I just noticed that my TrueNAS Scale 25.04.2.6 is no longer accessible.
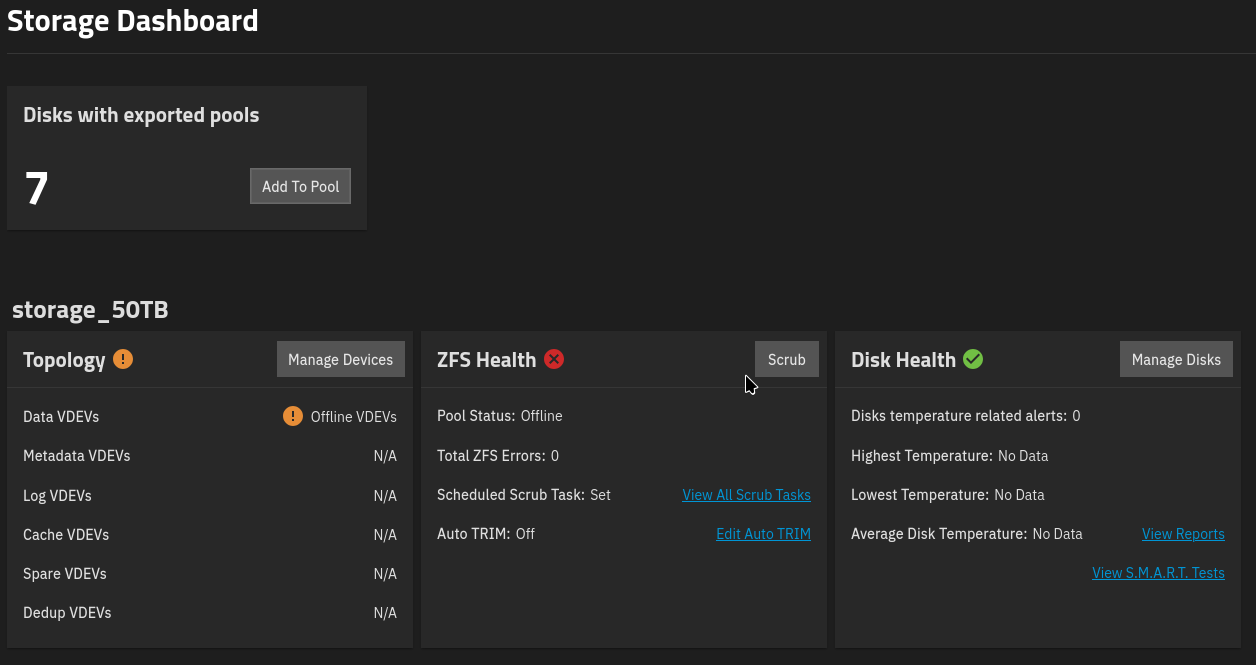
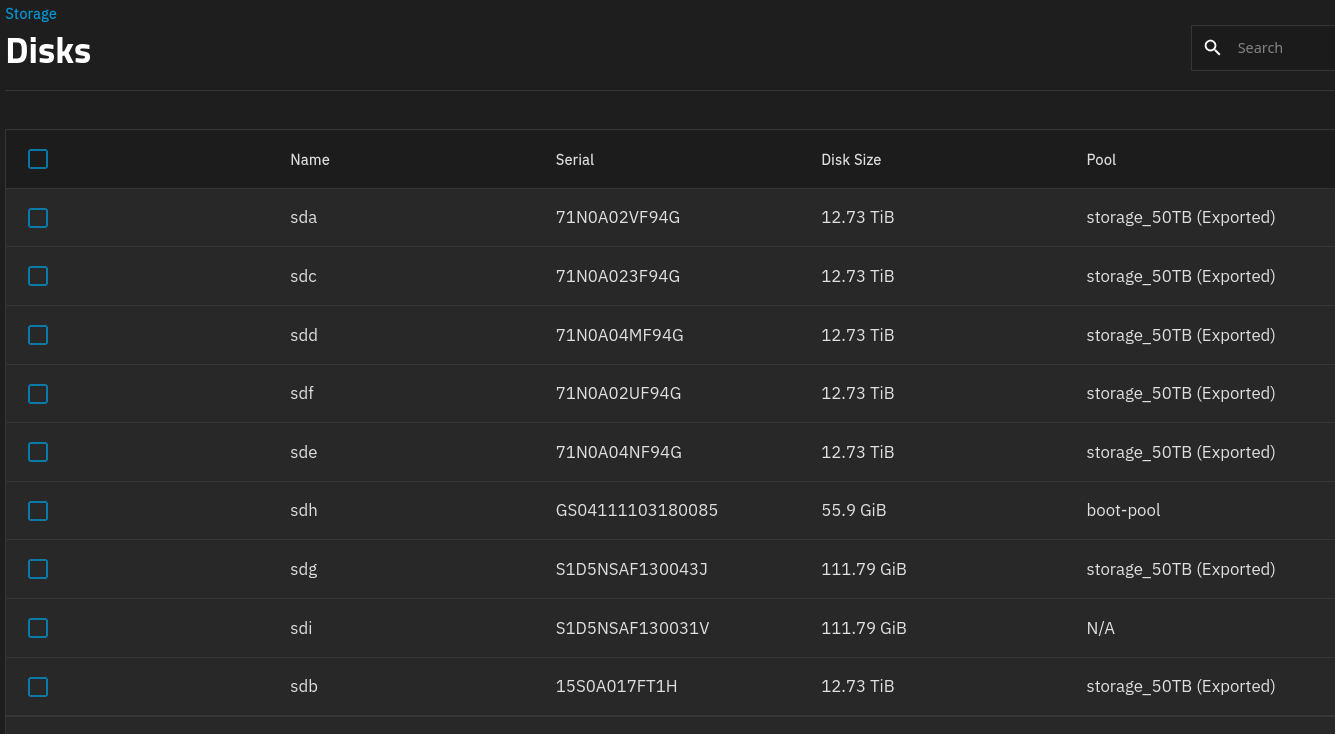
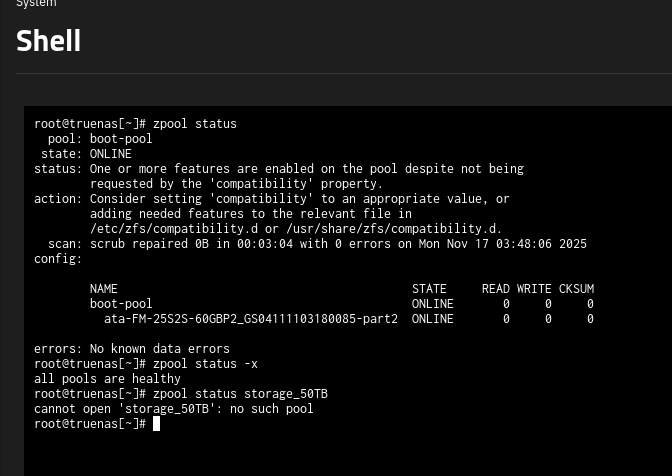
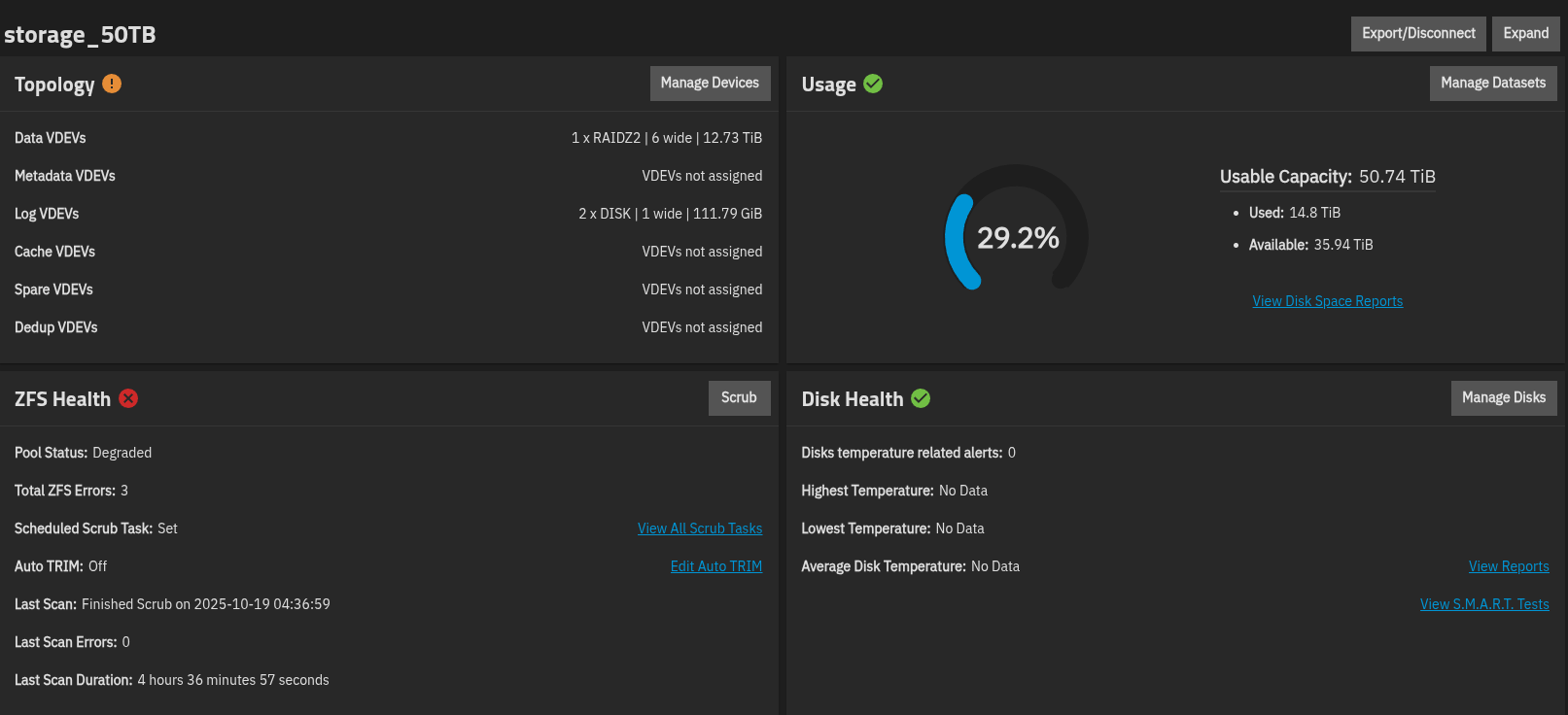
The “storage_50TB” pool is no longer displayed. All hard drives have “exported” in their names. The output of various commands can be seen in the following screenshots.
What is the best course of action now? Should I just remove the SSD? It would also be acceptable if both SSDs had to be removed, as long as the pool became accessible again.
The name of the pool does not appear in the import function, for example.
zpool import (you may copy from the shell and paste as formatted text: </> button)
and hardware details please. Is it baremetal?
If you had both a SLOG and a L2ARC, can you identify from serial numbers which one reports as N/A?
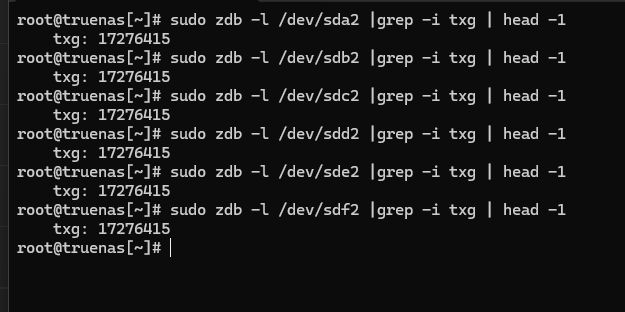
root@truenas[~]# zpool import
pool: storage_50TB
id: 1286869677993033941
state: DEGRADED
status: One or more devices are faulted.
action: The pool can be imported despite missing or damaged devices. The
fault tolerance of the pool may be compromised if imported.
config:
storage_50TB DEGRADED
raidz2-0 ONLINE
96c0907d-1972-11ec-bd42-5404a6912762 ONLINE
a952143b-6309-42f8-8df2-dc7615ac2c97 ONLINE
96e8db56-1972-11ec-bd42-5404a6912762 ONLINE
96f64b5f-1972-11ec-bd42-5404a6912762 ONLINE
9710bffa-1972-11ec-bd42-5404a6912762 ONLINE
96cf3015-1972-11ec-bd42-5404a6912762 ONLINE
logs
6c2130be-2cfa-11ec-af4d-94de80b38122 ONLINE
6c23b4e8-2cfa-11ec-af4d-94de80b38122 FAULTED too many errors
The GUI would not import a damaged pool.
So you had a striped SLOG, and one is defective. If losing up to 10 s of transactions is acceptable, you may try zpool import -m -R /mnt storage_50TB
If it works, remove the SLOG from GUI, export and reimport from GUI.
Adjust the “/dev/sdX” as needed if your server re-lettered the drives. We only want your “storage_50TB” pool. And if their is a partition for the disks, add that too.
Yes, that is good news. But, the most recent writes are thrown out. Here is the relevant manual page entry:
-F Recovery mode for a non-importable pool. Attempt to return the pool to an importable state
by discarding the last few transactions. Not all damaged pools can be recovered by using
this option. If successful, the data from the discarded transactions is irretrievably lost.
This option is ignored if the pool is importable or already imported.
The -m will throw out any synchronous writes that existed on SLOG devices. That of course can mean data loss. Not sure how ZFS acts when their are 2 independent SLOG devices, one good and one bad.
The -F will cause the pool to roll back a few write transactions / TXGs, which also causes data loss. Now if one of the SLOG devices is absolutely dead, then the pool will never import without using the -m.
Since attempting import with just -m failed, then using -F seemed like the next step.
One last note for everyone. It is my understanding that if a SLOG device fails before a crash or power loss, ZFS will resort to using in pool ZIL. (Or other SLOG if available.) So zero potential data loss.
Hmm, I wonder if their is an odd bug in ZFS when using 2 separate SLOGs, (aka not Mirrored). Perhaps the -m attempts to import without the first SLOG, (which is good). But since their is a second SLOG, (which is bad), maybe the -m didn’t process it correctly.
Ideally, ZFS would import without the bad SLOG device, but keep the good SLOG device, (and any transactions stored on it).
This is an odd corner case. A user having 2 independent SLOG devices, but not Mirrored.