As you see you see at the below,this is my big problem. Can i solve it? How?
Thx for any help.
root@freenas:~ # zpool import
pool: hmg_munka
id: 17007855792929574562
state: UNAVAIL
status: One or more devices are missing from the system.
action: The pool cannot be imported. Attach the missing
devices and try again.
config:
You have a raidz1 with two missing devices - until you’re able to reattach at least one of them, there is little we can do.
Please describe your hardware configuration as best as possible - CPU, motherboard, storage controller, drive types - as well as the events that immediately precipitated this problem - power outage or electrical surge, unexpected system shutdown, physical environment conditions (overheat) and we can attempt to determine the issue.
If you did not remove any drives, then start to look back, did you disturb the server at all? Move it, open it, change something? Two drives disappearing at the same time is not a normal failure. Or has one drive been failed for a long time and ignored and now a second drive failed? I am leaning towards the second possibility here since you are running FreeNAS 11.3. This sounds like someone setup a server and left it alone until it flat out failed. If this is the situation, please let us know so we can provide the best advice to you.
Once you have posted the requested data from above, we will have something more to examine.
We are looking for the existence of 10 drives, which includes the missing two drives.
Once we know the serial numbers of the drives listed, you can physically locate the two drives not being recognized. Maybe it was a loose power connector? It is speculation at this point.
You have a lot of good people assisting you so listen to what they are saying. if you do not understand, ask. And per Joes Rules, do not assume anything. Do not say something like “The thingy turned red” and assume we know what you are trying to convey.
One last thing… I doubt you will find many, if any, FreeNAS 11 running users here. I’m not saying you should change the version you are running, however I just wanted to be clear that most people will not have a GUI that looks like yours.
For some time, the system indicated an error, and I saw 7 hdds instead of 8 in the storage pool. Therefore, after identifying the missing disk, I shut down the system and then put a new hdd in place of the missing disk. After that, it started with the error outlined above.
Sorry if I’m in the wrong place, but this is all I could find.
And I appreciate you telling us how the problem cam about, it matters so we can help you out.
Do you still have the original failed drive? This may be needed, it is possible you replaced the wrong drive? I will hope that is what happened as it likely leads to a fairly fast recovery.
Please post the output of glabel status
This output allows us to cross reference the gptid to drive name.
Once you have this, also perform the following command for each Component in the last column of the previous command and then post the output. This can be a lengthy output so take your time.
the next command is smartctl -a /dev/XYZ where XYZ equals the letters and number before “p” in the component list. Example: the list below would use ‘/dev/da0’ and ‘/dev/ada2’, you drop the p and anything after.
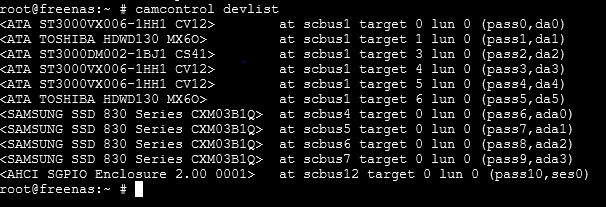
Name Status Components
gptid/74e01493-127b-11eb-85e9-000c296fd555 N/A da0p1
gptid/66431f30-d52f-11e7-ab84-0cc47ab37c5a N/A ada2p2
So, someone may be asking why am I asking for a smartctl -a vice smartctl -x and the reason is, I just want to identify the failed drives right now. Once the drives have been identified, then you can try to physically locate the failing drives using the serial number for reference. The serial number is the ONLY constant here, do not think drive “ada0” is always the same physical drive, it can change during a reboot. The serial number is what to use.
With that data we can get the serial numbers of the drives working at a minimum.
Don’t use the shell. Enable SSH and connect to the server that way. Copy/paste are among the lesser benefits of this course of action, but are still on the list.
Holy crap! 91194 hours on drive ada0. And not a single drive having a SMART test don’t on them.
Your boot drives look to be ada0 and ada1.
Your log drives are ada2 and ada3.
Your raidz1-1 drives are da2, da3 (missing two drives).
Your raidz1-2 drives are da0, da1, da4m and da5 (all accounted for)
Out of curiosity, does this produce a result other than an error? If it does, this data will help, I hope. midclt call disk.query
None of the drive data presented are from new drives, they all have serious hours on them. I think you need to describe in detail exactly what you did. Leave no detail out. Think of it as if you need to teach us how you did it. Don’t let us assume.
Do you have the drives you removed? I think you are going to need to reinstall the failed drives to get back to your previous state. If both drives failed before you replaced the first failed drive, then because you have a raidz1 configuration and lost two drives in the same vdev, the data is more than likely gone. Some recovery service might get some of the data back however that is big money.
I wish i had better news, hopefully someone else will have some better news for you. I certainly do not know it all and learn every day.
At this stage I hope you actually only had a single failed drive and that you then pulled the wrong drive (possibly because devices names like ada1, sda1 and da1 can change around every boot).
If that were to be true, you have a pulled good drive that you can put back and get back to a state with “only” a single bad drive.