I am running TrueNAS 25.10.3.1 - Goldeye on both the source and target.
Source:
Running in Proxmox vm with HBA passthrough, RAIDZ2 8x 10TB drives (all SMR CMR), ~25TB data. 10GbE NIC
Target:
Running on bare metal, RAIDZ1 4x 14TB drives (all SMR CMR), 10GbE
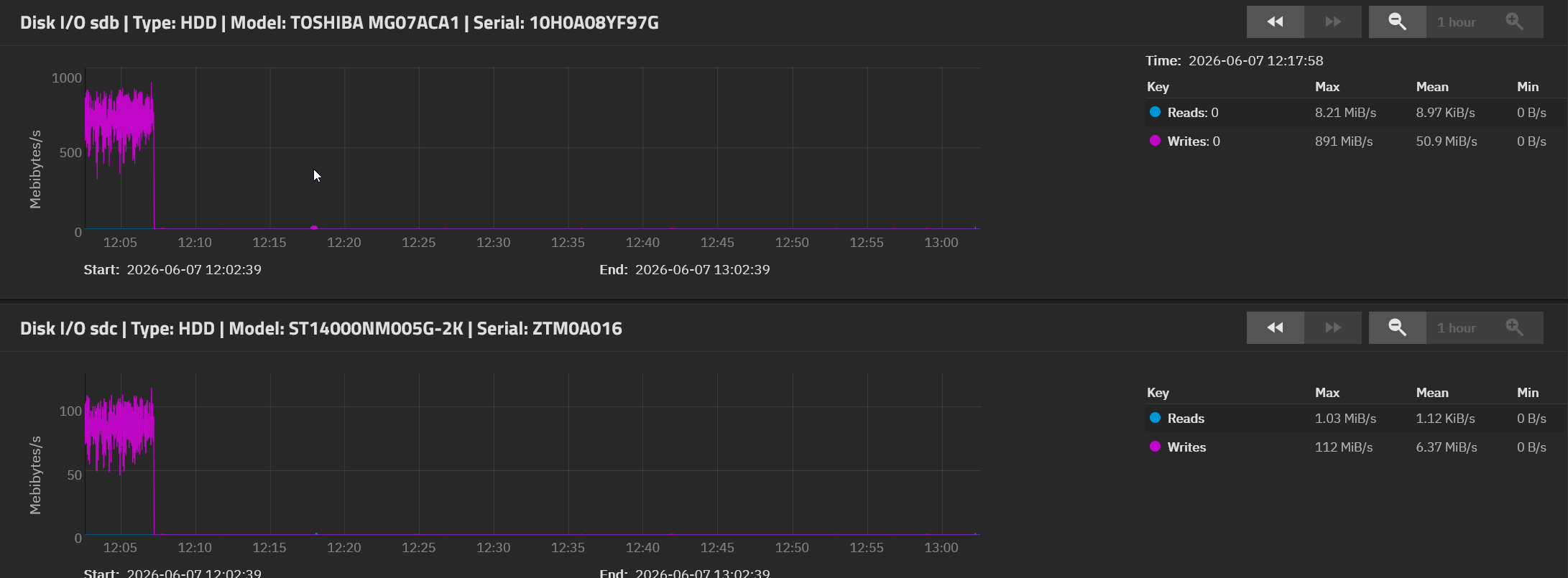
Issue: Two drives are writing on the target at ~900MiB/s and 2 are ~112MiB/s, overall transfer speed from source to target is ~2gbps. I can’t explain this.
It helps if you know what your pool layouts are capable of. Linking to pool layout whitepaper. Second link will be an article on checking performance problems. Keeping all the MB vs Mb and MiB vs MB correct can be a chore, too. Last link is if you need to post screenshots and can’t yet.
I would try checking the command line and see what is reported from the Klara Systems article. If the four drives are very similar there then it points to something with the GUI and reporting as stated above. You can try using Report a Bug in the GUI and including a Debug Dump on the target system. Including screenshots of the four disks data over a longer period may help them. At least that way it was reported with as much data as you can provide for them to attempt reproduction.
However, I have seen odd behavior that is real, yet has a simple explanation.
For example, assume both Seagate and Toshiba HDDs have a write cache, and it is enabled. Then, what if the Toshiba disks have a larger write cache on the drive, perhaps twice as large. With ZFS writing an entire stripe, (aka 4 disks in RAID-Z1), the writes fill the Seagate write cache quickly. The writes to the vDev are then throttled by the Seagate drives. Yet the Toshiba say they can handle more writes, by reporting write completion much earlier.
Could even be a case where the Seagate reports the use of a write cache and the Toshiba does not.
But, Occam’s razor says it is likely just a bug in reporting.