I’m hoping someone in the community would be able to help diagnose our situation.
We have two separate TrueNAS deployments, deployed exactly the same and configured the same. They both have the same amount of data being written to them and their pool / zvol / datasets are the same size.
However, on one of the deployments the snapshots are taking up over 30TiB of data, and the only way to clear it is to delete the snapshots.
These used to be running CORE, and had the issue prior to moving to SCALE.
Any ideas?
Edit: I can provide more details if that would help in identifying the issue
We’re not trying to be mean, but you really need to see it from the other person’s perspective.
Let me demonstrate. Pretend I’m the one seeking help, and you are here to offer your time to try to help me.
This is what I’m going to provide:
“I’ve enabled block-cloning and upgraded my pools but block-cloning doesn’t work. My datasets show more space is being used after I copy a bunch of files. This happened on the latest Core, and it still happens even with SCALE. I confirmed that my pools were upgraded.”
You have two separate TrueNAS SCALE systems that were upgraded from Core
You’re using snapshots
Snapshots are (supposedly) consuming over 30 TiB of space on one system, but not the other
That’s it. That’s everything I know.
I’m not even sure if these two TrueNAS instances are “related”. Is one the backup of the other?
It sounds like it. But for all I know, you’re just alluding to these two systems being “used” similarly. So perhaps they’re not related at all, nor is one a backup of the other?
Two windows servers that capture camera footage. Each server is capturing from different cameras, but they are all configured to the same format and kept for the same length of time. (They’re using the same amount of space within the server too with over 15TB free)
Two linux servers that host an elasticsearch DB
They’re connected with Block iSCSI Share Targets
The snapshots that take up space appear to be from the windows server dataset only (When clearing the snapshots for that dataset the space is freed up again)
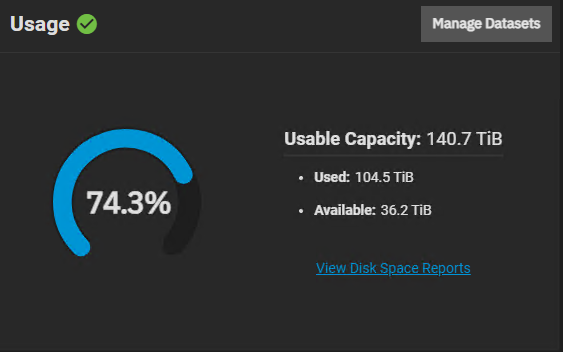
Camera footage dataset for problematic server
Used: 50.78 TiB
Available 54.51 TiB
Data Written: 32.48 TiB
Provisioning Type: Thick
Camera footage dataset for non problematic server
Used: 50.44 TiB
Available 30.73 TiB
Data Written: 42.24 TiB
Provisioning Type: Sparse
Would it be beneficial to provide the same data for the elasticsearch dataset?
Is there more that I can provide that will help? Or is it staring me in the face now with the provisioning types?
So you’re comparing apples to oranges because this is different data on possibly different pool geometries, with different provisioning for the shares.
And we still do not know where and how you’re measuring snapshot size. “Size” and “space” are complicated issues with a CoW filesystem.
Yes to both. There’s still too many unknowns compared with the disclosed, including the snapshot policies.
By the way, it seems that one of your pools is already over the “50% used” mark, which is not good with iSCSI shares.
I don’t think I am, the cameras are identical, and roughly recording the same things. I would agree if the windows disks were showing as full too and vastly different space used
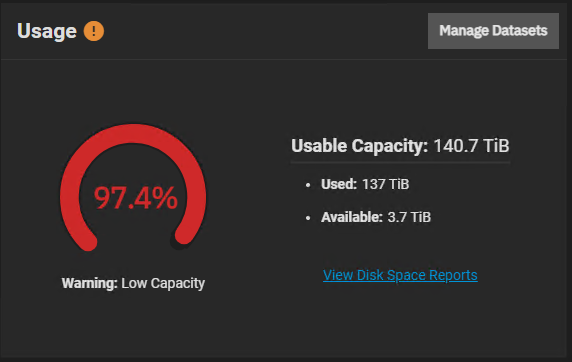
I’m using this widget, once a snaptshot of that dataset is taken, it jumps to 97%
Thank you, will take a look at this and see if we will run into any issues, the working node hasn’t had any issues for the couple years its been running.
You didn’t create sparse zvols for camera-footage-dataset and for elasticsearch-dataset on the pool server-01-pool-01.
That means you’ll always have about 102 TiB “used”, even without writing anything to the pool.
Because you did not create sparse zvols, you lose the benefits of ZFS snapshot efficiency.
I haven’t messed around with zvols (other than testing), but I believe there’s a way to safely remove the “refreservation” or reduce it to a level of the used capacity of the zvol itself.
EDIT: Don’t cameras have the ability to write video files directly into an SMB or NFS share? Why the need for zvols / iSCSI?