Dear TrueNAS Community,
I have a 4-bay NAS (UGREEN NASync DXP4800 Plus) with 3x Seagate Ironwolf 12 TB drives in RAIDZ1 configuration + a NVME SSD as the boot drive running TrueNAS Scale (I replaced the stock UGREEN SSD). All drives are brand new and were bought from 3 different retailers to minimize potential batch issues. For couple of months now TrueNAS UI reports an issue for one of the drives with the following error messages (only couple of last messages):
End of August
Device: /dev/sdc [SAT], 2534 Offline uncorrectable sectors.
Device: /dev/sdc [SAT], ATA error count increased from 58 to 70.
Device: /dev/sdc [SAT], Self-Test Log error count increased from 5 to 6.
Device: /dev/sdc [SAT], 3416 Currently unreadable (pending) sectors.
Device: /dev/sdc [SAT], 3416 Offline uncorrectable sectors.
Beginning of September
Device: /dev/sdc [SAT], Self-Test Log error count increased from 6 to 7.
Device: /dev/sdc [SAT], new Self-Test Log error at hour timestamp 3686.
Pool #NAME# state is DEGRADED: One or more devices are faulted in response to persistent errors. Sufficient replicas exist for the pool to continue functioning in a degraded state.
The following devices are not healthy: #serial number of HDD#
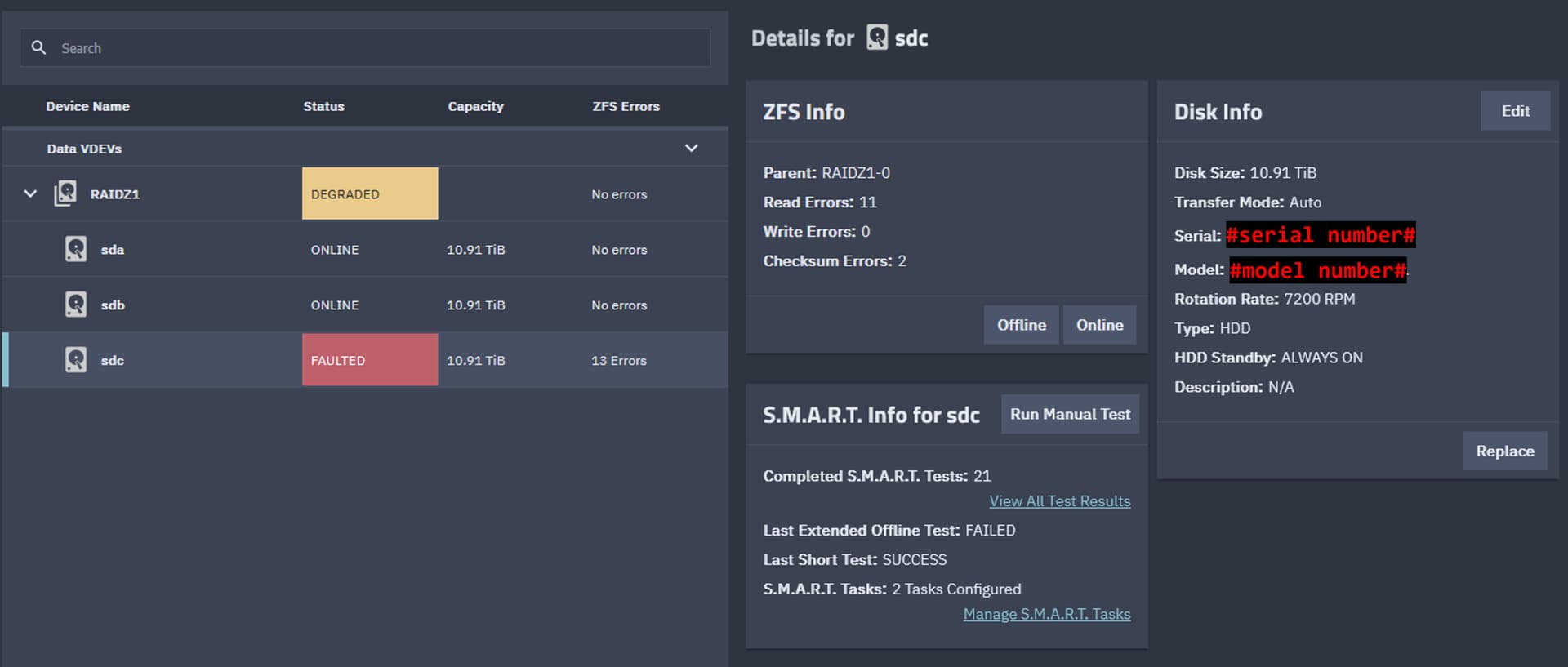
All those errors are pointing to a single HDD which I have identified based on the serial number. In the Storage tab of TrueNAS UI it tells me only Read Errors and that the Last Extended Offline Test is failed. Additionally, specifically for this drive in the ZFS Info tab I have both options “Offline” and “Online”, meanwhile for the healthy drives I only have the “Offline” option (see screenshot below).
Things I tried:
- do a manual SCRUB → nothing changed
- run a LONG SMART Test → the SMART Task is stuck at 10% at “smart.test.wait” (as time of writing for approx. 48h). I tried that multiple times in the past after restarting the system and/or aborting the SMART test without succsess
- I powered down the system and changed the position of the supposedly faulty drive to a different bay (from bay 2 to bay 4) to rule out a faulty bay connector/cable etc… After startup it instantly initiated a resilver task which supposedly was successful but the issue message is still there and the long SMART test is not finishing. I have no idea if this helped or not. This was done after the last error messages that I posted above.
I have SMART and SCRUB Tasks configured for all drives: SHORT x1/week, LONG x1/month, SCRUB x1/week.
Does anybody know if the drive is truly faulty and that I should replace it asap or might that be a software-side issue?
I appreciate any help or guidance on what to do next! I am happy to provide more data/screenshot or whatever might help but I am unfortunately not very profound with Linux shell and I rely a lot on the UI but I’ll try my best.
Thanks to everybody in advance!
Best regards
pebble
PS: I am running TrueNAS Scale 25.04.2.1