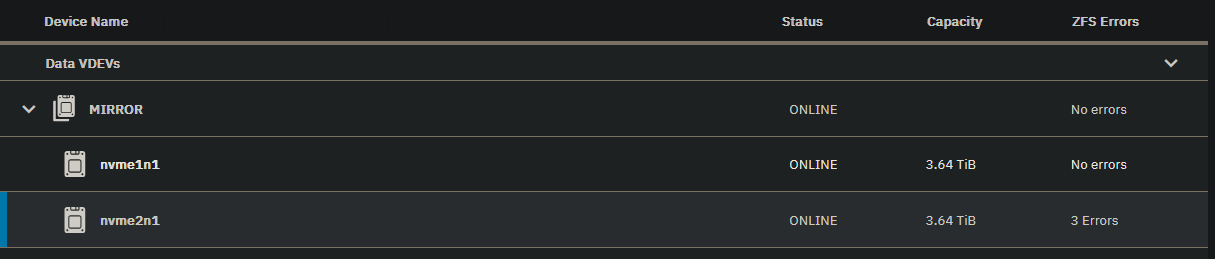
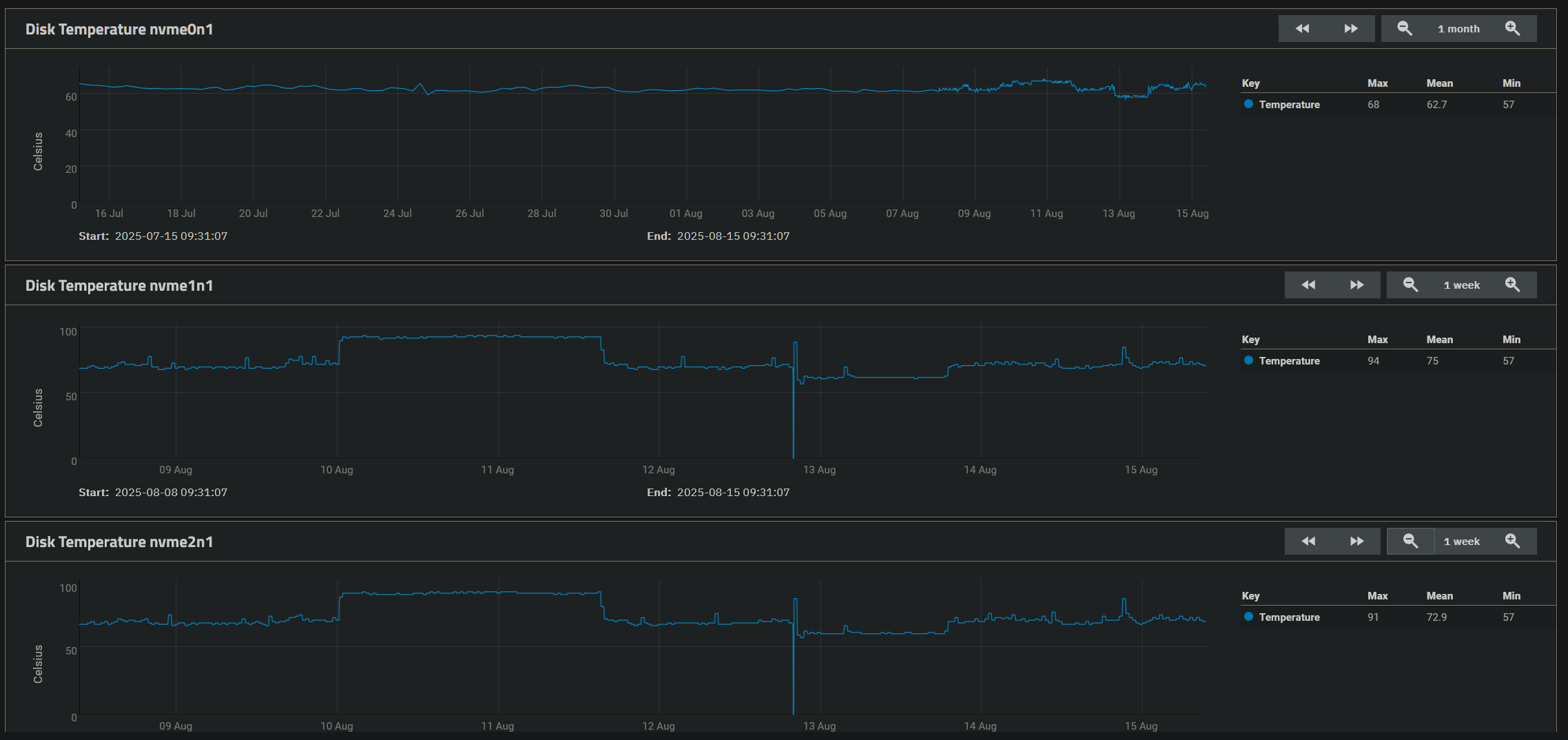
Let’s be hypothetical for a moment: You have two NVMe drives, running very hot. They are in a mirror and all is working nicely. Now the hypothetical part, one drive has a bit error, or many bit errors. This is a hardware issue. ZFS warns you of the error but it cannot fix the hardware issue. That is very oversimplified but failures happen.
The zpool output you provided does state that the error was fixed, it resilvered and fixed it for you. You still have 3 errors on the second drive.
Run zpool clear Pool and those 3 errors should clear. This only removes the count of them happening, it does not fix anything. But if you have more errors, you will be able to see that.
As for the overheated drives, @pmh had the same though as I did, limit the power level the drives can enter.
If you can’t get those temps down, odds are you will continue to have problems. That is my opinion, not a fact, but hopefully your issue.
I want to say yes but honestly it depends on the drive. There are cooler drives on the market. If you can limit the power level that the drives enter, that should let your current drives cool down quite a bit.
What is the output of smartctl -a /dev/nvme0 (Post all of it please, you can remove the drive serial number if desired)
When looking at the power states, you have a few columns of data, St=State, Op=Operational and a (+) means it runs, a (-) is a sleep state, Max is of course the amount of power the drive may consume at this level. I would try to set the drive to the lowest operational power level possible and see how the system works. Is it snappy enough, it should be. What are the drive temps. Try to get below 50C, I prefer under 40C myself, and under 30C when the system is idle. Of course if your room is 30C, that will not happen.
Post an update, I’d like to see it all work for you.