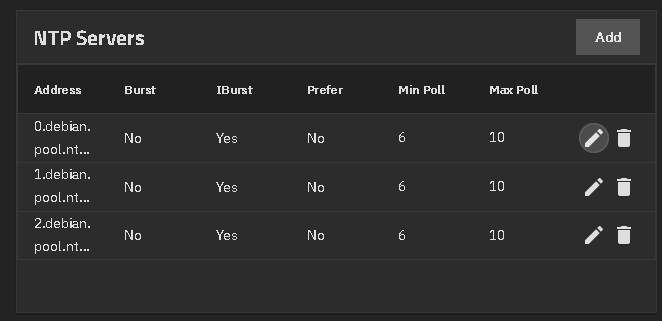
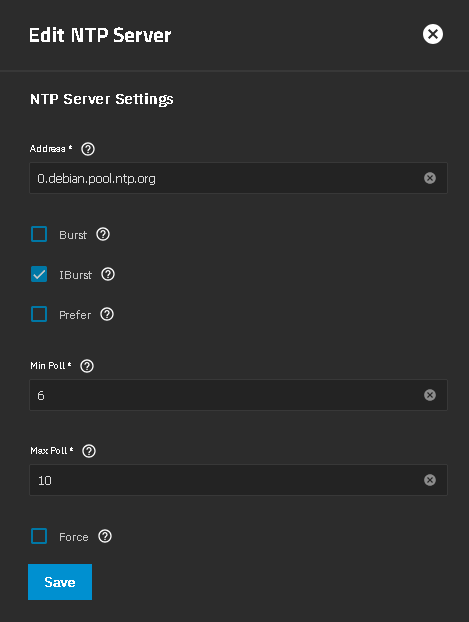
I am running TrueNAS SCALE Fangtooth 25.04 with 0.pool.ntp.org 1.pool.ntp.org and 2.pool.ntp.org as the NTP Servers. I also use rtcwake to put TrueNAS to sleep and wake at 8am.
This alert had accurred mulitple times already and it always time stamped at 8:02am
NTP health check failed - No Active NTP peers: [{‘SERVER: NOT_SELECTABLE [157.230.199.132]’}, {‘SERVER: NOT_SELECTABLE [70.116.101.97]’}, {‘SERVER: NOT_SELECTABLE [141.11.228.173]’}]
2025-07-19 08:02:23 (America/Chicago) => this is two minutes after TureNAS wake up from sleep.
Sometime I will see a clear but not always.
Any recommendation I should do next?
Would it make this less an issue if I use just one (ie. pool.ntp.org) NTP server?
Should I go back to the default NTP server? (need help on this, I forgot what I default NTP server was)
Thank you for the help in advance.
Howard
Thank you very much.
Changed back to default NTP Servers. Crossing my fingers.
Unfortunately, I received the same NTP health check failed alert again at 8:05am even using the default NTP server list.
I did timedatectl status to check. The output indicates System clock synchronized: yes, NTP service: active and RTC in local TZ: no
At this point, I believe the alert is just a transient condiction after the system woke up from sleep.
I am going to ignore it from now on. If anyone think I should dig into it further, I would appreciate your advises.
Adding my #meToo. On version TrueNAS Scale 24.10.2. Alert contents:
NTP health check failed - No Active NTP peers: [{'SERVER: SELECTABLE [162.159.200.1]'}, {'SERVER: SELECTABLE [167.248.62.201]'}, {'SERVER: SELECTABLE [2600:3c02:e000:74::123:0]'}, {'SERVER: NOT_SELECTABLE [192.168.1.218]'}]
I am trying to get it to prefer my domain controller in preference to the debian pool but maybe it’s not working right?
I am not getting any alerts that that machine is going down through host monitoring on my FingBox (I think the resolution for detection is like 5 minutes), but the alert notice and clear is usually exactly 12 hours (despite the apparent default frequency being “immediately”).
The alerts are also completely consistently, being sent at 5:26AM/PM
I’ll try adding another DC and having them talk to each other and maybe that will help availability? 
Try increasing the Min Pol and Max Pol values. Also look at Burst and IBurst tool tips. You probably have to change all lisitings

Are you also putting the server to sleep, like the OP does?
No, everything is running 24/7.
Sadly I haven’t been home during the times of “outage” and nobody complained that things weren’t working (as expected, the most egregious clock skews here are a few seconds a day and they’ll not likely care that the nas is being a bit funky)
Well it’s been a few days since adding the second domain controller to the mix and it seems all is well.
So perhaps there’s just spurious behavior where the daemon will just ignore any NTP sources that aren’t “preferred” If any are specified as preferred? That seems awkward as that kinda defeats the purpose of having extra sources that are only used in case the so-called reliable ones happen to not be available, but I’m not dug into the source code or anything so this is just speculation…
NTP health check failed - No Active NTP peers resurfaced after I upgraded to 25.04.2.4. Changing to different NTP server (debian and public) didn’t help. Anyone experience this lately?
chronyc sourrces shows everything is fine. My TrueNAS is communicating with “time.cloudflare.com” “ntpl.glypnod.com” and “23.186.168.132”. TrueNAS time and Windows PC time matches.
Should I just ignore this alert?
What is the time in the BIOS set to?
The current time in UTC or something else?
It is UTC based on what is displayed in BIOS. However, I don’t see other available settings to system date and time in the BIOS. By the way, I forgot to mention, this error accures within a minute or two after woke up from sleep. I had this happened before with version 25.04.0, then it self corrected in version 25.04.1. Verison 25.04.2.4 is showing the issue again.
I admit I have no experience putting a TrueNAS server to sleep, and not all that positive experience putting Linux and Windows systems to sleep. The outcome can sometimes be undefined.
I’m doing exactly the same and get the error when the system comes back from sleeping.
It is a bug, either by NTP not waiting a few seconds after the system comes back from sleeping, or retrying a few times before giving up.
It’s possible that they need to disable NTP before going to sleep and re-enable it when the system comes back?
It’s no big deal but the error does get sent as an alert, which is wasteful.
I have put Windows to sleep or into hibernation for years and it works well and as expected.
Please define those “unexpected” cases?
This is not that hard, the internal clock keeps the time, UTC in Linux, Local in Windows and the system simply boots, reads the time and continues.
If I were to hazard a guess it’s because the clock is slewing when asleep and chrony may or may not fix it depending on how heavily slewed it is. There’s possibly a race between the health check and when chronyd fixes it. Not really a high priority since enterprise storage never sleeps.
I agree with you, truenas-fan. It is a bug because version 25.04.0 and 25.04.2.4 but not 25.04.1 as I recall.
You are misquoting me, I said undefined.
My experience has been that sleep has a tendency to result in instability if a component (internal or external) doesn’t fully behave as the OS expects it to when power is restored. The symptoms range from components not working at all to straight up memory corruption and system wide crashes. I am not saying this always happens, just that it occurs so often that I try to avoid system sleep if I can. Linux sleep appears especially temperamental.
Since even a shutdown system still boots so quickly to not really be a bother I don’t see why I would risk it, and that’s with things like “Windows hibernation on shutdown” disabled.
The only time I frequently use system sleep is on my work laptop. Presumably that OEM has done some work validating the components with the firmware and drivers. It usually manages to successfully connect to the Dock after wake-up for example, usually.
My experience is obviously anecdotal. It’s cool that yours appears different.
I put my windows PC and Linux mint PC to sleep regularly and didn’t seem to caused any problem.
By the way, the NTP no peer alert didn’t happen on my TrueNAS system for three days already without any action from me. Hope it is healing by itself just like release 25.04.1
This area of code hasn’t been touched in probably over a year or two now. I doubt it’s an actual regression, it sounds more like a race on health checks when you’re doing suspend / resume.