I’m planning to transition from CORE to SCALE once the new version is out and stable. My major concern is that there was a thread reporting data loss, which terrifies me: Pool Unavailable after upgrade from CORE 13 to SCALE 24
I’m ok losing jails and vms and my default configuration, I can recreate it manually, however I don’t want to lose any files in my pools.
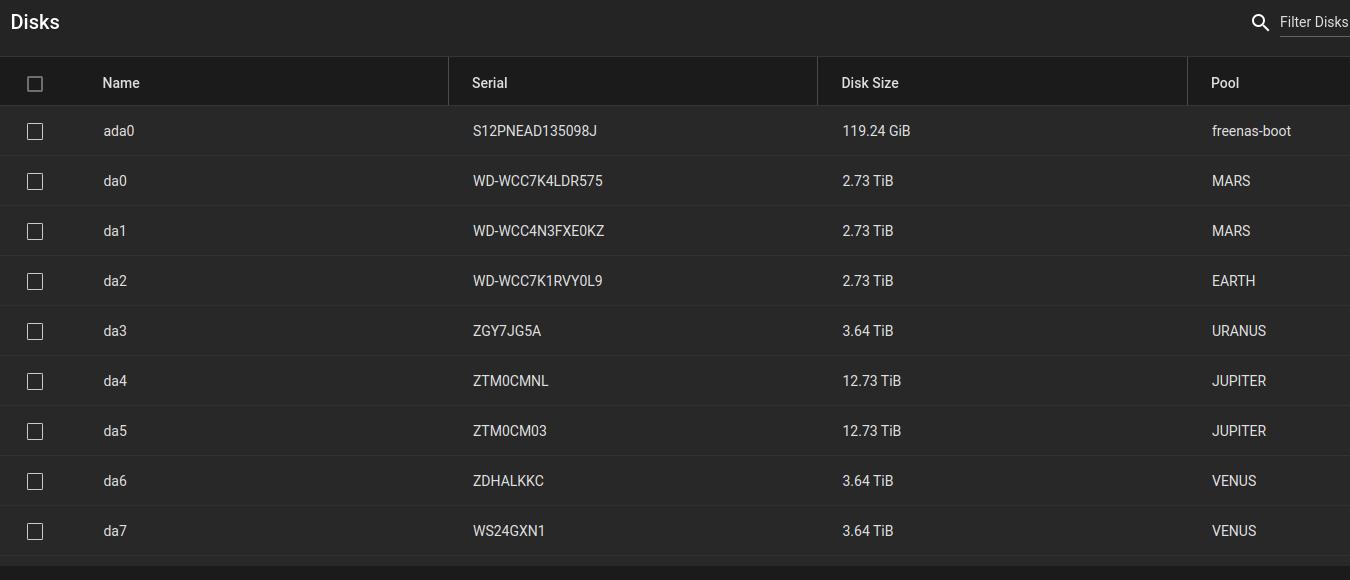
My setup is currently:
- MARS, a pool with 2 hdds, one set to mirror the other
- VENUS, a pool with 2 hdds, one set to mirror the other
- JUPITER, a pool with 2 hdds, one set to mirror the other
- URANUS, a single disk pool with data that’s ok if lost
- EARTH, a single disk pool with data that’s ok if lost
I also have 1 backup drive for MARS, VENUS, EARTH and JUPITER. The data is backed up using the UI replication task.
- What’s the safest way to upgrade to SCALE, is it doing a fresh installation on a new SSD and importing the pools safer than doing the “sidegrade”?
- If I import a pool in SCALE and things don’t workout, can I import the pool back in CORE?
- (crazy thought) Should I disconnect all the replica drives, import the pools in a degraded state in SCALE and once I verified everything is fine reconnect the replica drives?
- I will definitely use “jails” (jailmaker or sandboxes, not sure yet). Should I make a new pool, made of a single SSD, to dedicate to running software, while keeping data on HDDs?
Finally, I have a concern for my pool MARS. After a cleanup of snapshots, I ended up in a state where I cannot perform replication of auto- snapshots and francesco- snapshots, however I was able to work around it using a new naming scheme and replicating only that snapshot (francesco-fix1-). Could this be a problem once I start importing the pool in SCALE? More details about the issue are on this topic: Cannot replicate pool to brand new pool. Source pool have some problems with snapshots?
I have the option of copying all the data on MARS onto JUPITER (which is a way bigger), but I’d rather not to.