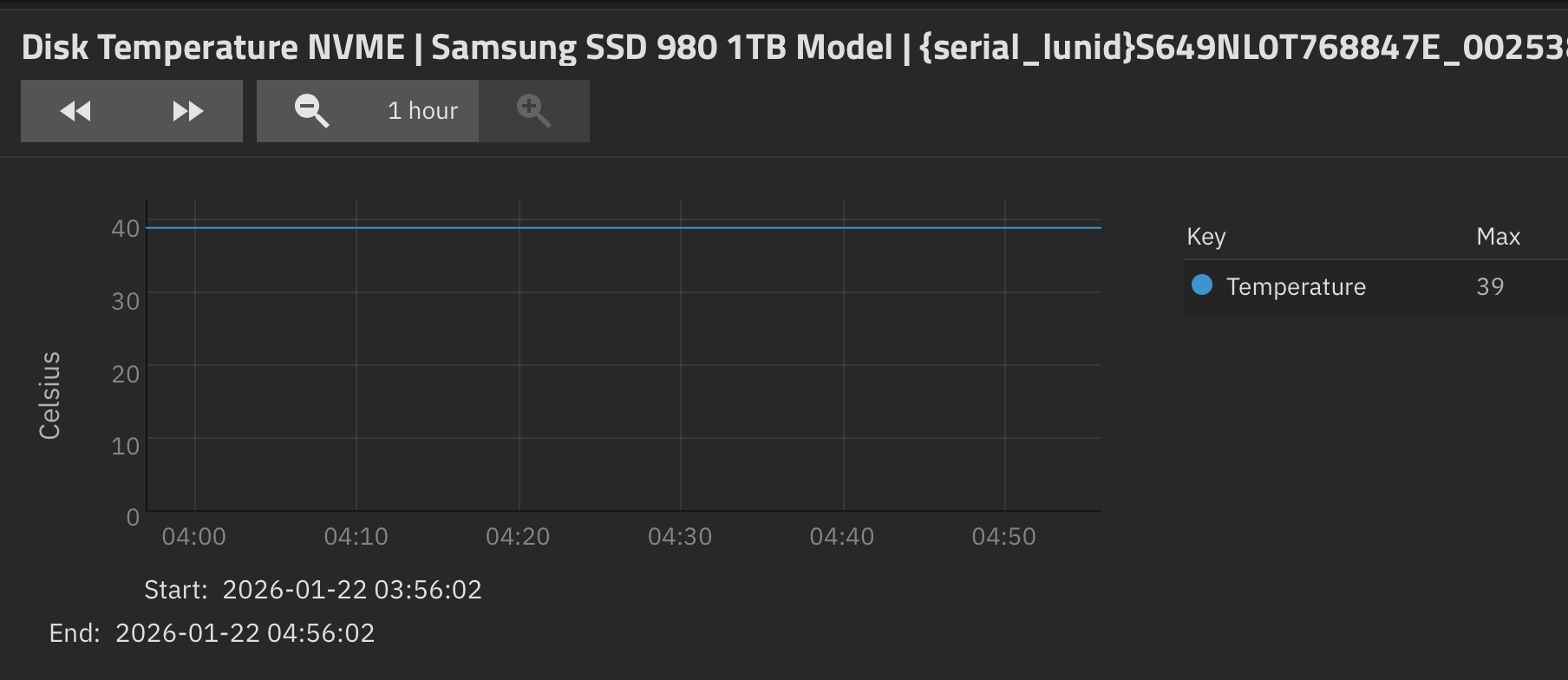
At this point you can use any simple text viewer. Each file will have a time stamp for each entry, which is why I asked you to write the time down earlier.
Locate the time stamps listed above, and analyze the data. If you are having difficulty in understanding what you are looking at, post the two files here and we can examine it.
What are you looking for?
I suspect the first Baseline will be all Power State 0. Then after you set the maximum power state to 2, that it hopefully never changes to 1 or 0, even during the last scrub.
If this works, and it depends on the NVMe drive if it will work or not, then you can simply place this into a INIT Script so it is applied each time the system bootstraps.
To set the NVMe Power level back to “0”, nvme set-feature /dev/nvme0 -f 2 -v 0 will do it vice having to reboot.
Please let me know your results.