Problem/Justification
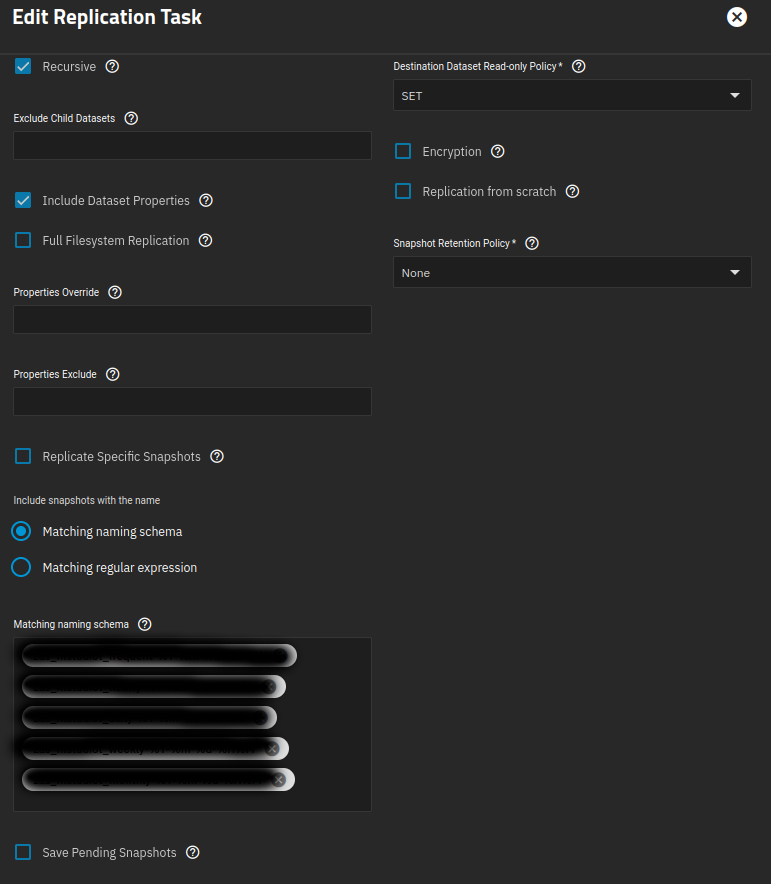
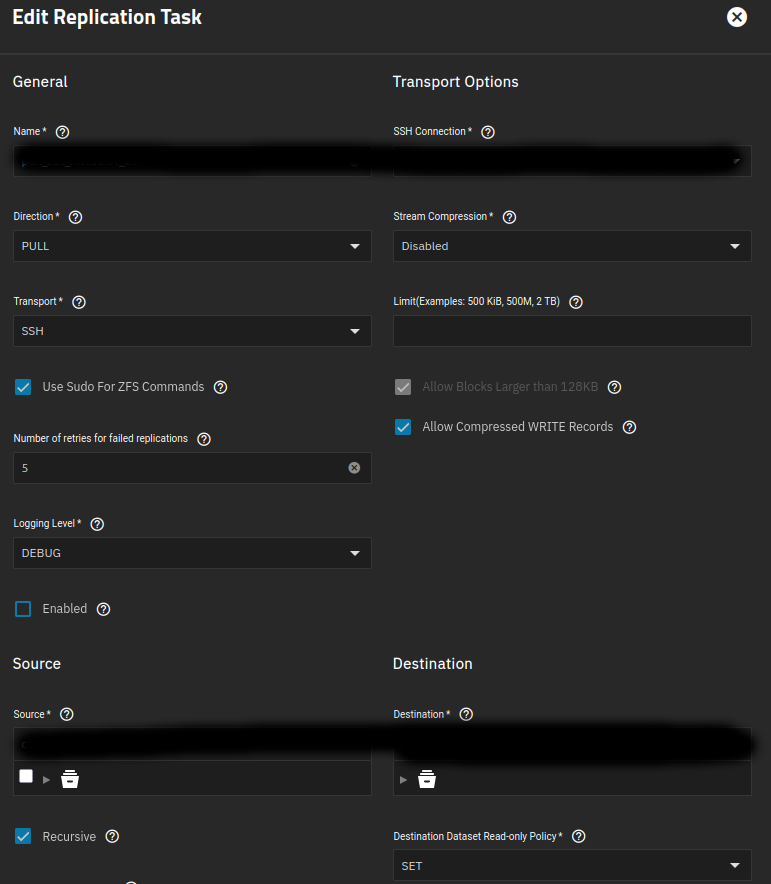
As of 24.10.2.3, I can find no way in the GUI to prevent an automated pull replication task from rolling back a destination dataset in response to an unintended source dataset rollback. If I am correct, then there is no way to use a TrueNAS replication task as a standalone backup process, rather than a sort of mirror. I doubt most users understand this. Please add a simple warning message via email and the GUI that requires a manual override in the event that a replication task that is not set to “Replication from scratch” discovers that the destination has snapshots that are newer than the source.
Impact
This will prevent an unplanned rollback at a degraded source pool from automatically destroying at the next replication event the intermediate snapshots at the destination pool that might be used to recover the source pool after the degradation at the source is addressed.
User Story
A few days ago I was transported back in time by roughly two weeks on my Ubuntu Desktop host as I sat down for my morning therapy session with ChatGPT and the like. After verifying my sanity I typed in “zpool status” and discovered a degraded pool. Closer inspection revealed that my snapshot hierarchy had been rolled back. Yea but I’m all set cuz I built myself a super duper TrueNAS fortress with replicants of all my ZFS datasets, right? Wrong. When I went to pull the latest snapshot from the vault, it was gone. Since then I’ve tried every combination of replication settings, hand waving, and special words to address this scenario with the TrueNAS GUI, to no avail.