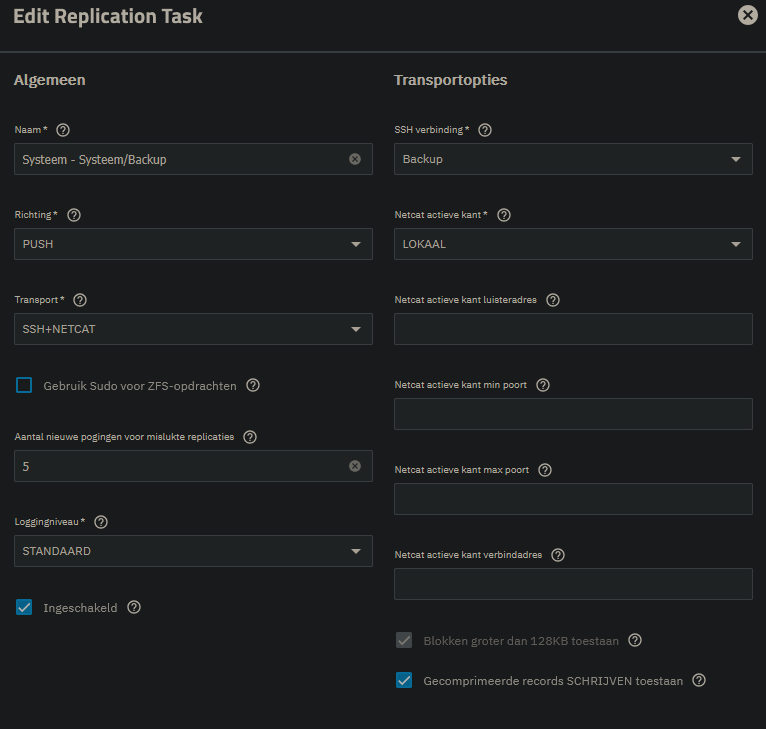
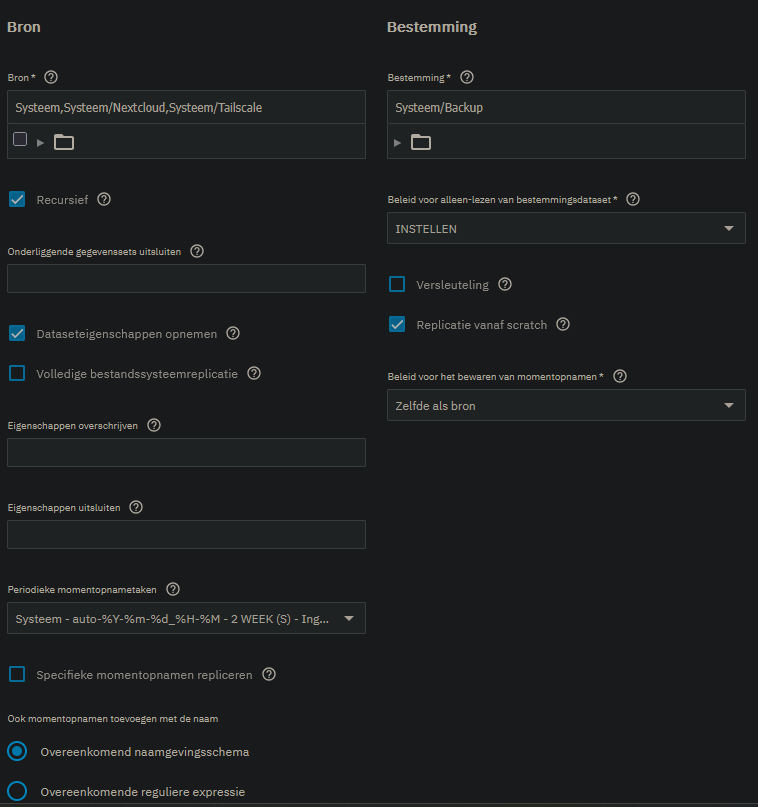
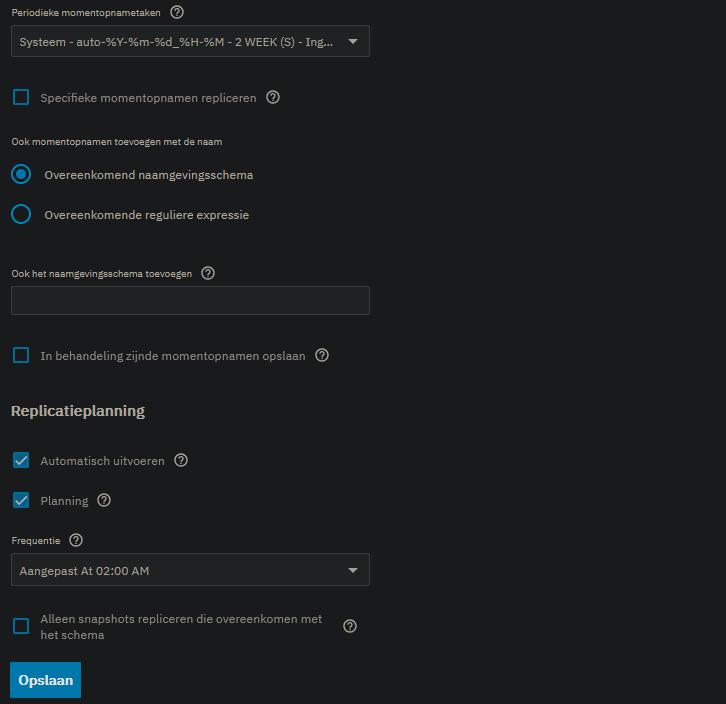
I’m on 25.10 with a remote (different physical location) system also running 25.10 for backup. My setup has Tailscale installed and connection with SSH is going fine.
However, my replication task is coming with different errors every night when it’s running. The latest problem: [EFAULT] cannot destroy ‘Systeem/Backup/Nextcloud/Userdata/%recv’: dataset is busy.
On the remote system, it looks like most of the data has landed when I look at the size of the data. But even though, every night, a different failure notification.
OK. Tried a reboot and after that a replication. Then tried shutting down Nextcloud and a replication. Every time the same failure: Replication “Systeem - Systeem/Backup” failed: cannot destroy ‘Systeem/Backup/Nextcloud/Userdata/%recv’: dataset is busy..
Read that it has to do someting with the ZFS system. How can I troubleshoot this?
Former faults were:
Replication “Systeem - Systeem/Backup” failed: Passive side: cannot receive: failed to read from stream Active side: incremental source 0x33a1f4ca8ced11f1 no longer exists..
Replication “Systeem - Systeem/Backup” failed: Unknown SSH+NETCAT transport error: ‘Must either specify --listen or --connect\n’..
And what might be important is that IU have this trouble after updating form 25.04 to 25.10. The update went flawless but the replication is a problem. Should I remove all the snapshots in order to make it work?
On the target – mb. On the source – no. At least I wouldn’t. I don’t think it will resolve your issues, though.
I’m not sure, but it can be that your snapshot has been deleted because of exceeding its lifetime (during the replication??). How did you set up your snapshot schedule?
Thank you @swc-phil for your reply. I did not tell yet that my remote system was wiped clear before installing 25.10. I had some trouble that I couldn’t solve. So the replication, when working fine, was on the 25.04 remote system.
So I started with an updated 25.10 local, and a fresh and empty 25.10 remote. Should I have made a new replication task? Because I didn’t.
I run my snapshots daily at 1 o’clock at night and the replication also daily at 2 o’clock at night. Snapshots are removed after two weeks.
I think you should not. Replication is a zfs thing, not a truenas thing. So, your target could have been not just another version of truenas, but not truenas at all.
Well, if replication has not been running for 2 weeks and then takes more than an hour (to replicate to the “expiring” snapshot), it could be the case.
TBH, according to your other errors, I don’t think that the issue is with expiring on-the-fly snapshots. Hopefully someone more experienced would help.
In the remote machine, I added a new map and send the replication to that new map. It took some time, but the replication was successful! I think the first map somehow got corrupted, though I didn’t got any signal pointing to that place, as I understood it. But maybee I misunderstood.
Fact is that I cannot destroy or remove the original map on the remote system, telling me it is still busy…